 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Finetuner's Fallacy: When to Pretrain with Your Finetuning Data
Mar 17, 2026Real-world model deployments demand strong performance on narrow domains where data is often scarce. Typically, practitioners finetune models to specialize them, but this risks overfitting to the domain and forgetting general knowledge. We study a simple strategy, specialized pretraining (SPT), where a small domain dataset, typically reserved for finetuning, is repeated starting from pretraining as a fraction of the total tokens. Across three specialized domains (ChemPile, MusicPile, and ProofPile), SPT improves domain performance and preserves general capabilities after finetuning compared to standard pretraining. In our experiments, SPT reduces the pretraining tokens needed to reach a given domain performance by up to 1.75x. These gains grow when the target domain is underrepresented in the pretraining corpus: on domains far from web text, a 1B SPT model outperforms a 3B standard pretrained model. Beyond these empirical gains, we derive overfitting scaling laws to guide practitioners in selecting the optimal domain-data repetition for a given pretraining compute budget. Our observations reveal the finetuner's fallacy: while finetuning may appear to be the cheapest path to domain adaptation, introducing specialized domain data during pretraining stretches its utility. SPT yields better specialized domain performance (via reduced overfitting across repeated exposures) and better general domain performance (via reduced forgetting during finetuning), ultimately achieving stronger results with fewer parameters and less total compute when amortized over inference. To get the most out of domain data, incorporate it as early in training as possible.
ÜberWeb: Insights from Multilingual Curation for a 20-Trillion-Token Dataset
Feb 16, 2026Multilinguality is a core capability for modern foundation models, yet training high-quality multilingual models remains challenging due to uneven data availability across languages. A further challenge is the performance interference that can arise from joint multilingual training, commonly referred to as the "curse of multilinguality". We study multilingual data curation across thirteen languages and find that many reported regressions are not inherent to multilingual scaling but instead stem from correctable deficiencies in data quality and composition rather than fundamental capacity limits. In controlled bilingual experiments, improving data quality for any single language benefits others: curating English improves non-English performance in 12 of 13 languages, while curating non-English yields reciprocal improvements in English. Bespoke per-language curation produces substantially larger within-language improvements. Extending these findings to large-scale general-purpose training mixtures, we show that curated multilingual allocations comprising under 8% of total tokens remain remarkably effective. We operationalize this approach within an effort that produced a 20T-token pretraining corpus derived entirely from public sources. Models with 3B and 8B parameters trained on a 1T-token random subset achieve competitive multilingual accuracy with 4-10x fewer training FLOPs than strong public baselines, establishing a new Pareto frontier in multilingual performance versus compute. Moreover, these benefits extend to frontier model scale: the 20T-token corpus served as part of the pretraining dataset for Trinity Large (400B/A13B), which exhibits strong multilingual performance relative to its training FLOPs. These results show that targeted, per-language data curation mitigates multilingual interference and enables compute-efficient multilingual scaling.
DatBench: Discriminative, Faithful, and Efficient VLM Evaluations
Jan 05, 2026Empirical evaluation serves as the primary compass guiding research progress in foundation models. Despite a large body of work focused on training frontier vision-language models (VLMs), approaches to their evaluation remain nascent. To guide their maturation, we propose three desiderata that evaluations should satisfy: (1) faithfulness to the modality and application, (2) discriminability between models of varying quality, and (3) efficiency in compute. Through this lens, we identify critical failure modes that violate faithfulness and discriminability, misrepresenting model capabilities: (i) multiple-choice formats reward guessing, poorly reflect downstream use cases, and saturate early as models improve; (ii) blindly solvable questions, which can be answered without images, constitute up to 70% of some evaluations; and (iii) mislabeled or ambiguous samples compromise up to 42% of examples in certain datasets. Regarding efficiency, the computational burden of evaluating frontier models has become prohibitive: by some accounts, nearly 20% of development compute is devoted to evaluation alone. Rather than discarding existing benchmarks, we curate them via transformation and filtering to maximize fidelity and discriminability. We find that converting multiple-choice questions to generative tasks reveals sharp capability drops of up to 35%. In addition, filtering blindly solvable and mislabeled samples improves discriminative power while simultaneously reducing computational cost. We release DatBench-Full, a cleaned evaluation suite of 33 datasets spanning nine VLM capabilities, and DatBench, a discriminative subset that achieves 13x average speedup (up to 50x) while closely matching the discriminative power of the original datasets. Our work outlines a path toward evaluation practices that are both rigorous and sustainable as VLMs continue to scale.
