 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlow-of-Options: Diversified and Improved LLM Reasoning by Thinking Through Options
Feb 18, 2025



We present a novel reasoning approach called Flow-of-Options (FoO), designed to address intrinsic biases in Large Language Models (LLMs). FoO enables LLMs to systematically explore a diverse range of possibilities in their reasoning, as demonstrated by an FoO-based agentic system for autonomously solving Machine Learning tasks (AutoML). Our framework outperforms state-of-the-art baselines, achieving improvements of 38.2% - 69.2% on standard data science tasks, and 37.4% - 47.9% on therapeutic chemistry tasks. With an overall operation cost under $1 per task, our framework is well-suited for cost-sensitive applications. Beyond classification and regression, we illustrate the broader applicability of our FoO-based agentic system to tasks such as reinforcement learning and image generation. Our framework presents significant advancements compared to current state-of-the-art agentic systems for AutoML, due to the benefits of FoO in enforcing diversity in LLM solutions through compressed, explainable representations that also support long-term memory when combined with case-based reasoning.
Improved Generation of Synthetic Imaging Data Using Feature-Aligned Diffusion
Oct 01, 2024Synthetic data generation is an important application of machine learning in the field of medical imaging. While existing approaches have successfully applied fine-tuned diffusion models for synthesizing medical images, we explore potential improvements to this pipeline through feature-aligned diffusion. Our approach aligns intermediate features of the diffusion model to the output features of an expert, and our preliminary findings show an improvement of 9% in generation accuracy and ~0.12 in SSIM diversity. Our approach is also synergistic with existing methods, and easily integrated into diffusion training pipelines for improvements. We make our code available at \url{https://github.com/lnairGT/Feature-Aligned-Diffusion}.
Creative Problem Solving in Large Language and Vision Models -- What Would it Take?
May 02, 2024



In this paper, we discuss approaches for integrating Computational Creativity (CC) with research in large language and vision models (LLVMs) to address a key limitation of these models, i.e., creative problem solving. We present preliminary experiments showing how CC principles can be applied to address this limitation through augmented prompting. With this work, we hope to foster discussions of Computational Creativity in the context of ML algorithms for creative problem solving in LLVMs. Our code is at: https://github.com/lnairGT/creative-problem-solving-LLMs
CLIP-Embed-KD: Computationally Efficient Knowledge Distillation Using Embeddings as Teachers
Apr 09, 2024Contrastive Language-Image Pre-training (CLIP) has been shown to improve zero-shot generalization capabilities of language and vision models. In this paper, we extend CLIP for efficient knowledge distillation, by utilizing embeddings as teachers. Typical knowledge distillation frameworks require running forward passes through a teacher model, which is often prohibitive in the case of billion or trillion parameter teachers. In these cases, using only the embeddings of the teacher models to guide the distillation can yield significant computational savings. Our preliminary findings show that CLIP-based knowledge distillation with embeddings can outperform full scale knowledge distillation using $9\times$ less memory and $8\times$ less training time. Code available at: https://github.com/lnairGT/CLIP-Distillation/
Photonic Accelerators for Image Segmentation in Autonomous Driving and Defect Detection
Oct 03, 2023



