 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReduce, Reuse, Recycle: Improving Training Efficiency with Distillation
Nov 01, 2022Methods for improving the efficiency of deep network training (i.e. the resources required to achieve a given level of model quality) are of immediate benefit to deep learning practitioners. Distillation is typically used to compress models or improve model quality, but it's unclear if distillation actually improves training efficiency. Can the quality improvements of distillation be converted into training speed-ups, or do they simply increase final model quality with no resource savings? We conducted a series of experiments to investigate whether and how distillation can be used to accelerate training using ResNet-50 trained on ImageNet and BERT trained on C4 with a masked language modeling objective and evaluated on GLUE, using common enterprise hardware (8x NVIDIA A100). We found that distillation can speed up training by up to 1.96x in ResNet-50 trained on ImageNet and up to 1.42x on BERT when evaluated on GLUE. Furthermore, distillation for BERT yields optimal results when it is only performed for the first 20-50% of training. We also observed that training with distillation is almost always more efficient than training without distillation, even when using the poorest-quality model as a teacher, in both ResNet-50 and BERT. Finally, we found that it's possible to gain the benefit of distilling from an ensemble of teacher models, which has O(n) runtime cost, by randomly sampling a single teacher from the pool of teacher models on each step, which only has a O(1) runtime cost. Taken together, these results show that distillation can substantially improve training efficiency in both image classification and language modeling, and that a few simple optimizations to distillation protocols can further enhance these efficiency improvements.
Learning Omnidirectional Flow in 360-degree Video via Siamese Representation
Aug 07, 2022Optical flow estimation in omnidirectional videos faces two significant issues: the lack of benchmark datasets and the challenge of adapting perspective video-based methods to accommodate the omnidirectional nature. This paper proposes the first perceptually natural-synthetic omnidirectional benchmark dataset with a 360-degree field of view, FLOW360, with 40 different videos and 4,000 video frames. We conduct comprehensive characteristic analysis and comparisons between our dataset and existing optical flow datasets, which manifest perceptual realism, uniqueness, and diversity. To accommodate the omnidirectional nature, we present a novel Siamese representation Learning framework for Omnidirectional Flow (SLOF). We train our network in a contrastive manner with a hybrid loss function that combines contrastive loss and optical flow loss. Extensive experiments verify the proposed framework's effectiveness and show up to 40% performance improvement over the state-of-the-art approaches. Our FLOW360 dataset and code are available at https://siamlof.github.io/.
Network Binarization via Contrastive Learning
Jul 16, 2022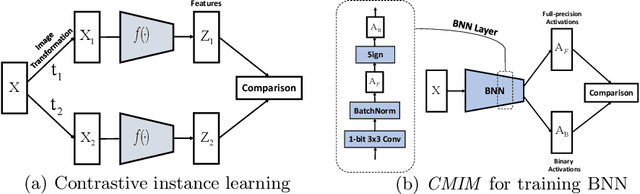
