 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Efficient Hyperdimensional Computing Using Photonics
Nov 29, 2023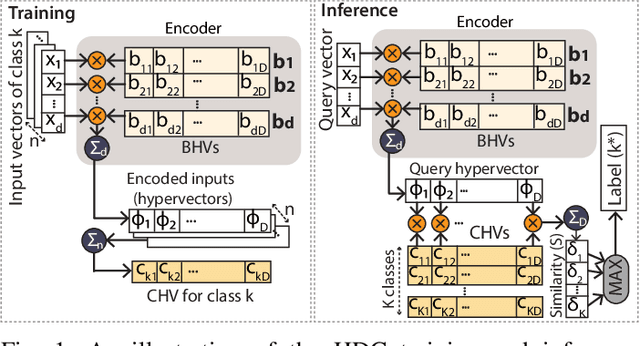
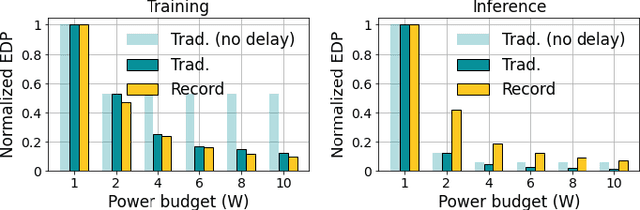
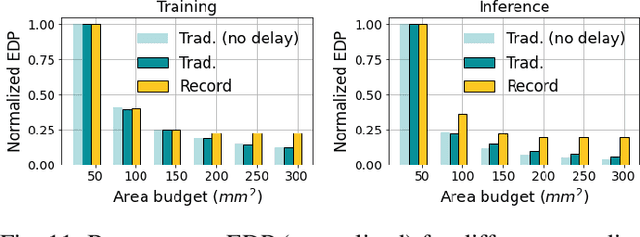
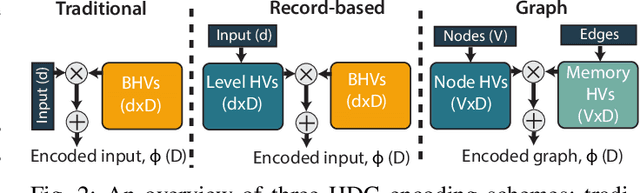
Over the past few years, silicon photonics-based computing has emerged as a promising alternative to CMOS-based computing for Deep Neural Networks (DNN). Unfortunately, the non-linear operations and the high-precision requirements of DNNs make it extremely challenging to design efficient silicon photonics-based systems for DNN inference and training. Hyperdimensional Computing (HDC) is an emerging, brain-inspired machine learning technique that enjoys several advantages over existing DNNs, including being lightweight, requiring low-precision operands, and being robust to noise introduced by the nonidealities in the hardware. For HDC, computing in-memory (CiM) approaches have been widely used, as CiM reduces the data transfer cost if the operands can fit into the memory. However, inefficient multi-bit operations, high write latency, and low endurance make CiM ill-suited for HDC. On the other hand, the existing electro-photonic DNN accelerators are inefficient for HDC because they are specifically optimized for matrix multiplication in DNNs and consume a lot of power with high-precision data converters. In this paper, we argue that photonic computing and HDC complement each other better than photonic computing and DNNs, or CiM and HDC. We propose PhotoHDC, the first-ever electro-photonic accelerator for HDC training and inference, supporting the basic, record-based, and graph encoding schemes. Evaluating with popular datasets, we show that our accelerator can achieve two to five orders of magnitude lower EDP than the state-of-the-art electro-photonic DNN accelerators for implementing HDC training and inference. PhotoHDC also achieves four orders of magnitude lower energy-delay product than CiM-based accelerators for both HDC training and inference.
Better than the Best: Gradient-based Improper Reinforcement Learning for Network Scheduling
May 01, 2021
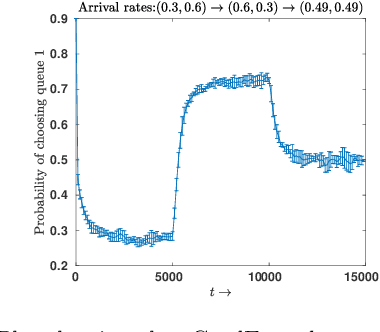
We consider the problem of scheduling in constrained queueing networks with a view to minimizing packet delay. Modern communication systems are becoming increasingly complex, and are required to handle multiple types of traffic with widely varying characteristics such as arrival rates and service times. This, coupled with the need for rapid network deployment, render a bottom up approach of first characterizing the traffic and then devising an appropriate scheduling protocol infeasible. In contrast, we formulate a top down approach to scheduling where, given an unknown network and a set of scheduling policies, we use a policy gradient based reinforcement learning algorithm that produces a scheduler that performs better than the available atomic policies. We derive convergence results and analyze finite time performance of the algorithm. Simulation results show that the algorithm performs well even when the arrival rates are nonstationary and can stabilize the system even when the constituent policies are unstable.
Explicit Best Arm Identification in Linear Bandits Using No-Regret Learners
Jun 13, 2020

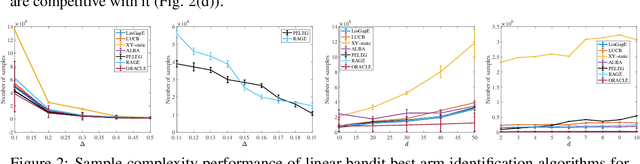
We study the problem of best arm identification in linearly parameterised multi-armed bandits. Given a set of feature vectors $\mathcal{X}\subset\mathbb{R}^d,$ a confidence parameter $\delta$ and an unknown vector $\theta^*,$ the goal is to identify $\arg\max_{x\in\mathcal{X}}x^T\theta^*$, with probability at least $1-\delta,$ using noisy measurements of the form $x^T\theta^*.$ For this fixed confidence ($\delta$-PAC) setting, we propose an explicitly implementable and provably order-optimal sample-complexity algorithm to solve this problem. Previous approaches rely on access to minimax optimization oracles. The algorithm, which we call the \textit{Phased Elimination Linear Exploration Game} (PELEG), maintains a high-probability confidence ellipsoid containing $\theta^*$ in each round and uses it to eliminate suboptimal arms in phases. PELEG achieves fast shrinkage of this confidence ellipsoid along the most confusing (i.e., close to, but not optimal) directions by interpreting the problem as a two player zero-sum game, and sequentially converging to its saddle point using low-regret learners to compute players' strategies in each round. We analyze the sample complexity of PELEG and show that it matches, up to order, an instance-dependent lower bound on sample complexity in the linear bandit setting. We also provide numerical results for the proposed algorithm consistent with its theoretical guarantees.