 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINT-FP-QSim: Mixed Precision and Formats For Large Language Models and Vision Transformers
Jul 07, 2023The recent rise of large language models (LLMs) has resulted in increased efforts towards running LLMs at reduced precision. Running LLMs at lower precision supports resource constraints and furthers their democratization, enabling users to run billion-parameter LLMs on their personal devices. To supplement this ongoing effort, we propose INT-FP-QSim: an open-source simulator that enables flexible evaluation of LLMs and vision transformers at various numerical precisions and formats. INT-FP-QSim leverages existing open-source repositories such as TensorRT, QPytorch and AIMET for a combined simulator that supports various floating point and integer formats. With the help of our simulator, we survey the impact of different numerical formats on the performance of LLMs and vision transformers at 4-bit weights and 4-bit or 8-bit activations. We also compare recently proposed methods like Adaptive Block Floating Point, SmoothQuant, GPTQ and RPTQ on the model performances. We hope INT-FP-QSim will enable researchers to flexibly simulate models at various precisions to support further research in quantization of LLMs and vision transformers.
Adaptive Block Floating-Point for Analog Deep Learning Hardware
May 12, 2022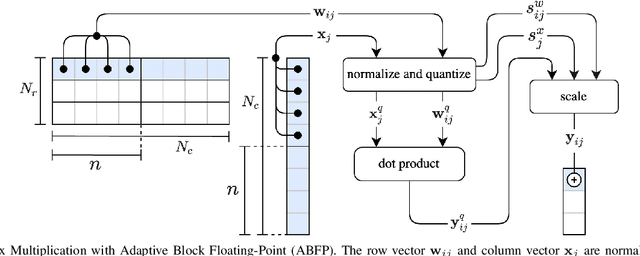

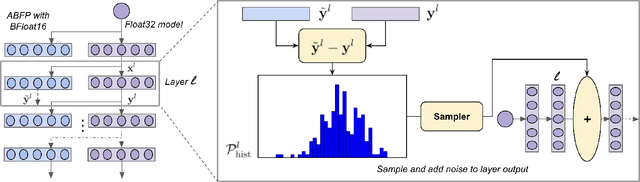
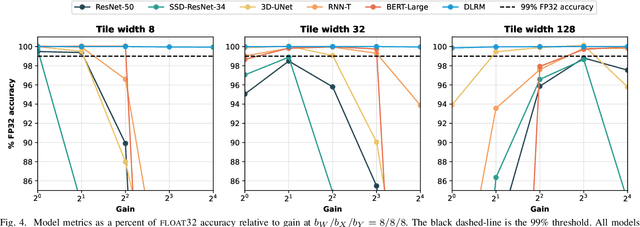
Analog mixed-signal (AMS) devices promise faster, more energy-efficient deep neural network (DNN) inference than their digital counterparts. However, recent studies show that DNNs on AMS devices with fixed-point numbers can incur an accuracy penalty because of precision loss. To mitigate this penalty, we present a novel AMS-compatible adaptive block floating-point (ABFP) number representation. We also introduce amplification (or gain) as a method for increasing the accuracy of the number representation without increasing the bit precision of the output. We evaluate the effectiveness of ABFP on the DNNs in the MLPerf datacenter inference benchmark -- realizing less than $1\%$ loss in accuracy compared to FLOAT32. We also propose a novel method of finetuning for AMS devices, Differential Noise Finetuning (DNF), which samples device noise to speed up finetuning compared to conventional Quantization-Aware Training.