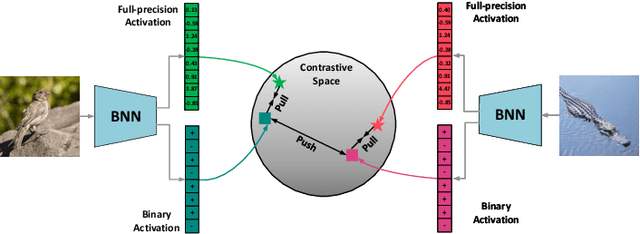
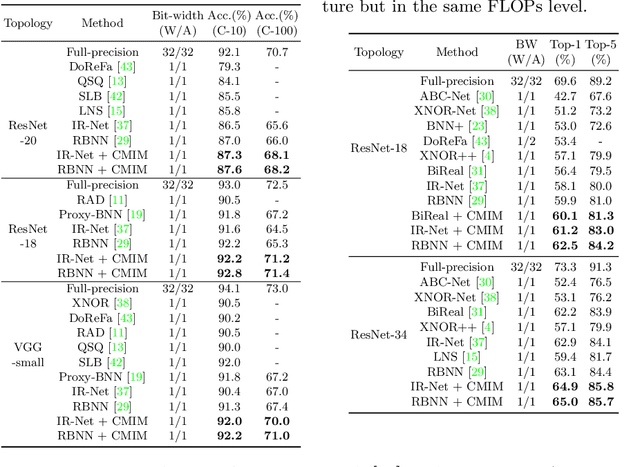

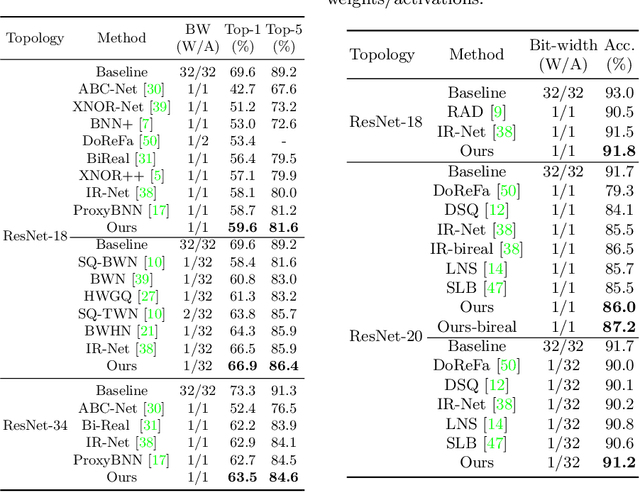
Neural network binarization accelerates deep models by quantizing their weights and activations into 1-bit. However, there is still a huge performance gap between Binary Neural Networks (BNNs) and their full-precision (FP) counterparts. As the quantization error caused by weights binarization has been reduced in earlier works, the activations binarization becomes the major obstacle for further improvement of the accuracy. BNN characterises a unique and interesting structure, where the binary and latent FP activations exist in the same forward pass (i.e., $\text{Binarize}(\mathbf{a}_F) = \mathbf{a}_B$). To mitigate the information degradation caused by the binarization operation from FP to binary activations, we establish a novel contrastive learning framework while training BNNs through the lens of Mutual Information (MI) maximization. MI is introduced as the metric to measure the information shared between binary and FP activations, which assists binarization with contrastive learning. Specifically, the representation ability of the BNNs is greatly strengthened via pulling the positive pairs with binary and FP activations from the same input samples, as well as pushing negative pairs from different samples (the number of negative pairs can be exponentially large). This benefits the downstream tasks, not only classification but also segmentation and depth estimation, etc. The experimental results show that our method can be implemented as a pile-up module on existing state-of-the-art binarization methods and can remarkably improve the performance over them on CIFAR-10/100 and ImageNet, in addition to the great generalization ability on NYUD-v2.
Lipschitz Continuity Retained Binary Neural Network
Jul 16, 2022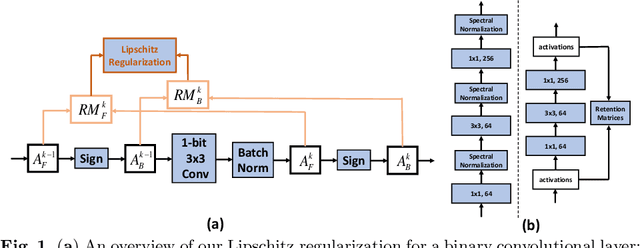

Relying on the premise that the performance of a binary neural network can be largely restored with eliminated quantization error between full-precision weight vectors and their corresponding binary vectors, existing works of network binarization frequently adopt the idea of model robustness to reach the aforementioned objective. However, robustness remains to be an ill-defined concept without solid theoretical support. In this work, we introduce the Lipschitz continuity, a well-defined functional property, as the rigorous criteria to define the model robustness for BNN. We then propose to retain the Lipschitz continuity as a regularization term to improve the model robustness. Particularly, while the popular Lipschitz-involved regularization methods often collapse in BNN due to its extreme sparsity, we design the Retention Matrices to approximate spectral norms of the targeted weight matrices, which can be deployed as the approximation for the Lipschitz constant of BNNs without the exact Lipschitz constant computation (NP-hard). Our experiments prove that our BNN-specific regularization method can effectively strengthen the robustness of BNN (testified on ImageNet-C), achieving state-of-the-art performance on CIFAR and ImageNet.
