 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Embedding Performance through Large Language Model-based Text Enrichment and Rewriting
Apr 18, 2024Embedding models are crucial for various natural language processing tasks but can be limited by factors such as limited vocabulary, lack of context, and grammatical errors. This paper proposes a novel approach to improve embedding performance by leveraging large language models (LLMs) to enrich and rewrite input text before the embedding process. By utilizing ChatGPT 3.5 to provide additional context, correct inaccuracies, and incorporate metadata, the proposed method aims to enhance the utility and accuracy of embedding models. The effectiveness of this approach is evaluated on three datasets: Banking77Classification, TwitterSemEval 2015, and Amazon Counter-factual Classification. Results demonstrate significant improvements over the baseline model on the TwitterSemEval 2015 dataset, with the best-performing prompt achieving a score of 85.34 compared to the previous best of 81.52 on the Massive Text Embedding Benchmark (MTEB) Leaderboard. However, performance on the other two datasets was less impressive, highlighting the importance of considering domain-specific characteristics. The findings suggest that LLM-based text enrichment has shown promising results to improve embedding performance, particularly in certain domains. Hence, numerous limitations in the process of embedding can be avoided.
Adaptive Block Floating-Point for Analog Deep Learning Hardware
May 12, 2022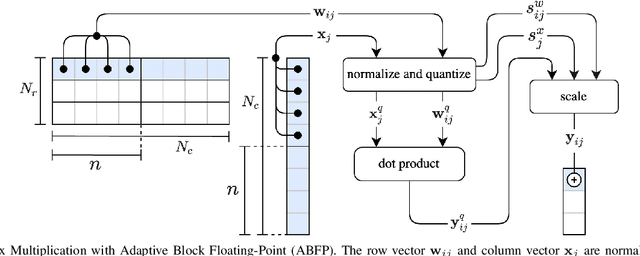

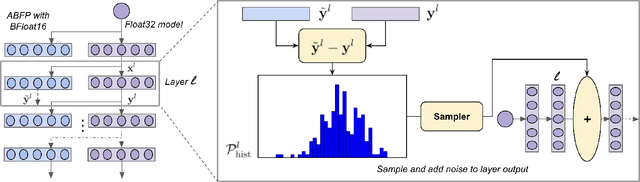
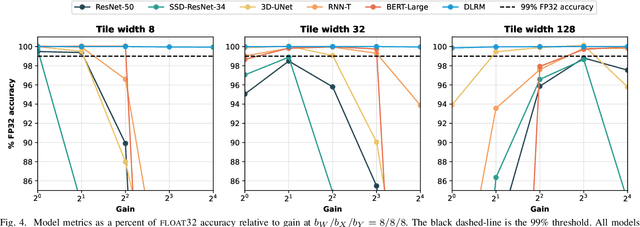
Analog mixed-signal (AMS) devices promise faster, more energy-efficient deep neural network (DNN) inference than their digital counterparts. However, recent studies show that DNNs on AMS devices with fixed-point numbers can incur an accuracy penalty because of precision loss. To mitigate this penalty, we present a novel AMS-compatible adaptive block floating-point (ABFP) number representation. We also introduce amplification (or gain) as a method for increasing the accuracy of the number representation without increasing the bit precision of the output. We evaluate the effectiveness of ABFP on the DNNs in the MLPerf datacenter inference benchmark -- realizing less than $1\%$ loss in accuracy compared to FLOAT32. We also propose a novel method of finetuning for AMS devices, Differential Noise Finetuning (DNF), which samples device noise to speed up finetuning compared to conventional Quantization-Aware Training.