 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEidetic Learning: an Efficient and Provable Solution to Catastrophic Forgetting
Feb 13, 2025



Catastrophic forgetting -- the phenomenon of a neural network learning a task t1 and losing the ability to perform it after being trained on some other task t2 -- is a long-standing problem for neural networks [McCloskey and Cohen, 1989]. We present a method, Eidetic Learning, that provably solves catastrophic forgetting. A network trained with Eidetic Learning -- here, an EideticNet -- requires no rehearsal or replay. We consider successive discrete tasks and show how at inference time an EideticNet automatically routes new instances without auxiliary task information. An EideticNet bears a family resemblance to the sparsely-gated Mixture-of-Experts layer Shazeer et al. [2016] in that network capacity is partitioned across tasks and the network itself performs data-conditional routing. An EideticNet is easy to implement and train, is efficient, and has time and space complexity linear in the number of parameters. The guarantee of our method holds for normalization layers of modern neural networks during both pre-training and fine-tuning. We show with a variety of network architectures and sets of tasks that EideticNets are immune to forgetting. While the practical benefits of EideticNets are substantial, we believe they can be benefit practitioners and theorists alike. The code for training EideticNets is available at \href{https://github.com/amazon-science/eideticnet-training}{this https URL}.
How Lexical is Bilingual Lexicon Induction?
Apr 05, 2024In contemporary machine learning approaches to bilingual lexicon induction (BLI), a model learns a mapping between the embedding spaces of a language pair. Recently, retrieve-and-rank approach to BLI has achieved state of the art results on the task. However, the problem remains challenging in low-resource settings, due to the paucity of data. The task is complicated by factors such as lexical variation across languages. We argue that the incorporation of additional lexical information into the recent retrieve-and-rank approach should improve lexicon induction. We demonstrate the efficacy of our proposed approach on XLING, improving over the previous state of the art by an average of 2\% across all language pairs.
Look-ups are not all you need for deep learning inference
Jul 12, 2022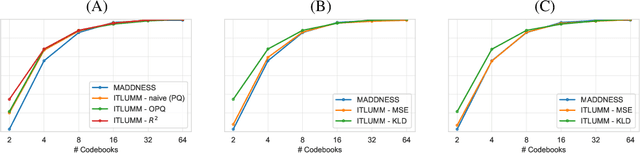

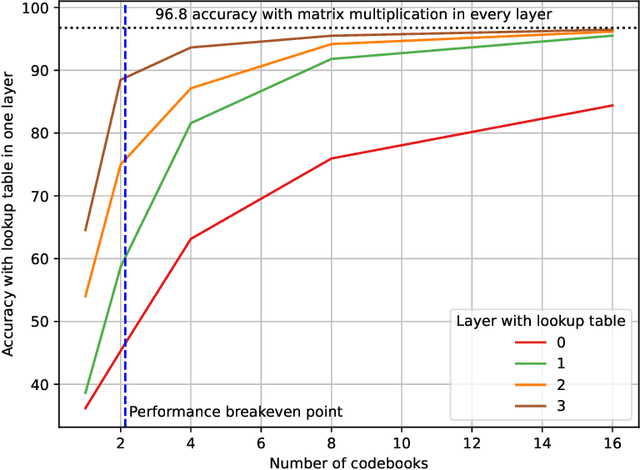
Fast approximations to matrix multiplication have the potential to dramatically reduce the cost of neural network inference. Recent work on approximate matrix multiplication proposed to replace costly multiplications with table-lookups by fitting a fast hash function from training data. In this work, we propose improvements to this previous work, targeted to the deep learning inference setting, where one has access to both training data and fixed (already learned) model weight matrices. We further propose a fine-tuning procedure for accelerating entire neural networks while minimizing loss in accuracy. Finally, we analyze the proposed method on a simple image classification task. While we show improvements to prior work, overall classification accuracy remains substantially diminished compared to exact matrix multiplication. Our work, despite this negative result, points the way towards future efforts to accelerate inner products with fast nonlinear hashing methods.
Adaptive Block Floating-Point for Analog Deep Learning Hardware
May 12, 2022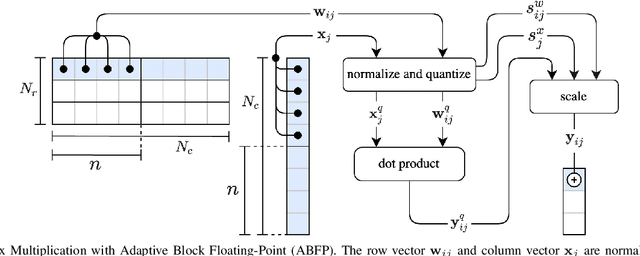