Win the Lottery Ticket via Fourier Analysis: Frequencies Guided Network Pruning
Jan 30, 2022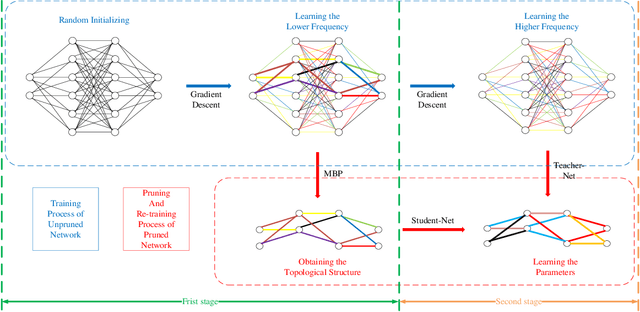
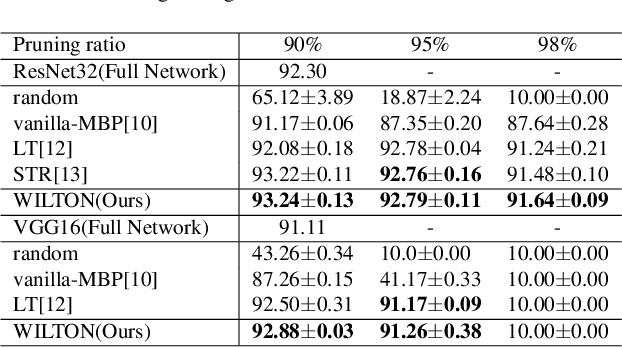
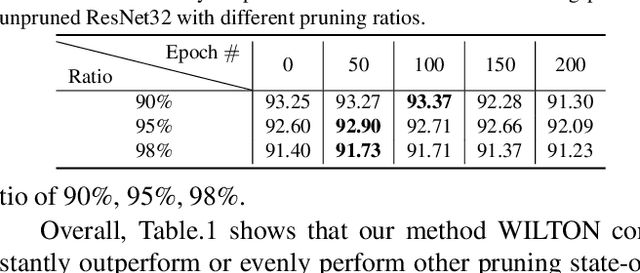
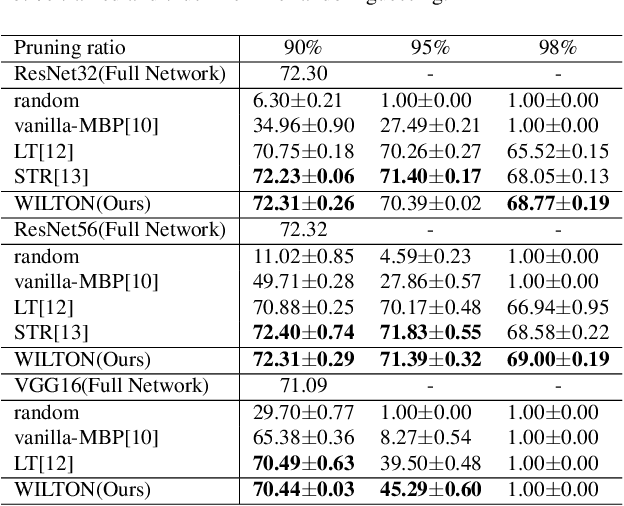
With the remarkable success of deep learning recently, efficient network compression algorithms are urgently demanded for releasing the potential computational power of edge devices, such as smartphones or tablets. However, optimal network pruning is a non-trivial task which mathematically is an NP-hard problem. Previous researchers explain training a pruned network as buying a lottery ticket. In this paper, we investigate the Magnitude-Based Pruning (MBP) scheme and analyze it from a novel perspective through Fourier analysis on the deep learning model to guide model designation. Besides explaining the generalization ability of MBP using Fourier transform, we also propose a novel two-stage pruning approach, where one stage is to obtain the topological structure of the pruned network and the other stage is to retrain the pruned network to recover the capacity using knowledge distillation from lower to higher on the frequency domain. Extensive experiments on CIFAR-10 and CIFAR-100 demonstrate the superiority of our novel Fourier analysis based MBP compared to other traditional MBP algorithms.
