 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLUMION: Fast Fault Recovery for ML Jobs Using Programmable Optical Fabrics
May 29, 2025When accelerators fail in modern ML datacenters, operators migrate the affected ML training or inference jobs to entirely new racks. This approach, while preserving network performance, is highly inefficient, requiring datacenters to reserve full racks of idle accelerators for fault tolerance. In this paper, we address this resource inefficiency by introducing LUMION, a novel reconfigurable optical fabric for connecting accelerators within a datacenter rack. Instead of migrating entire ML jobs, LUMION dynamically integrates spare accelerators into ongoing workloads as failures occur, thereby maintaining consistent performance without costly migrations. We show the benefits of LUMION by building an end-to-end hardware prototype. Our experiments fine-tune Llama 3.2 and show that LUMION swaps a failed GPU with a healthy one and restarts the ML job within ~ 1 second of the failure. LUMION achieves higher inter-GPU bandwidth compared to traditional electrical racks after replacing failed accelerators with spare ones, leading to nearly 2X improvement in fine-tuning throughput.
Photonics for Sustainable Computing
Jan 10, 2024Photonic integrated circuits are finding use in a variety of applications including optical transceivers, LIDAR, bio-sensing, photonic quantum computing, and Machine Learning (ML). In particular, with the exponentially increasing sizes of ML models, photonics-based accelerators are getting special attention as a sustainable solution because they can perform ML inferences with multiple orders of magnitude higher energy efficiency than CMOS-based accelerators. However, recent studies have shown that hardware manufacturing and infrastructure contribute significantly to the carbon footprint of computing devices, even surpassing the emissions generated during their use. For example, the manufacturing process accounts for 74% of the total carbon emissions from Apple in 2019. This prompts us to ask -- if we consider both the embodied (manufacturing) and operational carbon cost of photonics, is it indeed a viable avenue for a sustainable future? So, in this paper, we build a carbon footprint model for photonic chips and investigate the sustainability of photonics-based accelerators by conducting a case study on ADEPT, a photonics-based accelerator for deep neural network inference. Our analysis shows that photonics can reduce both operational and embodied carbon footprints with its high energy efficiency and at least 4$\times$ less fabrication carbon cost per unit area than 28 nm CMOS.
Accelerating DNN Training With Photonics: A Residue Number System-Based Design
Nov 29, 2023



Photonic computing is a compelling avenue for performing highly efficient matrix multiplication, a crucial operation in Deep Neural Networks (DNNs). While this method has shown great success in DNN inference, meeting the high precision demands of DNN training proves challenging due to the precision limitations imposed by costly data converters and the analog noise inherent in photonic hardware. This paper proposes Mirage, a photonic DNN training accelerator that overcomes the precision challenges in photonic hardware using the Residue Number System (RNS). RNS is a numeral system based on modular arithmetic$\unicode{x2014}$allowing us to perform high-precision operations via multiple low-precision modular operations. In this work, we present a novel micro-architecture and dataflow for an RNS-based photonic tensor core performing modular arithmetic in the analog domain. By combining RNS and photonics, Mirage provides high energy efficiency without compromising precision and can successfully train state-of-the-art DNNs achieving accuracy comparable to FP32 training. Our study shows that on average across several DNNs when compared to systolic arrays, Mirage achieves more than $23.8\times$ faster training and $32.1\times$ lower EDP in an iso-energy scenario and consumes $42.8\times$ lower power with comparable or better EDP in an iso-area scenario.