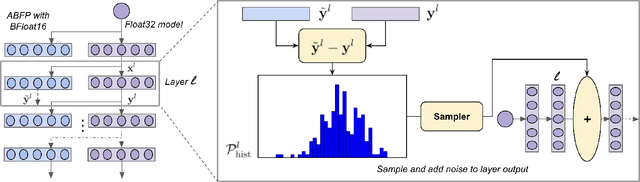
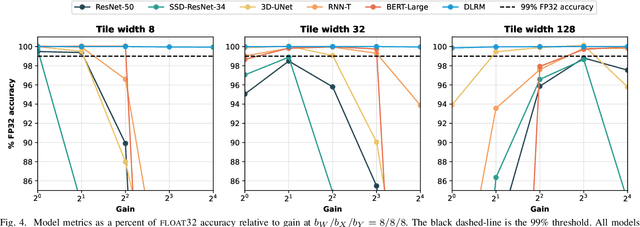
Analog mixed-signal (AMS) devices promise faster, more energy-efficient deep neural network (DNN) inference than their digital counterparts. However, recent studies show that DNNs on AMS devices with fixed-point numbers can incur an accuracy penalty because of precision loss. To mitigate this penalty, we present a novel AMS-compatible adaptive block floating-point (ABFP) number representation. We also introduce amplification (or gain) as a method for increasing the accuracy of the number representation without increasing the bit precision of the output. We evaluate the effectiveness of ABFP on the DNNs in the MLPerf datacenter inference benchmark -- realizing less than $1\%$ loss in accuracy compared to FLOAT32. We also propose a novel method of finetuning for AMS devices, Differential Noise Finetuning (DNF), which samples device noise to speed up finetuning compared to conventional Quantization-Aware Training.
Effective sampling for large-scale automated writing evaluation systems
Dec 17, 2014

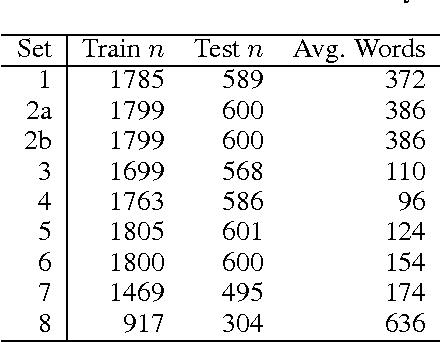
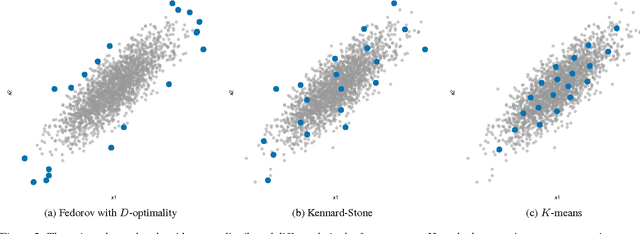
Automated writing evaluation (AWE) has been shown to be an effective mechanism for quickly providing feedback to students. It has already seen wide adoption in enterprise-scale applications and is starting to be adopted in large-scale contexts. Training an AWE model has historically required a single batch of several hundred writing examples and human scores for each of them. This requirement limits large-scale adoption of AWE since human-scoring essays is costly. Here we evaluate algorithms for ensuring that AWE models are consistently trained using the most informative essays. Our results show how to minimize training set sizes while maximizing predictive performance, thereby reducing cost without unduly sacrificing accuracy. We conclude with a discussion of how to integrate this approach into large-scale AWE systems.