Measure Twice, Cut Once: Quantifying Bias and Fairness in Deep Neural Networks
Oct 08, 2021
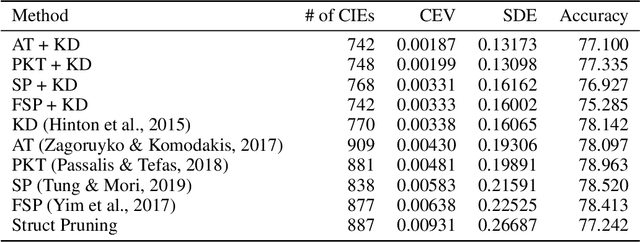
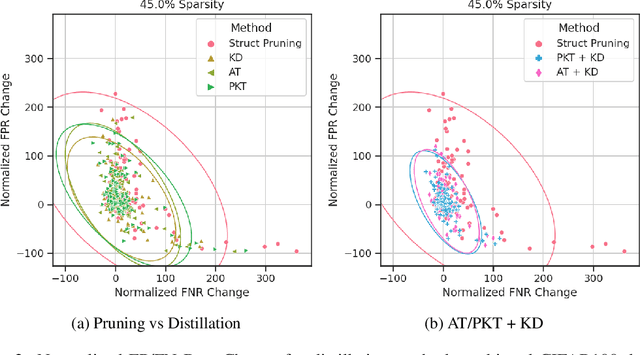
Algorithmic bias is of increasing concern, both to the research community, and society at large. Bias in AI is more abstract and unintuitive than traditional forms of discrimination and can be more difficult to detect and mitigate. A clear gap exists in the current literature on evaluating the relative bias in the performance of multi-class classifiers. In this work, we propose two simple yet effective metrics, Combined Error Variance (CEV) and Symmetric Distance Error (SDE), to quantitatively evaluate the class-wise bias of two models in comparison to one another. By evaluating the performance of these new metrics and by demonstrating their practical application, we show that they can be used to measure fairness as well as bias. These demonstrations show that our metrics can address specific needs for measuring bias in multi-class classification.
Lipschitz Continuity Guided Knowledge Distillation
Aug 29, 2021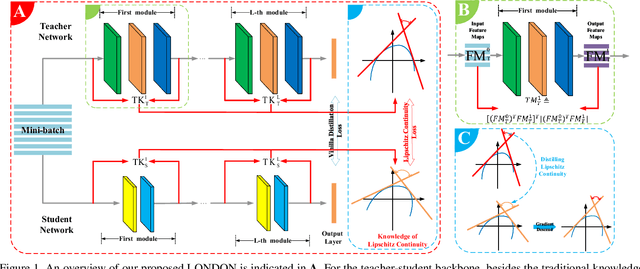
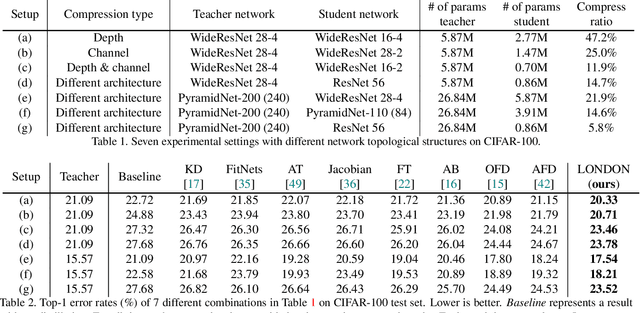
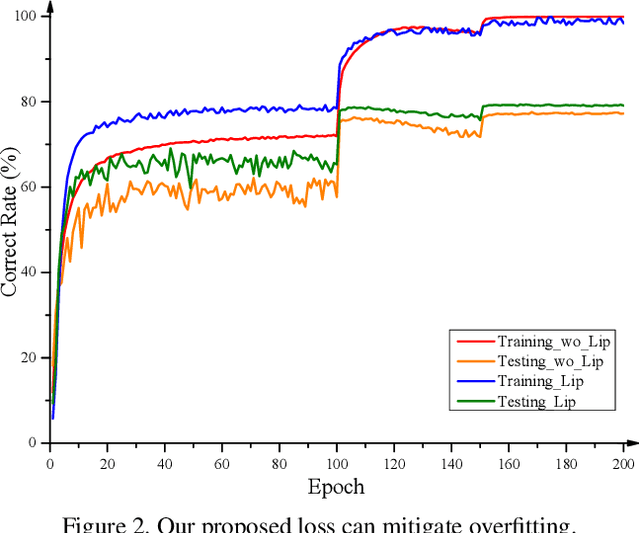
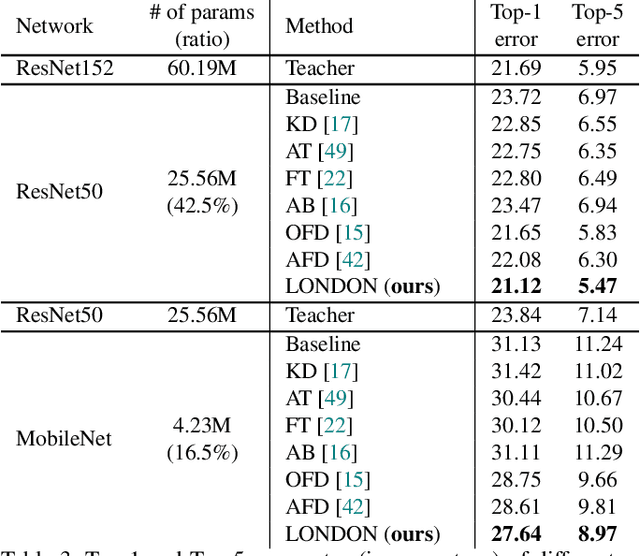
Knowledge distillation has become one of the most important model compression techniques by distilling knowledge from larger teacher networks to smaller student ones. Although great success has been achieved by prior distillation methods via delicately designing various types of knowledge, they overlook the functional properties of neural networks, which makes the process of applying those techniques to new tasks unreliable and non-trivial. To alleviate such problem, in this paper, we initially leverage Lipschitz continuity to better represent the functional characteristic of neural networks and guide the knowledge distillation process. In particular, we propose