Luxical: High-Speed Lexical-Dense Text Embeddings
Dec 11, 2025Frontier language model quality increasingly hinges on our ability to organize web-scale text corpora for training. Today's dominant tools trade off speed and flexibility: lexical classifiers (e.g., FastText) are fast but limited to producing classification output scores, while the vector-valued outputs of transformer text embedding models flexibly support numerous workflows (e.g., clustering, classification, and retrieval) but are computationally expensive to produce. We introduce Luxical, a library for high-speed "lexical-dense" text embeddings that aims to recover the best properties of both approaches for web-scale text organization. Luxical combines sparse TF--IDF features, a small ReLU network, and a knowledge distillation training regimen to approximate large transformer embedding models at a fraction of their operational cost. In this technical report, we describe the Luxical architecture and training objective and evaluate a concrete Luxical model in two disparate applications: a targeted webcrawl document retrieval test and an end-to-end language model data curation task grounded in text classification. In these tasks we demonstrate speedups ranging from 3x to 100x over varying-sized neural baselines, and comparable to FastText model inference during the data curation task. On these evaluations, the tested Luxical model illustrates favorable compute/quality trade-offs for large-scale text organization, matching the quality of neural baselines. Luxical is available as open-source software at https://github.com/datologyai/luxical.
Does your data spark joy? Performance gains from domain upsampling at the end of training
Jun 05, 2024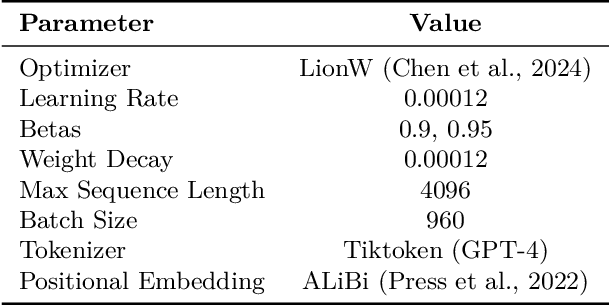
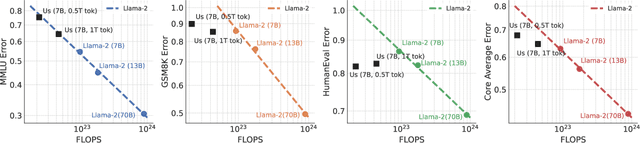

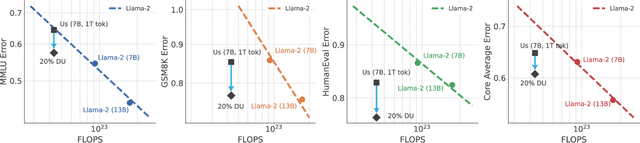
Pretraining datasets for large language models (LLMs) have grown to trillions of tokens composed of large amounts of CommonCrawl (CC) web scrape along with smaller, domain-specific datasets. It is expensive to understand the impact of these domain-specific datasets on model capabilities as training at large FLOP scales is required to reveal significant changes to difficult and emergent benchmarks. Given the increasing cost of experimenting with pretraining data, how does one determine the optimal balance between the diversity in general web scrapes and the information density of domain specific data? In this work, we show how to leverage the smaller domain specific datasets by upsampling them relative to CC at the end of training to drive performance improvements on difficult benchmarks. This simple technique allows us to improve up to 6.90 pp on MMLU, 8.26 pp on GSM8K, and 6.17 pp on HumanEval relative to the base data mix for a 7B model trained for 1 trillion (T) tokens, thus rivaling Llama-2 (7B)$\unicode{x2014}$a model trained for twice as long. We experiment with ablating the duration of domain upsampling from 5% to 30% of training and find that 10% to 20% percent is optimal for navigating the tradeoff between general language modeling capabilities and targeted benchmarks. We also use domain upsampling to characterize at scale the utility of individual datasets for improving various benchmarks by removing them during this final phase of training. This tool opens up the ability to experiment with the impact of different pretraining datasets at scale, but at an order of magnitude lower cost compared to full pretraining runs.
