 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Blockwise Knowledge Distillation for Deep Neural Network Compression
Paper and Code
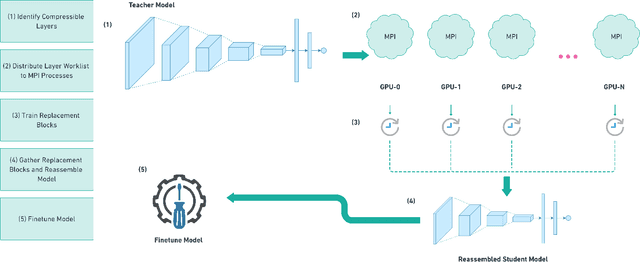

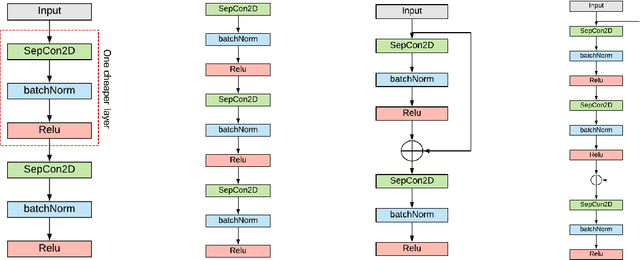
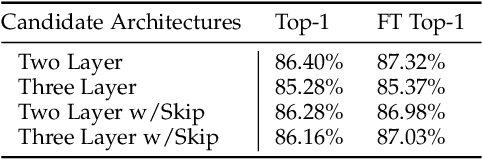
Deep neural networks (DNNs) have been extremely successful in solving many challenging AI tasks in natural language processing, speech recognition, and computer vision nowadays. However, DNNs are typically computation intensive, memory demanding, and power hungry, which significantly limits their usage on platforms with constrained resources. Therefore, a variety of compression techniques (e.g. quantization, pruning, and knowledge distillation) have been proposed to reduce the size and power consumption of DNNs. Blockwise knowledge distillation is one of the compression techniques that can effectively reduce the size of a highly complex DNN. However, it is not widely adopted due to its long training time. In this paper, we propose a novel parallel blockwise distillation algorithm to accelerate the distillation process of sophisticated DNNs. Our algorithm leverages local information to conduct independent blockwise distillation, utilizes depthwise separable layers as the efficient replacement block architecture, and properly addresses limiting factors (e.g. dependency, synchronization, and load balancing) that affect parallelism. The experimental results running on an AMD server with four Geforce RTX 2080Ti GPUs show that our algorithm can achieve 3x speedup plus 19% energy savings on VGG distillation, and 3.5x speedup plus 29% energy savings on ResNet distillation, both with negligible accuracy loss. The speedup of ResNet distillation can be further improved to 3.87 when using four RTX6000 GPUs in a distributed cluster.