 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuthorMix: Modular Authorship Style Transfer via Layer-wise Adapter Mixing
Mar 24, 2026The task of authorship style transfer involves rewriting text in the style of a target author while preserving the meaning of the original text. Existing style transfer methods train a single model on large corpora to model all target styles at once: this high-cost approach offers limited flexibility for target-specific adaptation, and often sacrifices meaning preservation for style transfer. In this paper, we propose AuthorMix: a lightweight, modular, and interpretable style transfer framework. We train individual, style-specific LoRA adapters on a small set of high-resource authors, allowing the rapid training of specialized adaptation models for each new target via learned, layer-wise adapter mixing, using only a handful of target style training examples. AuthorMix outperforms existing, SoTA style-transfer baselines -- as well as GPT-5.1 -- for low-resource targets, achieving the highest overall score and substantially improving meaning preservation.
Bridging Fairness and Explainability: Can Input-Based Explanations Promote Fairness in Hate Speech Detection?
Sep 26, 2025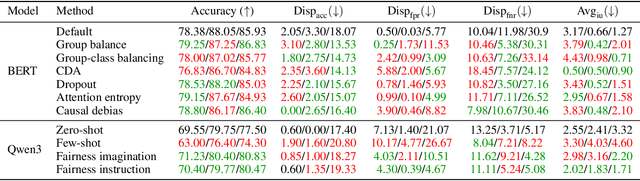
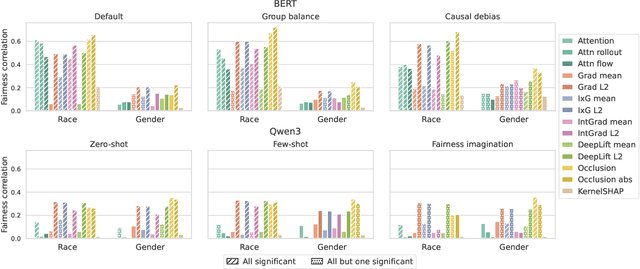
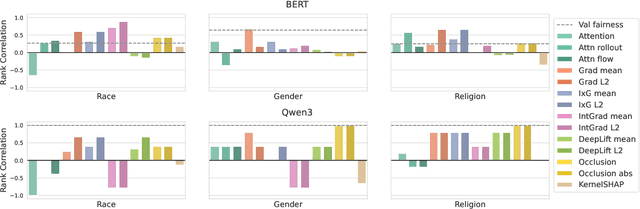

Natural language processing (NLP) models often replicate or amplify social bias from training data, raising concerns about fairness. At the same time, their black-box nature makes it difficult for users to recognize biased predictions and for developers to effectively mitigate them. While some studies suggest that input-based explanations can help detect and mitigate bias, others question their reliability in ensuring fairness. Existing research on explainability in fair NLP has been predominantly qualitative, with limited large-scale quantitative analysis. In this work, we conduct the first systematic study of the relationship between explainability and fairness in hate speech detection, focusing on both encoder- and decoder-only models. We examine three key dimensions: (1) identifying biased predictions, (2) selecting fair models, and (3) mitigating bias during model training. Our findings show that input-based explanations can effectively detect biased predictions and serve as useful supervision for reducing bias during training, but they are unreliable for selecting fair models among candidates.
B-cos LM: Efficiently Transforming Pre-trained Language Models for Improved Explainability
Feb 18, 2025Post-hoc explanation methods for black-box models often struggle with faithfulness and human interpretability due to the lack of explainability in current neural models. Meanwhile, B-cos networks have been introduced to improve model explainability through architectural and computational adaptations, but their application has so far been limited to computer vision models and their associated training pipelines. In this work, we introduce B-cos LMs, i.e., B-cos networks empowered for NLP tasks. Our approach directly transforms pre-trained language models into B-cos LMs by combining B-cos conversion and task fine-tuning, improving efficiency compared to previous B-cos methods. Our automatic and human evaluation results demonstrate that B-cos LMs produce more faithful and human interpretable explanations than post hoc methods, while maintaining task performance comparable to conventional fine-tuning. Our in-depth analysis explores how B-cos LMs differ from conventionally fine-tuned models in their learning processes and explanation patterns. Finally, we provide practical guidelines for effectively building B-cos LMs based on our findings. Our code is available at https://anonymous.4open.science/r/bcos_lm.