a novel Lipschitz Continuity Guided Knowledge Distillation framework to faithfully distill knowledge by minimizing the distance between two neural networks' Lipschitz constants, which enables teacher networks to better regularize student networks and improve the corresponding performance. We derive an explainable approximation algorithm with an explicit theoretical derivation to address the NP-hard problem of calculating the Lipschitz constant. Experimental results have shown that our method outperforms other benchmarks over several knowledge distillation tasks (e.g., classification, segmentation and object detection) on CIFAR-100, ImageNet, and PASCAL VOC datasets.
Simon Says: Evaluating and Mitigating Bias in Pruned Neural Networks with Knowledge Distillation
Jun 15, 2021
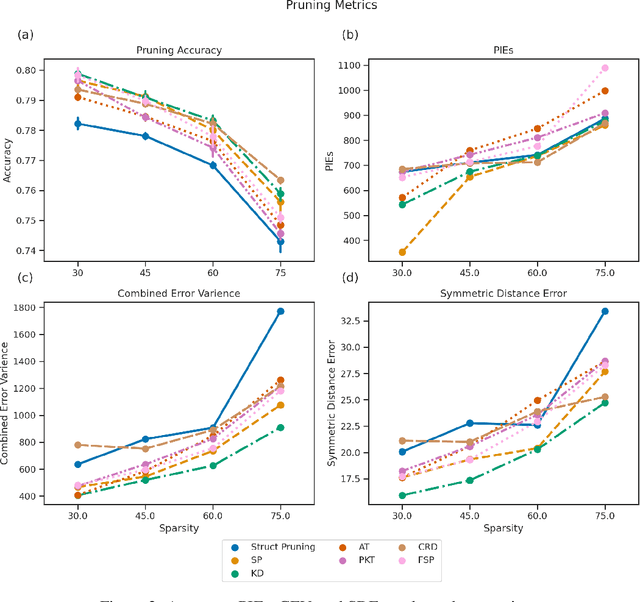
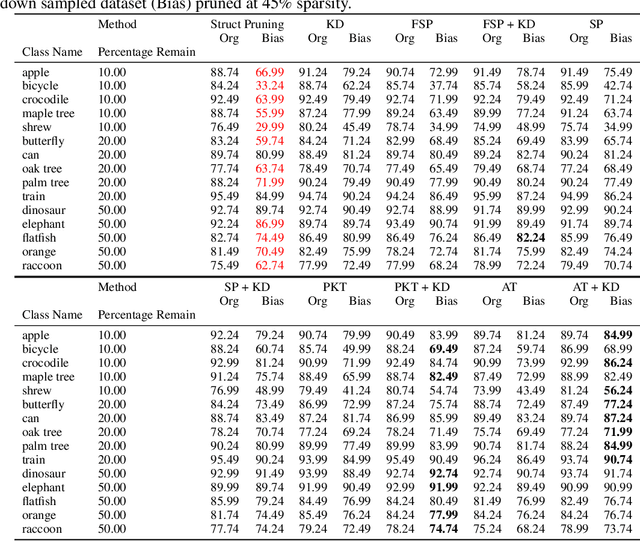
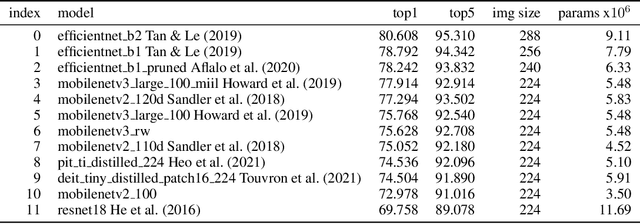
In recent years the ubiquitous deployment of AI has posed great concerns in regards to algorithmic bias, discrimination, and fairness. Compared to traditional forms of bias or discrimination caused by humans, algorithmic bias generated by AI is more abstract and unintuitive therefore more difficult to explain and mitigate. A clear gap exists in the current literature on evaluating and mitigating bias in pruned neural networks. In this work, we strive to tackle the challenging issues of evaluating, mitigating, and explaining induced bias in pruned neural networks. Our paper makes three contributions. First, we propose two simple yet effective metrics, Combined Error Variance (CEV) and Symmetric Distance Error (SDE), to quantitatively evaluate the induced bias prevention quality of pruned models. Second, we demonstrate that knowledge distillation can mitigate induced bias in pruned neural networks, even with unbalanced datasets. Third, we reveal that model similarity has strong correlations with pruning induced bias, which provides a powerful method to explain why bias occurs in pruned neural networks. Our code is available at https://github.com/codestar12/pruning-distilation-bias