Towards Efficient Hyperdimensional Computing Using Photonics
Nov 29, 2023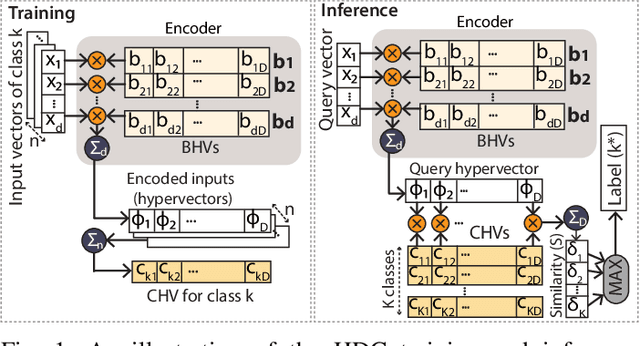
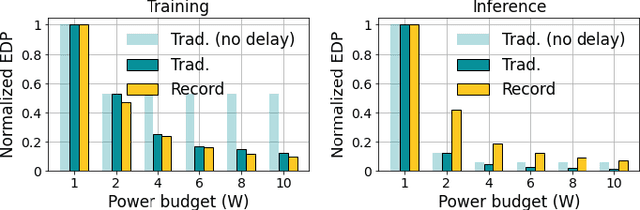
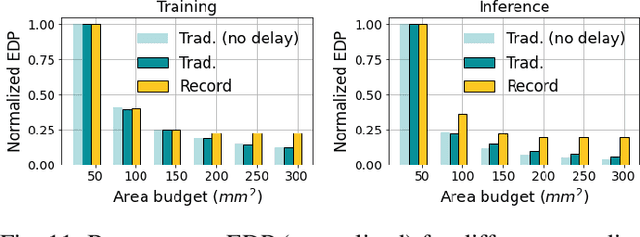
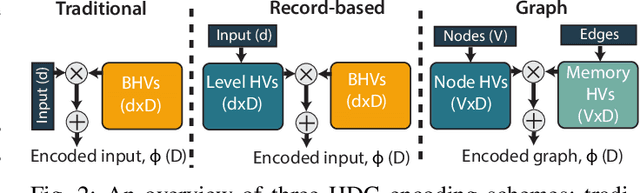
Over the past few years, silicon photonics-based computing has emerged as a promising alternative to CMOS-based computing for Deep Neural Networks (DNN). Unfortunately, the non-linear operations and the high-precision requirements of DNNs make it extremely challenging to design efficient silicon photonics-based systems for DNN inference and training. Hyperdimensional Computing (HDC) is an emerging, brain-inspired machine learning technique that enjoys several advantages over existing DNNs, including being lightweight, requiring low-precision operands, and being robust to noise introduced by the nonidealities in the hardware. For HDC, computing in-memory (CiM) approaches have been widely used, as CiM reduces the data transfer cost if the operands can fit into the memory. However, inefficient multi-bit operations, high write latency, and low endurance make CiM ill-suited for HDC. On the other hand, the existing electro-photonic DNN accelerators are inefficient for HDC because they are specifically optimized for matrix multiplication in DNNs and consume a lot of power with high-precision data converters. In this paper, we argue that photonic computing and HDC complement each other better than photonic computing and DNNs, or CiM and HDC. We propose PhotoHDC, the first-ever electro-photonic accelerator for HDC training and inference, supporting the basic, record-based, and graph encoding schemes. Evaluating with popular datasets, we show that our accelerator can achieve two to five orders of magnitude lower EDP than the state-of-the-art electro-photonic DNN accelerators for implementing HDC training and inference. PhotoHDC also achieves four orders of magnitude lower energy-delay product than CiM-based accelerators for both HDC training and inference.
Photonic Accelerators for Image Segmentation in Autonomous Driving and Defect Detection
Oct 03, 2023



Photonic computing promises faster and more energy-efficient deep neural network (DNN) inference than traditional digital hardware. Advances in photonic computing can have profound impacts on applications such as autonomous driving and defect detection that depend on fast, accurate and energy efficient execution of image segmentation models. In this paper, we investigate image segmentation on photonic accelerators to explore: a) the types of image segmentation DNN architectures that are best suited for photonic accelerators, and b) the throughput and energy efficiency of executing the different image segmentation models on photonic accelerators, along with the trade-offs involved therein. Specifically, we demonstrate that certain segmentation models exhibit negligible loss in accuracy (compared to digital float32 models) when executed on photonic accelerators, and explore the empirical reasoning for their robustness. We also discuss techniques for recovering accuracy in the case of models that do not perform well. Further, we compare throughput (inferences-per-second) and energy consumption estimates for different image segmentation workloads on photonic accelerators. We discuss the challenges and potential optimizations that can help improve the application of photonic accelerators to such computer vision tasks.