Constrained C-Test Generation via Mixed-Integer Programming
Apr 12, 2024
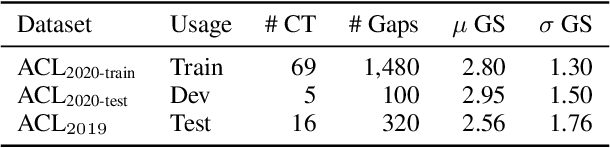
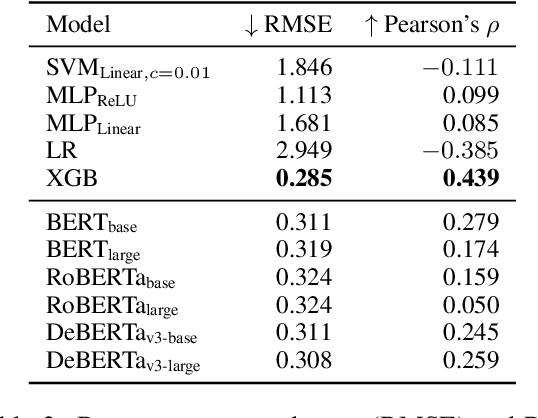

This work proposes a novel method to generate C-Tests; a deviated form of cloze tests (a gap filling exercise) where only the last part of a word is turned into a gap. In contrast to previous works that only consider varying the gap size or gap placement to achieve locally optimal solutions, we propose a mixed-integer programming (MIP) approach. This allows us to consider gap size and placement simultaneously, achieving globally optimal solutions, and to directly integrate state-of-the-art models for gap difficulty prediction into the optimization problem. A user study with 40 participants across four C-Test generation strategies (including GPT-4) shows that our approach (MIP) significantly outperforms two of the baseline strategies (based on gap placement and GPT-4); and performs on-par with the third (based on gap size). Our analysis shows that GPT-4 still struggles to fulfill explicit constraints during generation and that MIP produces C-Tests that correlate best with the perceived difficulty. We publish our code, model, and collected data consisting of 32 English C-Tests with 20 gaps each (totaling 3,200 individual gap responses) under an open source license.
Surveying (Dis)Parities and Concerns of Compute Hungry NLP Research
Jun 29, 2023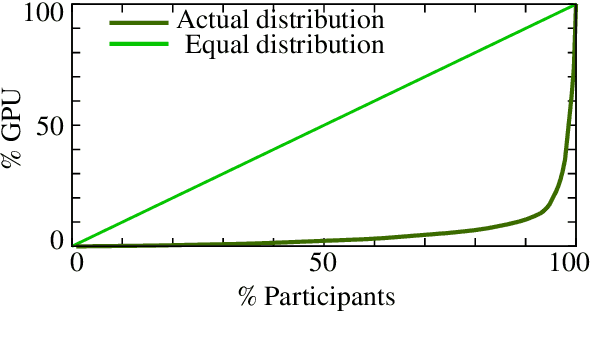

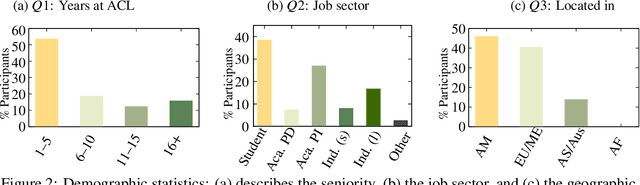
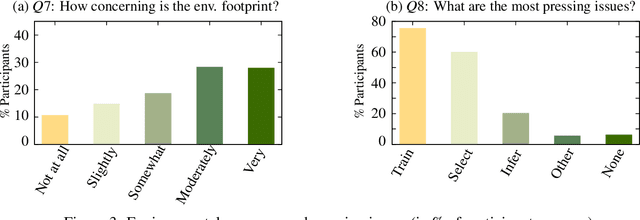
Many recent improvements in NLP stem from the development and use of large pre-trained language models (PLMs) with billions of parameters. Large model sizes makes computational cost one of the main limiting factors for training and evaluating such models; and has raised severe concerns about the sustainability, reproducibility, and inclusiveness for researching PLMs. These concerns are often based on personal experiences and observations. However, there had not been any large-scale surveys that investigate them. In this work, we provide a first attempt to quantify these concerns regarding three topics, namely, environmental impact, equity, and impact on peer reviewing. By conducting a survey with 312 participants from the NLP community, we capture existing (dis)parities between different and within groups with respect to seniority, academia, and industry; and their impact on the peer reviewing process. For each topic, we provide an analysis and devise recommendations to mitigate found disparities, some of which already successfully implemented. Finally, we discuss additional concerns raised by many participants in free-text responses.
