 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystematic analysis of requirements for socially acceptable service robots
Sep 13, 2024In modern society, service robots are increasingly recognized for their wide range of practical applications. In large and crowded social spaces, such as museums and hospitals, these robots are required to safely move in the environment while exhibiting user-friendly behavior. Ensuring the safe and socially acceptable operation of robots in such settings presents several challenges. To enhance the social acceptance in the design process of service robots, we present a systematic analysis of requirements, categorized into functional and non-functional. These requirements are further classified into different categories, with a single requirement potentially belonging to multiple categories. Finally, considering the specific case of a receptionist robotic agent, we discuss the requirements it should possess to ensure social acceptance.
Learning from Emotions, Demographic Information and Implicit User Feedback in Task-Oriented Document-Grounded Dialogues
Jan 17, 2024The success of task-oriented and document-grounded dialogue systems depends on users accepting and enjoying using them. To achieve this, recently published work in the field of Human-Computer Interaction suggests that the combination of considering demographic information, user emotions and learning from the implicit feedback in their utterances, is particularly important. However, these findings have not yet been transferred to the field of Natural Language Processing, where these data are primarily studied separately. Accordingly, no sufficiently annotated dataset is available. To address this gap, we introduce FEDI, the first English dialogue dataset for task-oriented document-grounded dialogues annotated with demographic information, user emotions and implicit feedback. Our experiments with FLAN-T5, GPT-2 and LLaMA-2 show that these data have the potential to improve task completion and the factual consistency of the generated responses and user acceptance.
Learning From Free-Text Human Feedback -- Collect New Datasets Or Extend Existing Ones?
Oct 24, 2023Learning from free-text human feedback is essential for dialog systems, but annotated data is scarce and usually covers only a small fraction of error types known in conversational AI. Instead of collecting and annotating new datasets from scratch, recent advances in synthetic dialog generation could be used to augment existing dialog datasets with the necessary annotations. However, to assess the feasibility of such an effort, it is important to know the types and frequency of free-text human feedback included in these datasets. In this work, we investigate this question for a variety of commonly used dialog datasets, including MultiWoZ, SGD, BABI, PersonaChat, Wizards-of-Wikipedia, and the human-bot split of the Self-Feeding Chatbot. Using our observations, we derive new taxonomies for the annotation of free-text human feedback in dialogs and investigate the impact of including such data in response generation for three SOTA language generation models, including GPT-2, LLAMA, and Flan-T5. Our findings provide new insights into the composition of the datasets examined, including error types, user response types, and the relations between them.
Lessons Learned from a Citizen Science Project for Natural Language Processing
Apr 25, 2023



Many Natural Language Processing (NLP) systems use annotated corpora for training and evaluation. However, labeled data is often costly to obtain and scaling annotation projects is difficult, which is why annotation tasks are often outsourced to paid crowdworkers. Citizen Science is an alternative to crowdsourcing that is relatively unexplored in the context of NLP. To investigate whether and how well Citizen Science can be applied in this setting, we conduct an exploratory study into engaging different groups of volunteers in Citizen Science for NLP by re-annotating parts of a pre-existing crowdsourced dataset. Our results show that this can yield high-quality annotations and attract motivated volunteers, but also requires considering factors such as scalability, participation over time, and legal and ethical issues. We summarize lessons learned in the form of guidelines and provide our code and data to aid future work on Citizen Science.
Improving the Numerical Reasoning Skills of Pretrained Language Models
May 13, 2022
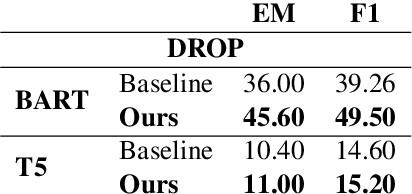
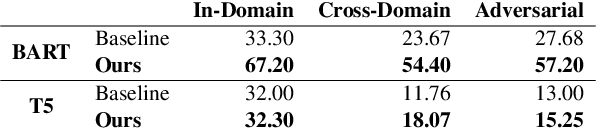
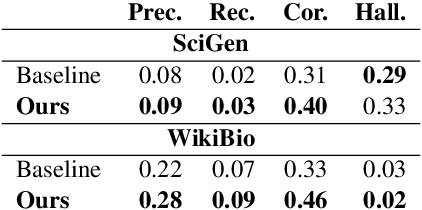
State-of-the-art pretrained language models tend to perform below their capabilities when applied out-of-the-box on tasks that require reasoning over numbers. Recent work sees two main reasons for this: (1) popular tokenisation algorithms are optimized for common words, and therefore have limited expressiveness for numbers, and (2) common pretraining objectives do not target numerical reasoning or understanding numbers at all. Recent approaches usually address them separately and mostly by proposing architectural changes or pretraining models from scratch. In this paper, we propose a new extended pretraining approach called reasoning-aware pretraining to jointly address both shortcomings without requiring architectural changes or pretraining from scratch. Using contrastive learning, our approach incorporates an alternative number representation into an already pretrained model, while improving its numerical reasoning skills by training on a novel pretraining objective called inferable number prediction task. We evaluate our approach on three different tasks that require numerical reasoning, including (a) reading comprehension in the DROP dataset, (b) inference-on-tables in the InfoTabs dataset, and (c) table-to-text generation in WikiBio and SciGen datasets. Our results on DROP and InfoTabs show that our approach improves the accuracy by 9.6 and 33.9 points on these datasets, respectively. Our human evaluation on SciGen and WikiBio shows that our approach improves the factual correctness on all datasets.