A Blueprint for Precise and Fault-Tolerant Analog Neural Networks
Sep 19, 2023Analog computing has reemerged as a promising avenue for accelerating deep neural networks (DNNs) due to its potential to overcome the energy efficiency and scalability challenges posed by traditional digital architectures. However, achieving high precision and DNN accuracy using such technologies is challenging, as high-precision data converters are costly and impractical. In this paper, we address this challenge by using the residue number system (RNS). RNS allows composing high-precision operations from multiple low-precision operations, thereby eliminating the information loss caused by the limited precision of the data converters. Our study demonstrates that analog accelerators utilizing the RNS-based approach can achieve ${\geq}99\%$ of FP32 accuracy for state-of-the-art DNN inference using data converters with only $6$-bit precision whereas a conventional analog core requires more than $8$-bit precision to achieve the same accuracy in the same DNNs. The reduced precision requirements imply that using RNS can reduce the energy consumption of analog accelerators by several orders of magnitude while maintaining the same throughput and precision. Our study extends this approach to DNN training, where we can efficiently train DNNs using $7$-bit integer arithmetic while achieving accuracy comparable to FP32 precision. Lastly, we present a fault-tolerant dataflow using redundant RNS error-correcting codes to protect the computation against noise and errors inherent within an analog accelerator.
INT-FP-QSim: Mixed Precision and Formats For Large Language Models and Vision Transformers
Jul 07, 2023The recent rise of large language models (LLMs) has resulted in increased efforts towards running LLMs at reduced precision. Running LLMs at lower precision supports resource constraints and furthers their democratization, enabling users to run billion-parameter LLMs on their personal devices. To supplement this ongoing effort, we propose INT-FP-QSim: an open-source simulator that enables flexible evaluation of LLMs and vision transformers at various numerical precisions and formats. INT-FP-QSim leverages existing open-source repositories such as TensorRT, QPytorch and AIMET for a combined simulator that supports various floating point and integer formats. With the help of our simulator, we survey the impact of different numerical formats on the performance of LLMs and vision transformers at 4-bit weights and 4-bit or 8-bit activations. We also compare recently proposed methods like Adaptive Block Floating Point, SmoothQuant, GPTQ and RPTQ on the model performances. We hope INT-FP-QSim will enable researchers to flexibly simulate models at various precisions to support further research in quantization of LLMs and vision transformers.
Leveraging Residue Number System for Designing High-Precision Analog Deep Neural Network Accelerators
Jun 15, 2023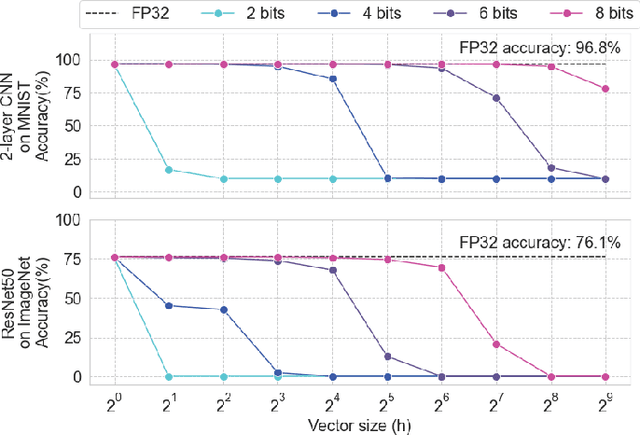
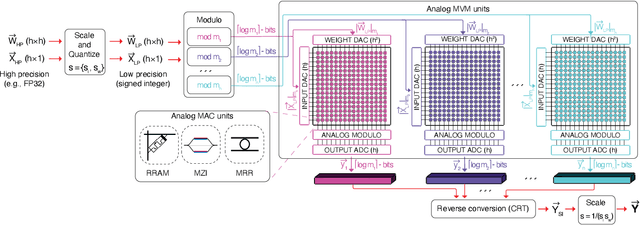
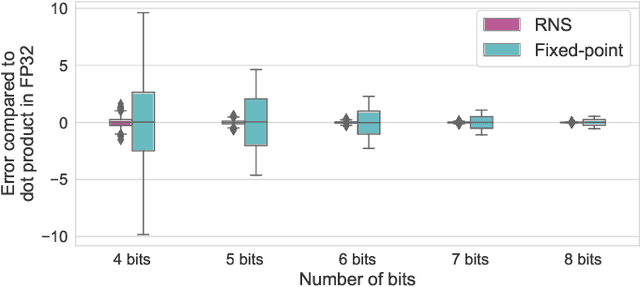
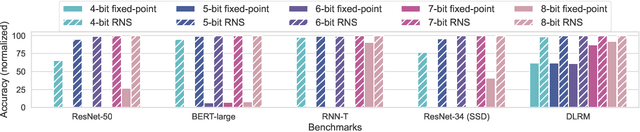
Achieving high accuracy, while maintaining good energy efficiency, in analog DNN accelerators is challenging as high-precision data converters are expensive. In this paper, we overcome this challenge by using the residue number system (RNS) to compose high-precision operations from multiple low-precision operations. This enables us to eliminate the information loss caused by the limited precision of the ADCs. Our study shows that RNS can achieve 99% FP32 accuracy for state-of-the-art DNN inference using data converters with only $6$-bit precision. We propose using redundant RNS to achieve a fault-tolerant analog accelerator. In addition, we show that RNS can reduce the energy consumption of the data converters within an analog accelerator by several orders of magnitude compared to a regular fixed-point approach.