Lessons Learned from a Citizen Science Project for Natural Language Processing
Apr 25, 2023



Many Natural Language Processing (NLP) systems use annotated corpora for training and evaluation. However, labeled data is often costly to obtain and scaling annotation projects is difficult, which is why annotation tasks are often outsourced to paid crowdworkers. Citizen Science is an alternative to crowdsourcing that is relatively unexplored in the context of NLP. To investigate whether and how well Citizen Science can be applied in this setting, we conduct an exploratory study into engaging different groups of volunteers in Citizen Science for NLP by re-annotating parts of a pre-existing crowdsourced dataset. Our results show that this can yield high-quality annotations and attract motivated volunteers, but also requires considering factors such as scalability, participation over time, and legal and ethical issues. We summarize lessons learned in the form of guidelines and provide our code and data to aid future work on Citizen Science.
Transformers with Learnable Activation Functions
Sep 01, 2022
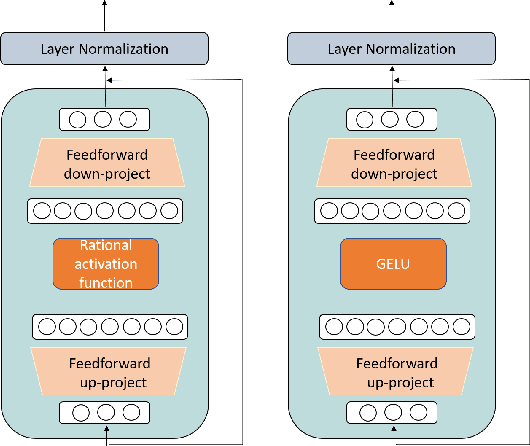

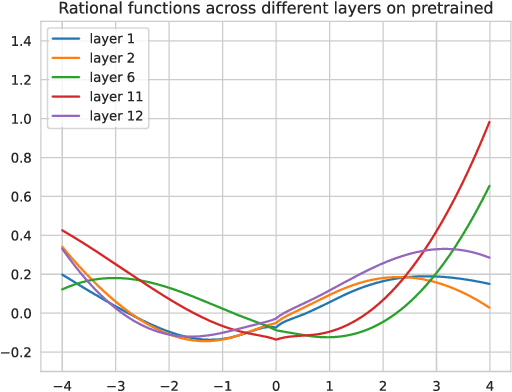
Activation functions can have a significant impact on reducing the topological complexity of input data and therefore improve the performance of the model. Selecting a suitable activation function is an essential step in neural model design. However, the choice of activation function is seldom discussed or explored in Transformer-based language models. Their activation functions are chosen beforehand and then remain fixed from pre-training to fine-tuning. As a result, the inductive biases they imposed on models cannot be adjusted during this long life cycle. Moreover, subsequently developed models (e.g., RoBERTa, BART, and GPT-3) often follow up prior work (e.g., BERT) to use the same activation function without justification. In this paper, we investigate the effectiveness of using Rational Activation Function (RAF), a learnable activation function, in the Transformer architecture. In contrast to conventional, predefined activation functions, RAFs can adaptively learn optimal activation functions during training according to input data. Our experiments show the RAF-based Transformer (RAFT) achieves a lower validation perplexity than a vanilla BERT with the GELU function. We further evaluate RAFT on downstream tasks in low- and full-data settings. Our results show that RAFT outperforms the counterpart model across the majority of tasks and settings. For instance, RAFT outperforms vanilla BERT on the GLUE benchmark by 5.71 points on average in low-data scenario (where 100 training examples are available) and by 2.05 points on SQuAD in full-data setting. Analysis of the shapes of learned RAFs further unveils that they substantially vary between different layers of the pre-trained model and mostly look very different from conventional activation functions. RAFT opens a new research direction for analyzing and interpreting pre-trained models according to the learned activation functions.