Photonic computing promises faster and more energy-efficient deep neural network (DNN) inference than traditional digital hardware. Advances in photonic computing can have profound impacts on applications such as autonomous driving and defect detection that depend on fast, accurate and energy efficient execution of image segmentation models. In this paper, we investigate image segmentation on photonic accelerators to explore: a) the types of image segmentation DNN architectures that are best suited for photonic accelerators, and b) the throughput and energy efficiency of executing the different image segmentation models on photonic accelerators, along with the trade-offs involved therein. Specifically, we demonstrate that certain segmentation models exhibit negligible loss in accuracy (compared to digital float32 models) when executed on photonic accelerators, and explore the empirical reasoning for their robustness. We also discuss techniques for recovering accuracy in the case of models that do not perform well. Further, we compare throughput (inferences-per-second) and energy consumption estimates for different image segmentation workloads on photonic accelerators. We discuss the challenges and potential optimizations that can help improve the application of photonic accelerators to such computer vision tasks.
A Blueprint for Precise and Fault-Tolerant Analog Neural Networks
Sep 19, 2023Analog computing has reemerged as a promising avenue for accelerating deep neural networks (DNNs) due to its potential to overcome the energy efficiency and scalability challenges posed by traditional digital architectures. However, achieving high precision and DNN accuracy using such technologies is challenging, as high-precision data converters are costly and impractical. In this paper, we address this challenge by using the residue number system (RNS). RNS allows composing high-precision operations from multiple low-precision operations, thereby eliminating the information loss caused by the limited precision of the data converters. Our study demonstrates that analog accelerators utilizing the RNS-based approach can achieve ${\geq}99\%$ of FP32 accuracy for state-of-the-art DNN inference using data converters with only $6$-bit precision whereas a conventional analog core requires more than $8$-bit precision to achieve the same accuracy in the same DNNs. The reduced precision requirements imply that using RNS can reduce the energy consumption of analog accelerators by several orders of magnitude while maintaining the same throughput and precision. Our study extends this approach to DNN training, where we can efficiently train DNNs using $7$-bit integer arithmetic while achieving accuracy comparable to FP32 precision. Lastly, we present a fault-tolerant dataflow using redundant RNS error-correcting codes to protect the computation against noise and errors inherent within an analog accelerator.
INT-FP-QSim: Mixed Precision and Formats For Large Language Models and Vision Transformers
Jul 07, 2023The recent rise of large language models (LLMs) has resulted in increased efforts towards running LLMs at reduced precision. Running LLMs at lower precision supports resource constraints and furthers their democratization, enabling users to run billion-parameter LLMs on their personal devices. To supplement this ongoing effort, we propose INT-FP-QSim: an open-source simulator that enables flexible evaluation of LLMs and vision transformers at various numerical precisions and formats. INT-FP-QSim leverages existing open-source repositories such as TensorRT, QPytorch and AIMET for a combined simulator that supports various floating point and integer formats. With the help of our simulator, we survey the impact of different numerical formats on the performance of LLMs and vision transformers at 4-bit weights and 4-bit or 8-bit activations. We also compare recently proposed methods like Adaptive Block Floating Point, SmoothQuant, GPTQ and RPTQ on the model performances. We hope INT-FP-QSim will enable researchers to flexibly simulate models at various precisions to support further research in quantization of LLMs and vision transformers.
Sensitivity-Aware Finetuning for Accuracy Recovery on Deep Learning Hardware
Jun 05, 2023Existing methods to recover model accuracy on analog-digital hardware in the presence of quantization and analog noise include noise-injection training. However, it can be slow in practice, incurring high computational costs, even when starting from pretrained models. We introduce the Sensitivity-Aware Finetuning (SAFT) approach that identifies noise sensitive layers in a model, and uses the information to freeze specific layers for noise-injection training. Our results show that SAFT achieves comparable accuracy to noise-injection training and is 2x to 8x faster.
Adaptive Block Floating-Point for Analog Deep Learning Hardware
May 12, 2022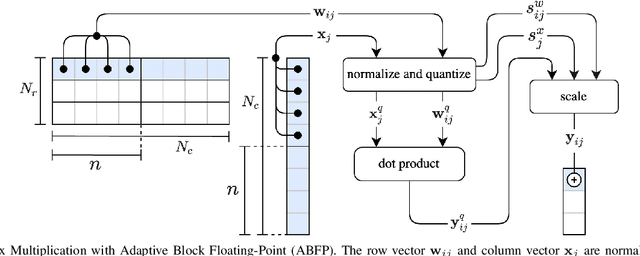

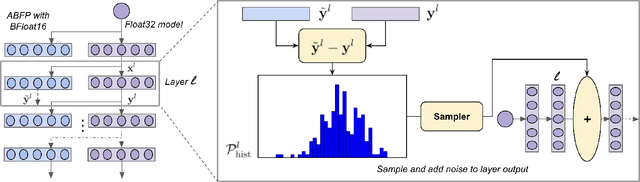
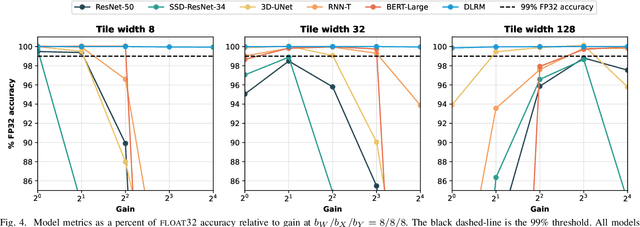
Analog mixed-signal (AMS) devices promise faster, more energy-efficient deep neural network (DNN) inference than their digital counterparts. However, recent studies show that DNNs on AMS devices with fixed-point numbers can incur an accuracy penalty because of precision loss. To mitigate this penalty, we present a novel AMS-compatible adaptive block floating-point (ABFP) number representation. We also introduce amplification (or gain) as a method for increasing the accuracy of the number representation without increasing the bit precision of the output. We evaluate the effectiveness of ABFP on the DNNs in the MLPerf datacenter inference benchmark -- realizing less than $1\%$ loss in accuracy compared to FLOAT32. We also propose a novel method of finetuning for AMS devices, Differential Noise Finetuning (DNF), which samples device noise to speed up finetuning compared to conventional Quantization-Aware Training.
Creative Problem Solving in Artificially Intelligent Agents: A Survey and Framework
Apr 21, 2022


Creative Problem Solving (CPS) is a sub-area within Artificial Intelligence (AI) that focuses on methods for solving off-nominal, or anomalous problems in autonomous systems. Despite many advancements in planning and learning, resolving novel problems or adapting existing knowledge to a new context, especially in cases where the environment may change in unpredictable ways post deployment, remains a limiting factor in the safe and useful integration of intelligent systems. The emergence of increasingly autonomous systems dictates the necessity for AI agents to deal with environmental uncertainty through creativity. To stimulate further research in CPS, we present a definition and a framework of CPS, which we adopt to categorize existing AI methods in this field. Our framework consists of four main components of a CPS problem, namely, 1) problem formulation, 2) knowledge representation, 3) method of knowledge manipulation, and 4) method of evaluation. We conclude our survey with open research questions, and suggested directions for the future.