 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLessons from the Trenches on Reproducible Evaluation of Language Models
May 23, 2024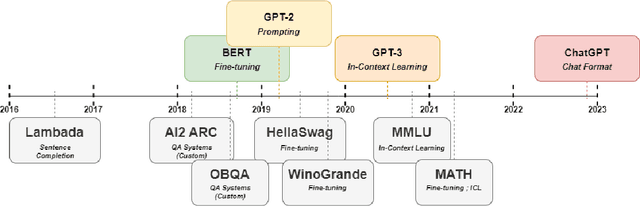
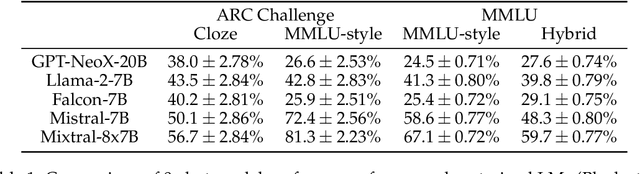
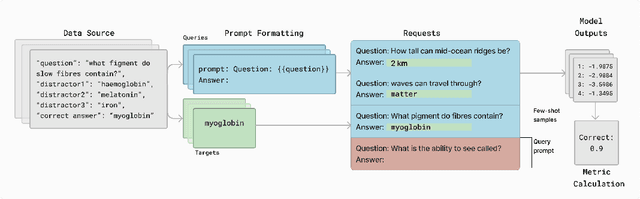

Effective evaluation of language models remains an open challenge in NLP. Researchers and engineers face methodological issues such as the sensitivity of models to evaluation setup, difficulty of proper comparisons across methods, and the lack of reproducibility and transparency. In this paper we draw on three years of experience in evaluating large language models to provide guidance and lessons for researchers. First, we provide an overview of common challenges faced in language model evaluation. Second, we delineate best practices for addressing or lessening the impact of these challenges on research. Third, we present the Language Model Evaluation Harness (lm-eval): an open source library for independent, reproducible, and extensible evaluation of language models that seeks to address these issues. We describe the features of the library as well as case studies in which the library has been used to alleviate these methodological concerns.
Surveying (Dis)Parities and Concerns of Compute Hungry NLP Research
Jun 29, 2023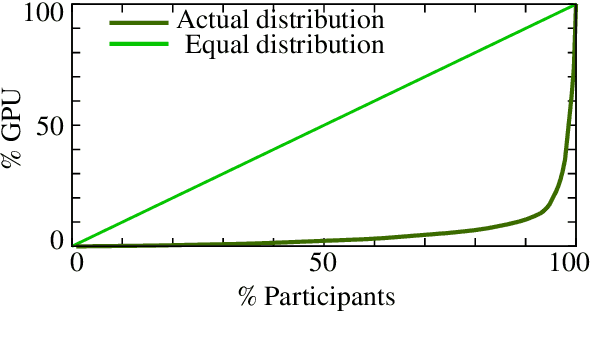

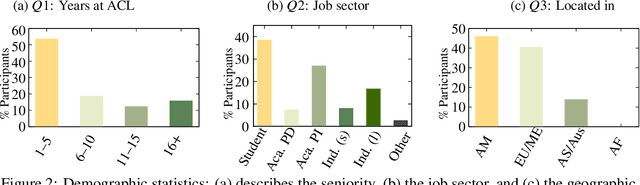
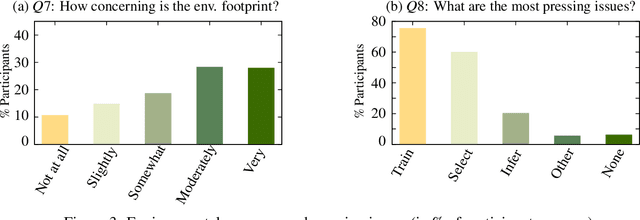
Many recent improvements in NLP stem from the development and use of large pre-trained language models (PLMs) with billions of parameters. Large model sizes makes computational cost one of the main limiting factors for training and evaluating such models; and has raised severe concerns about the sustainability, reproducibility, and inclusiveness for researching PLMs. These concerns are often based on personal experiences and observations. However, there had not been any large-scale surveys that investigate them. In this work, we provide a first attempt to quantify these concerns regarding three topics, namely, environmental impact, equity, and impact on peer reviewing. By conducting a survey with 312 participants from the NLP community, we capture existing (dis)parities between different and within groups with respect to seniority, academia, and industry; and their impact on the peer reviewing process. For each topic, we provide an analysis and devise recommendations to mitigate found disparities, some of which already successfully implemented. Finally, we discuss additional concerns raised by many participants in free-text responses.
Prompting Multilingual Large Language Models to Generate Code-Mixed Texts: The Case of South East Asian Languages
Mar 30, 2023