Perplexed by Perplexity: Perplexity-Based Data Pruning With Small Reference Models
May 30, 2024In this work, we investigate whether small language models can determine high-quality subsets of large-scale text datasets that improve the performance of larger language models. While existing work has shown that pruning based on the perplexity of a larger model can yield high-quality data, we investigate whether smaller models can be used for perplexity-based pruning and how pruning is affected by the domain composition of the data being pruned. We demonstrate that for multiple dataset compositions, perplexity-based pruning of pretraining data can \emph{significantly} improve downstream task performance: pruning based on perplexities computed with a 125 million parameter model improves the average performance on downstream tasks of a 3 billion parameter model by up to 2.04 and achieves up to a $1.45\times$ reduction in pretraining steps to reach commensurate baseline performance. Furthermore, we demonstrate that such perplexity-based data pruning also yields downstream performance gains in the over-trained and data-constrained regimes.
LoRA Learns Less and Forgets Less
May 15, 2024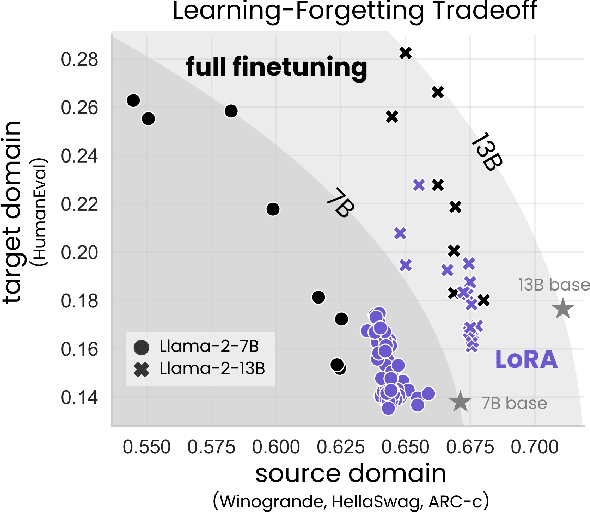

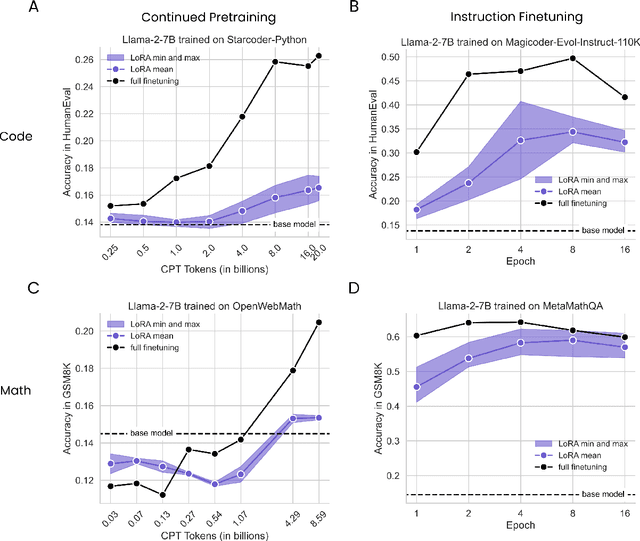

Low-Rank Adaptation (LoRA) is a widely-used parameter-efficient finetuning method for large language models. LoRA saves memory by training only low rank perturbations to selected weight matrices. In this work, we compare the performance of LoRA and full finetuning on two target domains, programming and mathematics. We consider both the instruction finetuning ($\approx$100K prompt-response pairs) and continued pretraining ($\approx$10B unstructured tokens) data regimes. Our results show that, in most settings, LoRA substantially underperforms full finetuning. Nevertheless, LoRA exhibits a desirable form of regularization: it better maintains the base model's performance on tasks outside the target domain. We show that LoRA provides stronger regularization compared to common techniques such as weight decay and dropout; it also helps maintain more diverse generations. We show that full finetuning learns perturbations with a rank that is 10-100X greater than typical LoRA configurations, possibly explaining some of the reported gaps. We conclude by proposing best practices for finetuning with LoRA.
