 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmerging from Ground: Addressing Intent Deviation in Tool-Using Agents via Deriving Real Calls into Virtual Trajectories
Jan 21, 2026LLMs have advanced tool-using agents for real-world applications, yet they often lead to unexpected behaviors or results. Beyond obvious failures, the subtle issue of "intent deviation" severely hinders reliable evaluation and performance improvement. Existing post-training methods generally leverage either real system samples or virtual data simulated by LLMs. However, the former is costly due to reliance on hand-crafted user requests, while the latter suffers from distribution shift from the real tools in the wild. Additionally, both methods lack negative samples tailored to intent deviation scenarios, hindering effective guidance on preference learning. We introduce RISE, a "Real-to-Virtual" method designed to mitigate intent deviation. Anchoring on verified tool primitives, RISE synthesizes virtual trajectories and generates diverse negative samples through mutation on critical parameters. With synthetic data, RISE fine-tunes backbone LLMs via the two-stage training for intent alignment. Evaluation results demonstrate that data synthesized by RISE achieve promising results in eight metrics covering user requires, execution trajectories and agent responses. Integrating with training, RISE achieves an average 35.28% improvement in Acctask (task completion) and 23.27% in Accintent (intent alignment), outperforming SOTA baselines by 1.20--42.09% and 1.17--54.93% respectively.
All Changes May Have Invariant Principles: Improving Ever-Shifting Harmful Meme Detection via Design Concept Reproduction
Jan 08, 2026Harmful memes are ever-shifting in the Internet communities, which are difficult to analyze due to their type-shifting and temporal-evolving nature. Although these memes are shifting, we find that different memes may share invariant principles, i.e., the underlying design concept of malicious users, which can help us analyze why these memes are harmful. In this paper, we propose RepMD, an ever-shifting harmful meme detection method based on the design concept reproduction. We first refer to the attack tree to define the Design Concept Graph (DCG), which describes steps that people may take to design a harmful meme. Then, we derive the DCG from historical memes with design step reproduction and graph pruning. Finally, we use DCG to guide the Multimodal Large Language Model (MLLM) to detect harmful memes. The evaluation results show that RepMD achieves the highest accuracy with 81.1% and has slight accuracy decreases when generalized to type-shifting and temporal-evolving memes. Human evaluation shows that RepMD can improve the efficiency of human discovery on harmful memes, with 15$\sim$30 seconds per meme.
Know Thy Enemy: Securing LLMs Against Prompt Injection via Diverse Data Synthesis and Instruction-Level Chain-of-Thought Learning
Jan 08, 2026Large language model (LLM)-integrated applications have become increasingly prevalent, yet face critical security vulnerabilities from prompt injection (PI) attacks. Defending against PI attacks faces two major issues: malicious instructions can be injected through diverse vectors, and injected instructions often lack clear semantic boundaries from the surrounding context, making them difficult to identify. To address these issues, we propose InstruCoT, a model enhancement method for PI defense that synthesizes diverse training data and employs instruction-level chain-of-thought fine-tuning, enabling LLMs to effectively identify and reject malicious instructions regardless of their source or position in the context. We evaluate InstruCoT across three critical dimensions: Behavior Deviation, Privacy Leakage, and Harmful Output. Experimental results across four LLMs demonstrate that InstruCoT significantly outperforms baselines in all dimensions while maintaining utility performance without degradation
One Shot Dominance: Knowledge Poisoning Attack on Retrieval-Augmented Generation Systems
May 15, 2025Large Language Models (LLMs) enhanced with Retrieval-Augmented Generation (RAG) have shown improved performance in generating accurate responses. However, the dependence on external knowledge bases introduces potential security vulnerabilities, particularly when these knowledge bases are publicly accessible and modifiable. Poisoning attacks on knowledge bases for RAG systems face two fundamental challenges: the injected malicious content must compete with multiple authentic documents retrieved by the retriever, and LLMs tend to trust retrieved information that aligns with their internal memorized knowledge. Previous works attempt to address these challenges by injecting multiple malicious documents, but such saturation attacks are easily detectable and impractical in real-world scenarios. To enable the effective single document poisoning attack, we propose AuthChain, a novel knowledge poisoning attack method that leverages Chain-of-Evidence theory and authority effect to craft more convincing poisoned documents. AuthChain generates poisoned content that establishes strong evidence chains and incorporates authoritative statements, effectively overcoming the interference from both authentic documents and LLMs' internal knowledge. Extensive experiments across six popular LLMs demonstrate that AuthChain achieves significantly higher attack success rates while maintaining superior stealthiness against RAG defense mechanisms compared to state-of-the-art baselines.
Mimicking the Familiar: Dynamic Command Generation for Information Theft Attacks in LLM Tool-Learning System
Feb 17, 2025