Sensitivity-Aware Finetuning for Accuracy Recovery on Deep Learning Hardware
Jun 05, 2023Existing methods to recover model accuracy on analog-digital hardware in the presence of quantization and analog noise include noise-injection training. However, it can be slow in practice, incurring high computational costs, even when starting from pretrained models. We introduce the Sensitivity-Aware Finetuning (SAFT) approach that identifies noise sensitive layers in a model, and uses the information to freeze specific layers for noise-injection training. Our results show that SAFT achieves comparable accuracy to noise-injection training and is 2x to 8x faster.
Adaptive Block Floating-Point for Analog Deep Learning Hardware
May 12, 2022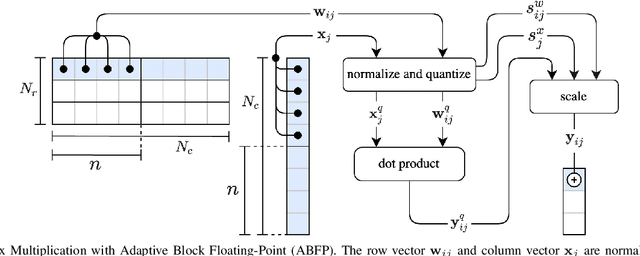

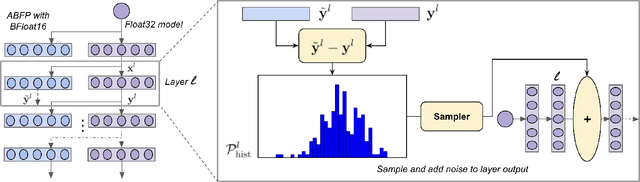
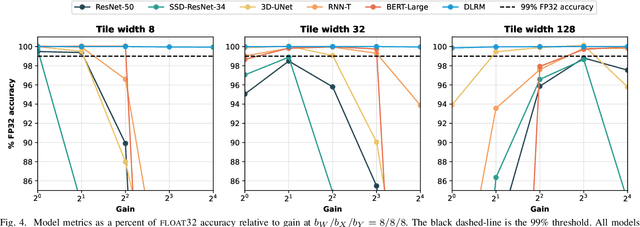
Analog mixed-signal (AMS) devices promise faster, more energy-efficient deep neural network (DNN) inference than their digital counterparts. However, recent studies show that DNNs on AMS devices with fixed-point numbers can incur an accuracy penalty because of precision loss. To mitigate this penalty, we present a novel AMS-compatible adaptive block floating-point (ABFP) number representation. We also introduce amplification (or gain) as a method for increasing the accuracy of the number representation without increasing the bit precision of the output. We evaluate the effectiveness of ABFP on the DNNs in the MLPerf datacenter inference benchmark -- realizing less than $1\%$ loss in accuracy compared to FLOAT32. We also propose a novel method of finetuning for AMS devices, Differential Noise Finetuning (DNF), which samples device noise to speed up finetuning compared to conventional Quantization-Aware Training.