While code-mixing is a common linguistic practice in many parts of the world, collecting high-quality and low-cost code-mixed data remains a challenge for natural language processing (NLP) research. The proliferation of Large Language Models (LLMs) in recent times compels one to ask: can these systems be used for data generation? In this article, we explore prompting multilingual LLMs in a zero-shot manner to create code-mixed data for five languages in South East Asia (SEA) -- Indonesian, Malay, Chinese, Tagalog, Vietnamese, as well as the creole language Singlish. We find that ChatGPT shows the most potential, capable of producing code-mixed text 68% of the time when the term "code-mixing" is explicitly defined. Moreover, both ChatGPT's and InstructGPT's (davinci-003) performances in generating Singlish texts are noteworthy, averaging a 96% success rate across a variety of prompts. Their code-mixing proficiency, however, is dampened by word choice errors that lead to semantic inaccuracies. Other multilingual models such as BLOOMZ and Flan-T5-XXL are unable to produce code-mixed texts altogether. By highlighting the limited promises of LLMs in a specific form of low-resource data generation, we call for a measured approach when applying similar techniques to other data-scarce NLP contexts.
Evaluation Beyond Task Performance: Analyzing Concepts in AlphaZero in Hex
Nov 26, 2022AlphaZero, an approach to reinforcement learning that couples neural networks and Monte Carlo tree search (MCTS), has produced state-of-the-art strategies for traditional board games like chess, Go, shogi, and Hex. While researchers and game commentators have suggested that AlphaZero uses concepts that humans consider important, it is unclear how these concepts are captured in the network. We investigate AlphaZero's internal representations in the game of Hex using two evaluation techniques from natural language processing (NLP): model probing and behavioral tests. In doing so, we introduce new evaluation tools to the RL community and illustrate how evaluations other than task performance can be used to provide a more complete picture of a model's strengths and weaknesses. Our analyses in the game of Hex reveal interesting patterns and generate some testable hypotheses about how such models learn in general. For example, we find that MCTS discovers concepts before the neural network learns to encode them. We also find that concepts related to short-term end-game planning are best encoded in the final layers of the model, whereas concepts related to long-term planning are encoded in the middle layers of the model.
One Venue, Two Conferences: The Separation of Chinese and American Citation Networks
Nov 17, 2022At NeurIPS, American and Chinese institutions cite papers from each other's regions substantially less than they cite endogamously. We build a citation graph to quantify this divide, compare it to European connectivity, and discuss the causes and consequences of the separation.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Reduce, Reuse, Recycle: Improving Training Efficiency with Distillation
Nov 01, 2022Methods for improving the efficiency of deep network training (i.e. the resources required to achieve a given level of model quality) are of immediate benefit to deep learning practitioners. Distillation is typically used to compress models or improve model quality, but it's unclear if distillation actually improves training efficiency. Can the quality improvements of distillation be converted into training speed-ups, or do they simply increase final model quality with no resource savings? We conducted a series of experiments to investigate whether and how distillation can be used to accelerate training using ResNet-50 trained on ImageNet and BERT trained on C4 with a masked language modeling objective and evaluated on GLUE, using common enterprise hardware (8x NVIDIA A100). We found that distillation can speed up training by up to 1.96x in ResNet-50 trained on ImageNet and up to 1.42x on BERT when evaluated on GLUE. Furthermore, distillation for BERT yields optimal results when it is only performed for the first 20-50% of training. We also observed that training with distillation is almost always more efficient than training without distillation, even when using the poorest-quality model as a teacher, in both ResNet-50 and BERT. Finally, we found that it's possible to gain the benefit of distilling from an ensemble of teacher models, which has O(n) runtime cost, by randomly sampling a single teacher from the pool of teacher models on each step, which only has a O(1) runtime cost. Taken together, these results show that distillation can substantially improve training efficiency in both image classification and language modeling, and that a few simple optimizations to distillation protocols can further enhance these efficiency improvements.
Strengthening Subcommunities: Towards Sustainable Growth in AI Research
Apr 18, 2022AI's rapid growth has been felt acutely by scholarly venues, leading to growing pains within the peer review process. These challenges largely center on the inability of specific subareas to identify and evaluate work that is appropriate according to criteria relevant to each subcommunity as determined by stakeholders of that subarea. We set forth a proposal that re-focuses efforts within these subcommunities through a decentralization of the reviewing and publication process. Through this re-centering effort, we hope to encourage each subarea to confront the issues specific to their process of academic publication and incentivization. This model has historically been successful for several subcommunities in AI, and we highlight those instances as examples for how the broader field can continue to evolve despite its continually growing size.
TOKCS: Tool for Organizing Key Characteristics of VAM-HRI Systems
Aug 07, 2021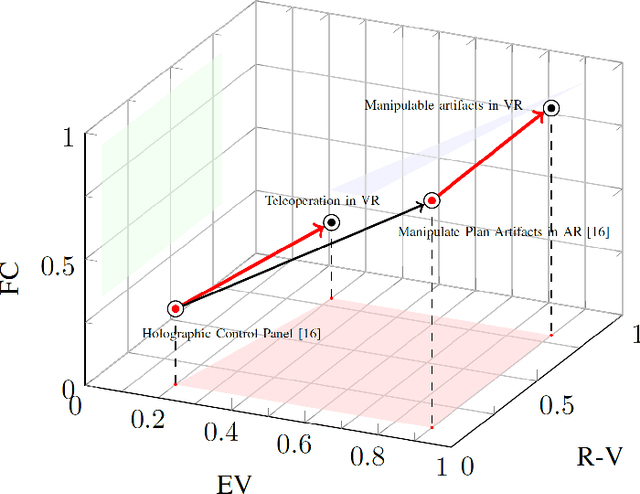