Information theft attacks pose a significant risk to Large Language Model (LLM) tool-learning systems. Adversaries can inject malicious commands through compromised tools, manipulating LLMs to send sensitive information to these tools, which leads to potential privacy breaches. However, existing attack approaches are black-box oriented and rely on static commands that cannot adapt flexibly to the changes in user queries and the invocation chain of tools. It makes malicious commands more likely to be detected by LLM and leads to attack failure. In this paper, we propose AutoCMD, a dynamic attack comment generation approach for information theft attacks in LLM tool-learning systems. Inspired by the concept of mimicking the familiar, AutoCMD is capable of inferring the information utilized by upstream tools in the toolchain through learning on open-source systems and reinforcement with target system examples, thereby generating more targeted commands for information theft. The evaluation results show that AutoCMD outperforms the baselines with +13.2% $ASR_{Theft}$, and can be generalized to new tool-learning systems to expose their information leakage risks. We also design four defense methods to effectively protect tool-learning systems from the attack.
PatUntrack: Automated Generating Patch Examples for Issue Reports without Tracked Insecure Code
Aug 16, 2024

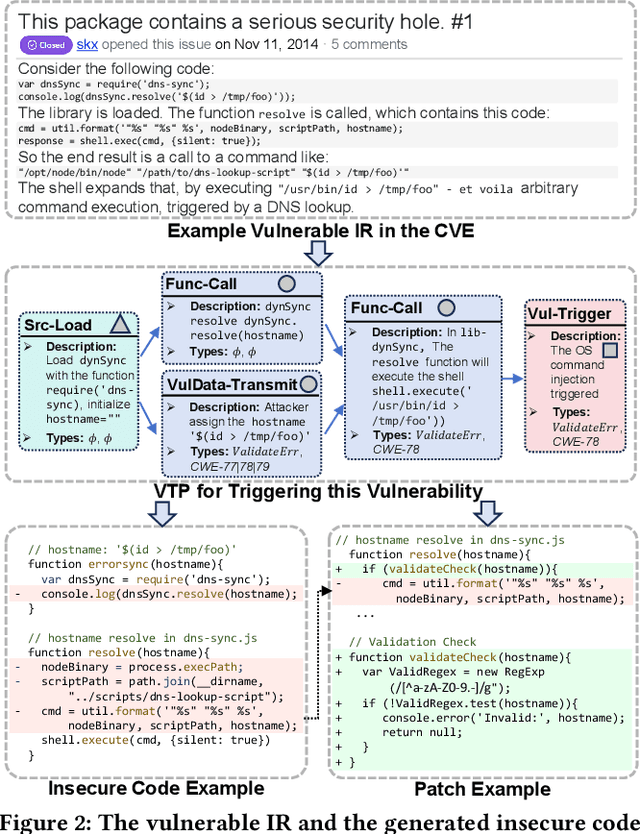

Security patches are essential for enhancing the stability and robustness of projects in the software community. While vulnerabilities are officially expected to be patched before being disclosed, patching vulnerabilities is complicated and remains a struggle for many organizations. To patch vulnerabilities, security practitioners typically track vulnerable issue reports (IRs), and analyze their relevant insecure code to generate potential patches. However, the relevant insecure code may not be explicitly specified and practitioners cannot track the insecure code in the repositories, thus limiting their ability to generate patches. In such cases, providing examples of insecure code and the corresponding patches would benefit the security developers to better locate and fix the insecure code. In this paper, we propose PatUntrack to automatically generating patch examples from IRs without tracked insecure code. It auto-prompts Large Language Models (LLMs) to make them applicable to analyze the vulnerabilities. It first generates the completed description of the Vulnerability-Triggering Path (VTP) from vulnerable IRs. Then, it corrects hallucinations in the VTP description with external golden knowledge. Finally, it generates Top-K pairs of Insecure Code and Patch Example based on the corrected VTP description. To evaluate the performance, we conducted experiments on 5,465 vulnerable IRs. The experimental results show that PatUntrack can obtain the highest performance and improve the traditional LLM baselines by +14.6% (Fix@10) on average in patch example generation. Furthermore, PatUntrack was applied to generate patch examples for 76 newly disclosed vulnerable IRs. 27 out of 37 replies from the authors of these IRs confirmed the usefulness of the patch examples generated by PatUntrack, indicating that they can benefit from these examples for patching the vulnerabilities.