Reduce, Reuse, Recycle: Improving Training Efficiency with Distillation
Nov 01, 2022Methods for improving the efficiency of deep network training (i.e. the resources required to achieve a given level of model quality) are of immediate benefit to deep learning practitioners. Distillation is typically used to compress models or improve model quality, but it's unclear if distillation actually improves training efficiency. Can the quality improvements of distillation be converted into training speed-ups, or do they simply increase final model quality with no resource savings? We conducted a series of experiments to investigate whether and how distillation can be used to accelerate training using ResNet-50 trained on ImageNet and BERT trained on C4 with a masked language modeling objective and evaluated on GLUE, using common enterprise hardware (8x NVIDIA A100). We found that distillation can speed up training by up to 1.96x in ResNet-50 trained on ImageNet and up to 1.42x on BERT when evaluated on GLUE. Furthermore, distillation for BERT yields optimal results when it is only performed for the first 20-50% of training. We also observed that training with distillation is almost always more efficient than training without distillation, even when using the poorest-quality model as a teacher, in both ResNet-50 and BERT. Finally, we found that it's possible to gain the benefit of distilling from an ensemble of teacher models, which has O(n) runtime cost, by randomly sampling a single teacher from the pool of teacher models on each step, which only has a O(1) runtime cost. Taken together, these results show that distillation can substantially improve training efficiency in both image classification and language modeling, and that a few simple optimizations to distillation protocols can further enhance these efficiency improvements.
Measure Twice, Cut Once: Quantifying Bias and Fairness in Deep Neural Networks
Oct 08, 2021
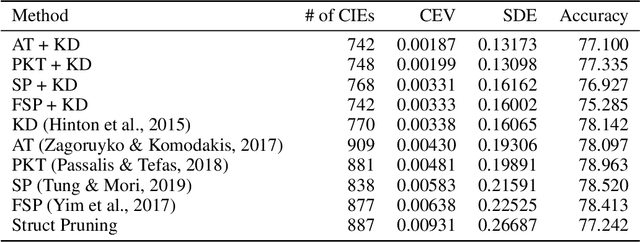
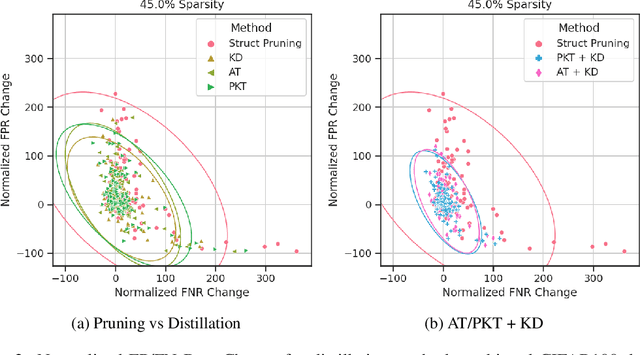
Algorithmic bias is of increasing concern, both to the research community, and society at large. Bias in AI is more abstract and unintuitive than traditional forms of discrimination and can be more difficult to detect and mitigate. A clear gap exists in the current literature on evaluating the relative bias in the performance of multi-class classifiers. In this work, we propose two simple yet effective metrics, Combined Error Variance (CEV) and Symmetric Distance Error (SDE), to quantitatively evaluate the class-wise bias of two models in comparison to one another. By evaluating the performance of these new metrics and by demonstrating their practical application, we show that they can be used to measure fairness as well as bias. These demonstrations show that our metrics can address specific needs for measuring bias in multi-class classification.
