 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Numerical Reasoning Skills of Pretrained Language Models
Paper and Code

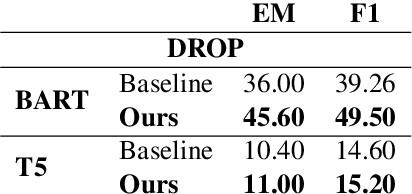
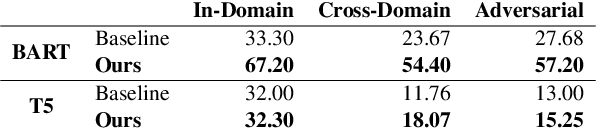
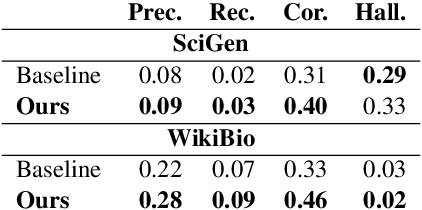
State-of-the-art pretrained language models tend to perform below their capabilities when applied out-of-the-box on tasks that require reasoning over numbers. Recent work sees two main reasons for this: (1) popular tokenisation algorithms are optimized for common words, and therefore have limited expressiveness for numbers, and (2) common pretraining objectives do not target numerical reasoning or understanding numbers at all. Recent approaches usually address them separately and mostly by proposing architectural changes or pretraining models from scratch. In this paper, we propose a new extended pretraining approach called reasoning-aware pretraining to jointly address both shortcomings without requiring architectural changes or pretraining from scratch. Using contrastive learning, our approach incorporates an alternative number representation into an already pretrained model, while improving its numerical reasoning skills by training on a novel pretraining objective called inferable number prediction task. We evaluate our approach on three different tasks that require numerical reasoning, including (a) reading comprehension in the DROP dataset, (b) inference-on-tables in the InfoTabs dataset, and (c) table-to-text generation in WikiBio and SciGen datasets. Our results on DROP and InfoTabs show that our approach improves the accuracy by 9.6 and 33.9 points on these datasets, respectively. Our human evaluation on SciGen and WikiBio shows that our approach improves the factual correctness on all datasets.