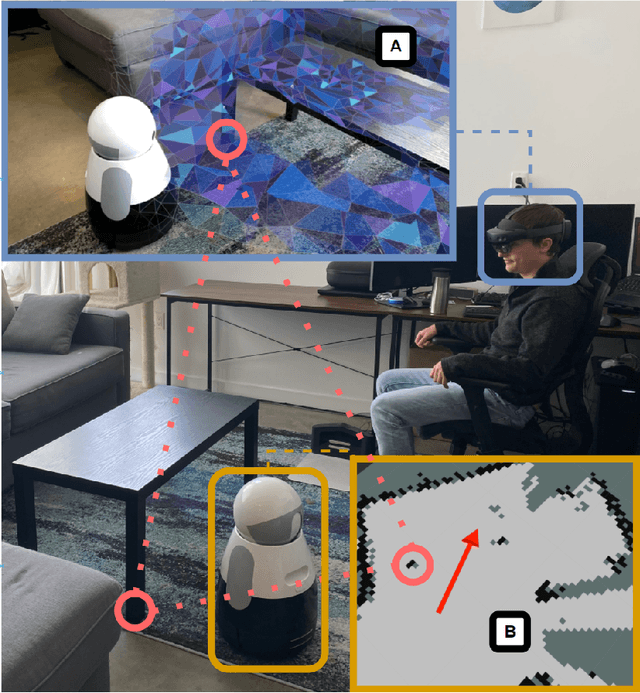

Frameworks have begun to emerge to categorize Virtual, Augmented, and Mixed Reality (VAM) technologies that provide immersive, intuitive interfaces to facilitate Human-Robot Interaction. These frameworks, however, fail to capture key characteristics of the growing subfield of VAM-HRI and can be difficult to consistently apply. This work builds upon these prior frameworks through the creation of a Tool for Organizing Key Characteristics of VAM-HRI Systems (TOKCS). TOKCS discretizes the continuous scales used within prior works for more consistent classification and adds additional characteristics related to a robot's internal model, anchor locations, manipulability, and the system's software and hardware. To showcase the tool's capability, TOKCS is applied to find trends and takeaways from the fourth VAM-HRI workshop. These trends highlight the expressive capability of TOKCS while also helping frame newer trends and future work recommendations for VAM-HRI research.
Model Selection's Disparate Impact in Real-World Deep Learning Applications
Apr 01, 2021
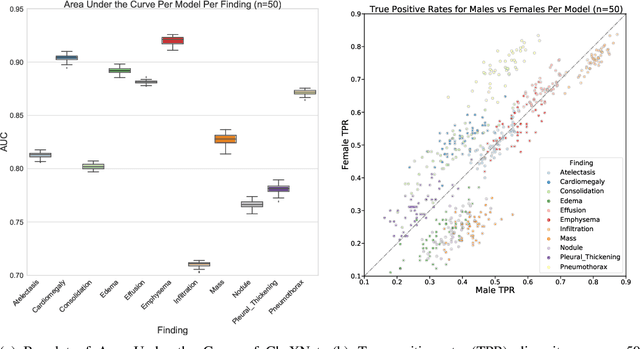
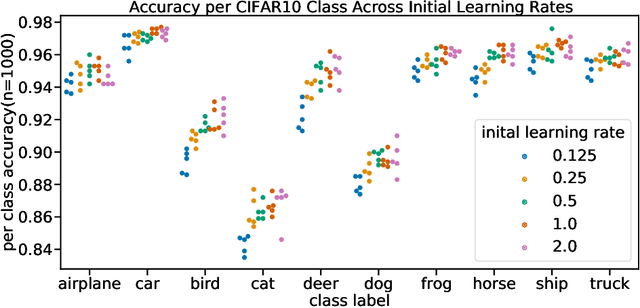
Algorithmic fairness has emphasized the role of biased data in automated decision outcomes. Recently, there has been a shift in attention to sources of bias that implicate fairness in other stages in the ML pipeline. We contend that one source of such bias, human preferences in model selection, remains under-explored in terms of its role in disparate impact across demographic groups. Using a deep learning model trained on real-world medical imaging data, we verify our claim empirically and argue that choice of metric for model comparison can significantly bias model selection outcomes.