TexPrax: A Messaging Application for Ethical, Real-time Data Collection and Annotation
Aug 16, 2022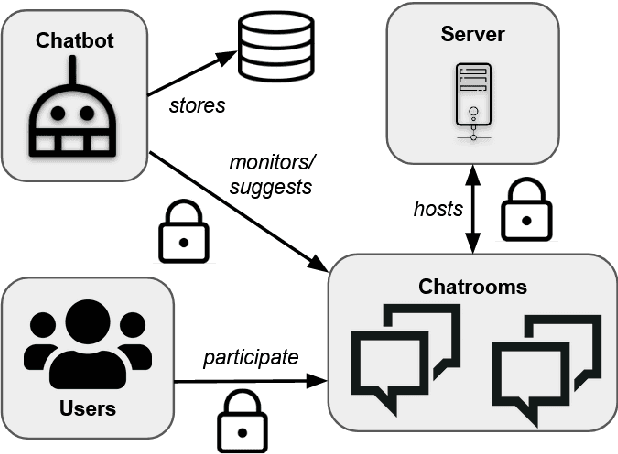
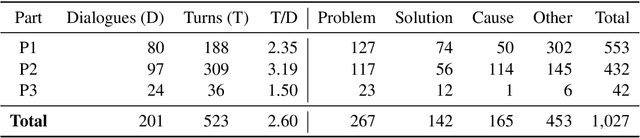
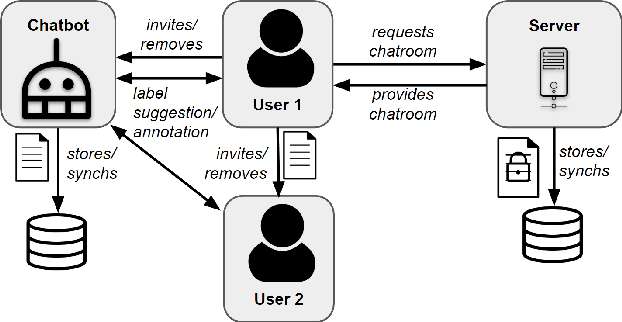
Collecting and annotating task-oriented dialog data is difficult, especially for highly specific domains that require expert knowledge. At the same time, informal communication channels such as instant messengers are increasingly being used at work. This has led to a lot of work-relevant information that is disseminated through those channels and needs to be post-processed manually by the employees. To alleviate this problem, we present TexPrax, a messaging system to collect and annotate problems, causes, and solutions that occur in work-related chats. TexPrax uses a chatbot to directly engage the employees to provide lightweight annotations on their conversation and ease their documentation work. To comply with data privacy and security regulations, we use an end-to-end message encryption and give our users full control over their data which has various advantages over conventional annotation tools. We evaluate TexPrax in a user-study with German factory employees who ask their colleagues for solutions on problems that arise during their daily work. Overall, we collect 201 task-oriented German dialogues containing 1,027 sentences with sentence-level expert annotations. Our data analysis also reveals that real-world conversations frequently contain instances with code-switching, varying abbreviations for the same entity, and dialects which NLP systems should be able to handle.
Annotation Curricula to Implicitly Train Non-Expert Annotators
Jun 09, 2021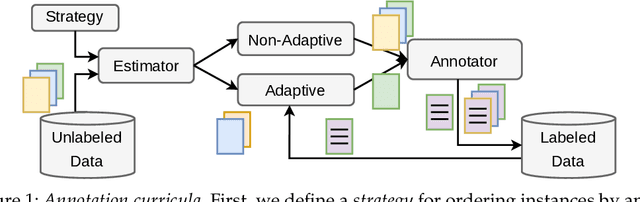

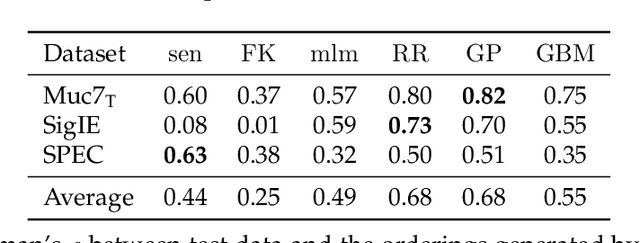
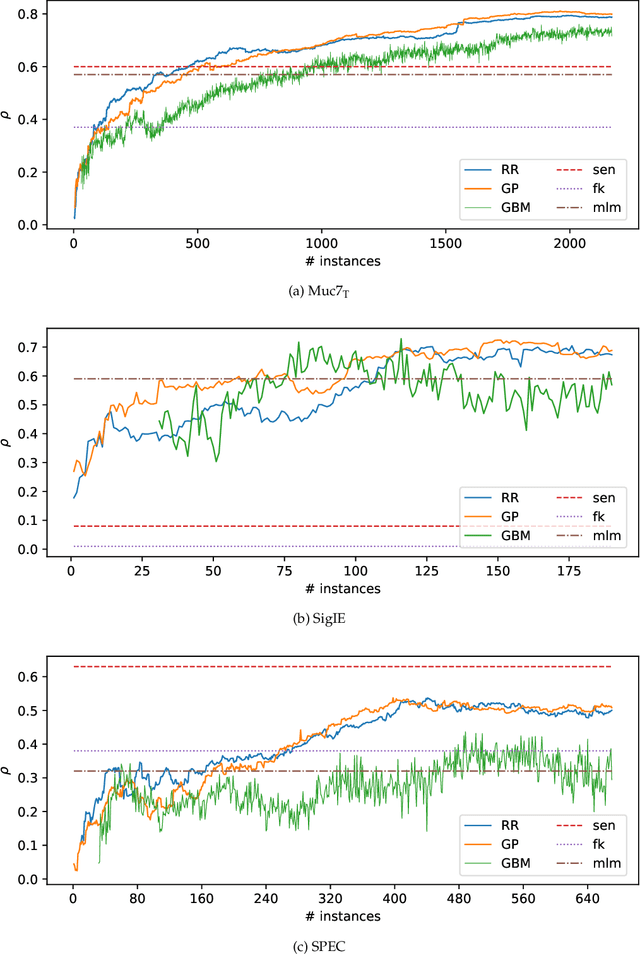
Annotation studies often require annotators to familiarize themselves with the task, its annotation scheme, and the data domain. This can be overwhelming in the beginning, mentally taxing, and induce errors into the resulting annotations; especially in citizen science or crowd sourcing scenarios where domain expertise is not required and only annotation guidelines are provided. To alleviate these issues, we propose annotation curricula, a novel approach to implicitly