Parallel Blockwise Knowledge Distillation for Deep Neural Network Compression
Dec 05, 2020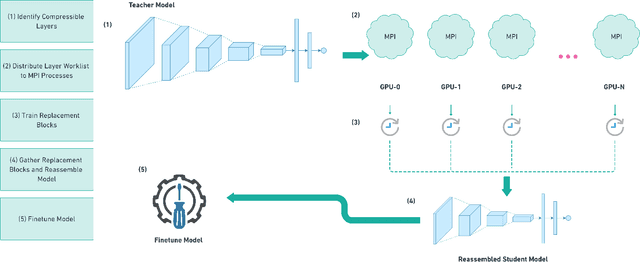

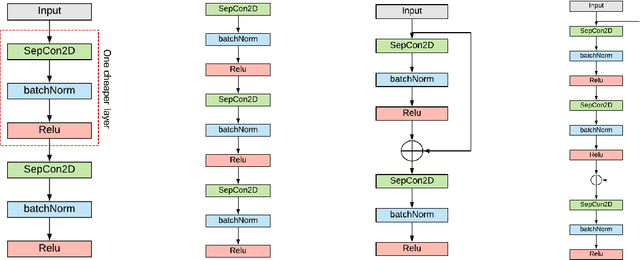
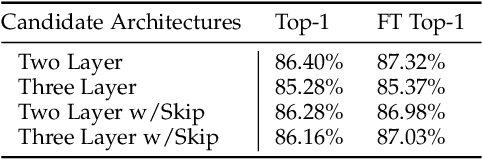
Deep neural networks (DNNs) have been extremely successful in solving many challenging AI tasks in natural language processing, speech recognition, and computer vision nowadays. However, DNNs are typically computation intensive, memory demanding, and power hungry, which significantly limits their usage on platforms with constrained resources. Therefore, a variety of compression techniques (e.g. quantization, pruning, and knowledge distillation) have been proposed to reduce the size and power consumption of DNNs. Blockwise knowledge distillation is one of the compression techniques that can effectively reduce the size of a highly complex DNN. However, it is not widely adopted due to its long training time. In this paper, we propose a novel parallel blockwise distillation algorithm to accelerate the distillation process of sophisticated DNNs. Our algorithm leverages local information to conduct independent blockwise distillation, utilizes depthwise separable layers as the efficient replacement block architecture, and properly addresses limiting factors (e.g. dependency, synchronization, and load balancing) that affect parallelism. The experimental results running on an AMD server with four Geforce RTX 2080Ti GPUs show that our algorithm can achieve 3x speedup plus 19% energy savings on VGG distillation, and 3.5x speedup plus 29% energy savings on ResNet distillation, both with negligible accuracy loss. The speedup of ResNet distillation can be further improved to 3.87 when using four RTX6000 GPUs in a distributed cluster.