Simon Says: Evaluating and Mitigating Bias in Pruned Neural Networks with Knowledge Distillation
Jun 15, 2021
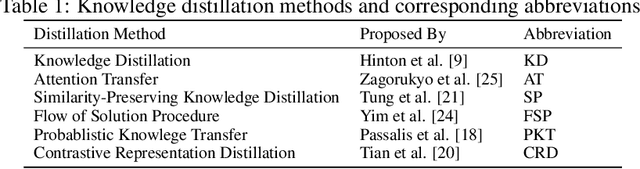
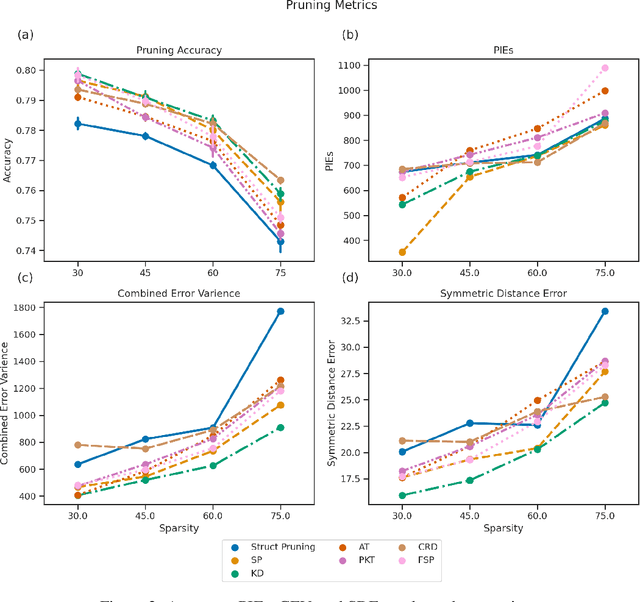
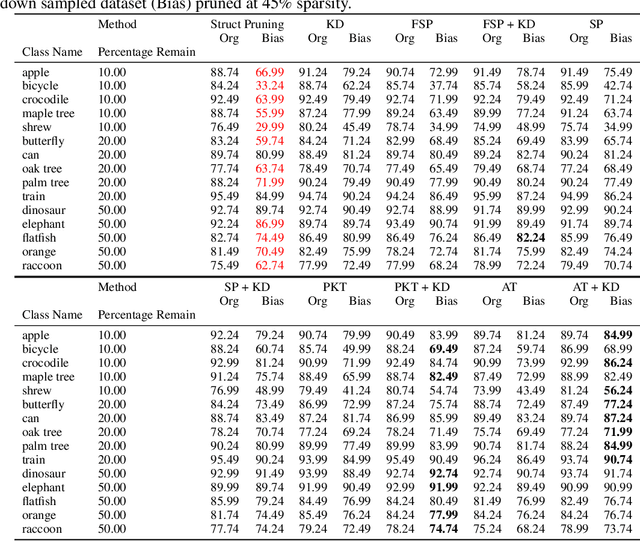
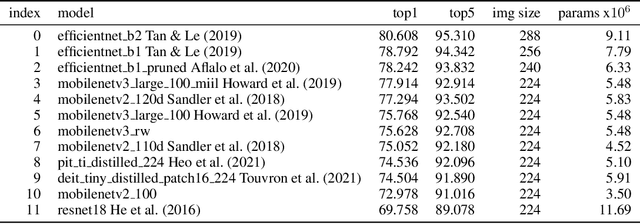
In recent years the ubiquitous deployment of AI has posed great concerns in regards to algorithmic bias, discrimination, and fairness. Compared to traditional forms of bias or discrimination caused by humans, algorithmic bias generated by AI is more abstract and unintuitive therefore more difficult to explain and mitigate. A clear gap exists in the current literature on evaluating and mitigating bias in pruned neural networks. In this work, we strive to tackle the challenging issues of evaluating, mitigating, and explaining induced bias in pruned neural networks. Our paper makes three contributions. First, we propose two simple yet effective metrics, Combined Error Variance (CEV) and Symmetric Distance Error (SDE), to quantitatively evaluate the induced bias prevention quality of pruned models. Second, we demonstrate that knowledge distillation can mitigate induced bias in pruned neural networks, even with unbalanced datasets. Third, we reveal that model similarity has strong correlations with pruning induced bias, which provides a powerful method to explain why bias occurs in pruned neural networks. Our code is available at https://github.com/codestar12/pruning-distilation-bias