train annotators. Our goal is to gradually introduce annotators into the task by ordering instances that are annotated according to a learning curriculum. To do so, we first formalize annotation curricula for sentence- and paragraph-level annotation tasks, define an ordering strategy, and identify well-performing heuristics and interactively trained models on three existing English datasets. We then conduct a user study with 40 voluntary participants who are asked to identify the most fitting misconception for English tweets about the Covid-19 pandemic. Our results show that using a simple heuristic to order instances can already significantly reduce the total annotation time while preserving a high annotation quality. Annotation curricula thus can provide a novel way to improve data collection. To facilitate future research, we further share our code and data consisting of 2,400 annotations.
Investigating label suggestions for opinion mining in German Covid-19 social media
Jun 08, 2021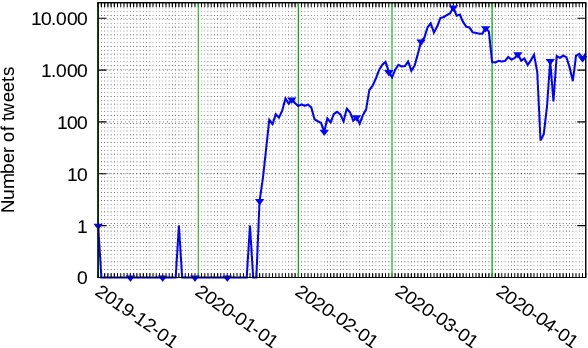
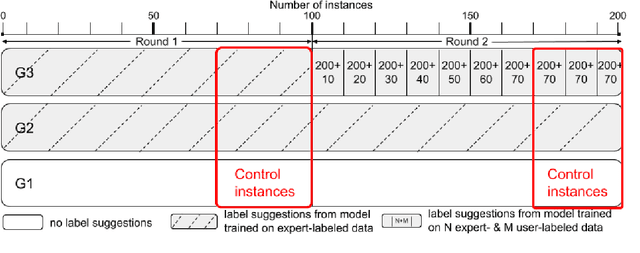
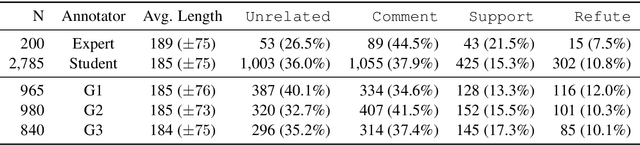
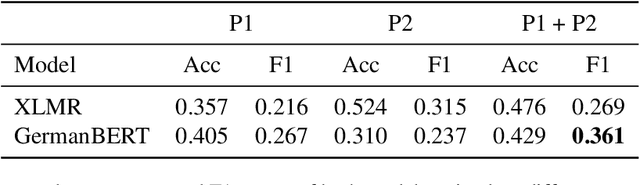
This work investigates the use of interactively updated label suggestions to improve upon the efficiency of gathering annotations on the task of opinion mining in German Covid-19 social media data. We develop guidelines to conduct a controlled annotation study with social science students and find that suggestions from a model trained on a small, expert-annotated dataset already lead to a substantial improvement - in terms of inter-annotator agreement(+.14 Fleiss' $\kappa$) and annotation quality - compared to students that do not receive any label suggestions. We further find that label suggestions from interactively trained models do not lead to an improvement over suggestions from a static model. Nonetheless, our analysis of suggestion bias shows that annotators remain capable of reflecting upon the suggested label in general. Finally, we confirm the quality of the annotated data in transfer learning experiments between different annotator groups. To facilitate further research in opinion mining on social media data, we release our collected data consisting of 200 expert and 2,785 student annotations.