Egok360: A 360 Egocentric Kinetic Human Activity Video Dataset
Oct 15, 2020

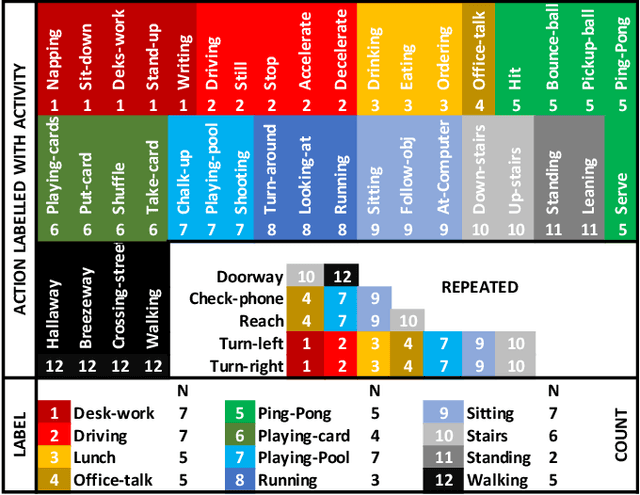
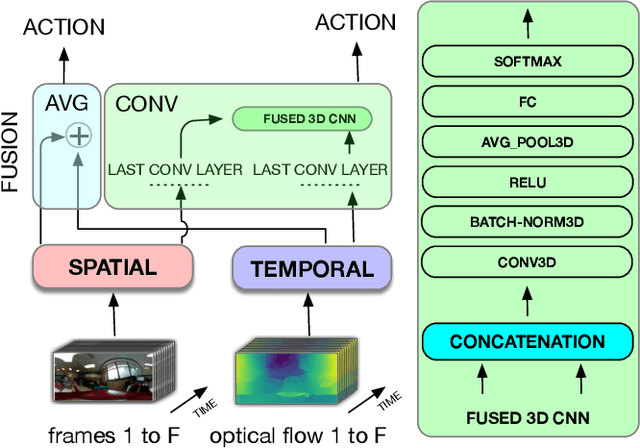
Recently, there has been a growing interest in wearable sensors which provides new research perspectives for 360 {\deg} video analysis. However, the lack of 360 {\deg} datasets in literature hinders the research in this field. To bridge this gap, in this paper we propose a novel Egocentric (first-person) 360{\deg} Kinetic human activity video dataset (EgoK360). The EgoK360 dataset contains annotations of human activity with different sub-actions, e.g., activity Ping-Pong with four sub-actions which are pickup-ball, hit, bounce-ball and serve. To the best of our knowledge, EgoK360 is the first dataset in the domain of first-person activity recognition with a 360{\deg} environmental setup, which will facilitate the egocentric 360 {\deg} video understanding. We provide experimental results and comprehensive analysis of variants of the two-stream network for 360 egocentric activity recognition. The EgoK360 dataset can be downloaded from https://egok360.github.io/.