 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Course Shared Task on Evaluating LLM Output for Clinical Questions
Jul 31, 2024


This paper presents a shared task that we organized at the Foundations of Language Technology (FoLT) course in 2023/2024 at the Technical University of Darmstadt, which focuses on evaluating the output of Large Language Models (LLMs) in generating harmful answers to health-related clinical questions. We describe the task design considerations and report the feedback we received from the students. We expect the task and the findings reported in this paper to be relevant for instructors teaching natural language processing (NLP) and designing course assignments.
Learning from Emotions, Demographic Information and Implicit User Feedback in Task-Oriented Document-Grounded Dialogues
Jan 17, 2024The success of task-oriented and document-grounded dialogue systems depends on users accepting and enjoying using them. To achieve this, recently published work in the field of Human-Computer Interaction suggests that the combination of considering demographic information, user emotions and learning from the implicit feedback in their utterances, is particularly important. However, these findings have not yet been transferred to the field of Natural Language Processing, where these data are primarily studied separately. Accordingly, no sufficiently annotated dataset is available. To address this gap, we introduce FEDI, the first English dialogue dataset for task-oriented document-grounded dialogues annotated with demographic information, user emotions and implicit feedback. Our experiments with FLAN-T5, GPT-2 and LLaMA-2 show that these data have the potential to improve task completion and the factual consistency of the generated responses and user acceptance.
Dior-CVAE: Diffusion Priors in Variational Dialog Generation
May 24, 2023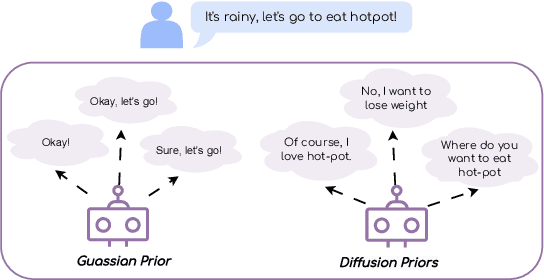
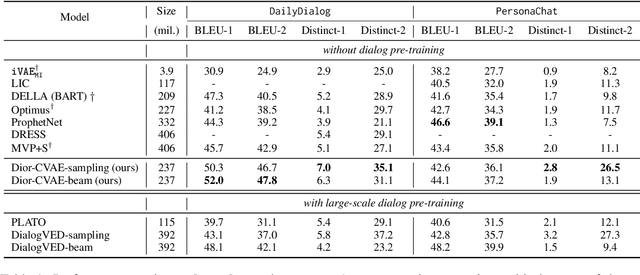
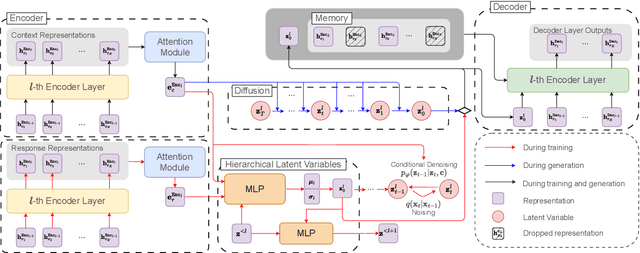
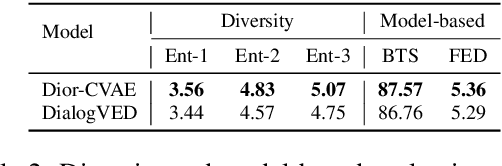
Conditional variational autoencoders (CVAEs) have been used recently for diverse response generation, by introducing latent variables to represent the relationship between a dialog context and its potential responses. However, the diversity of the generated responses brought by a CVAE model is limited due to the oversimplified assumption of the isotropic Gaussian prior. We propose, Dior-CVAE, a hierarchical CVAE model with an informative prior produced by a diffusion model. Dior-CVAE derives a series of layer-wise latent variables using attention mechanism and infusing them into decoder layers accordingly. We propose memory dropout in the latent infusion to alleviate posterior collapse. The prior distribution of the latent variables is parameterized by a diffusion model to introduce a multimodal distribution. Overall, experiments on two popular open-domain dialog datasets indicate the advantages of our approach over previous Transformer-based variational dialog models in dialog response generation. We publicly release the code for reproducing Dior-CVAE and all baselines at https://github.com/SkyFishMoon/Latent-Diffusion-Response-Generation.
The Devil is in the Details: On Models and Training Regimes for Few-Shot Intent Classification
Oct 12, 2022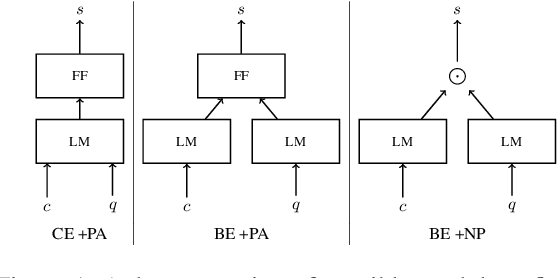
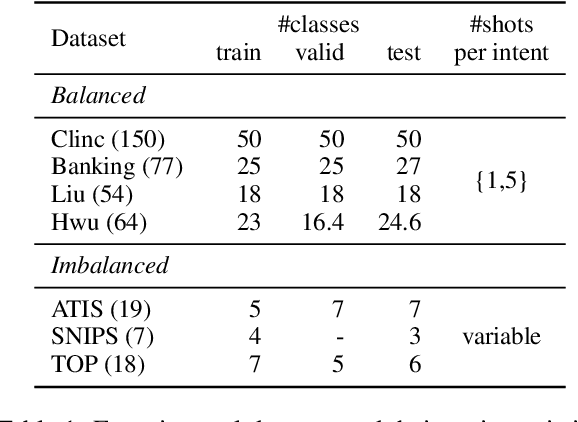
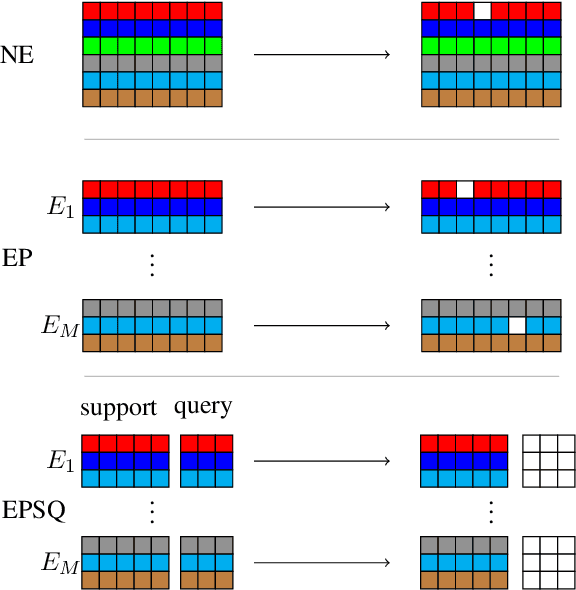
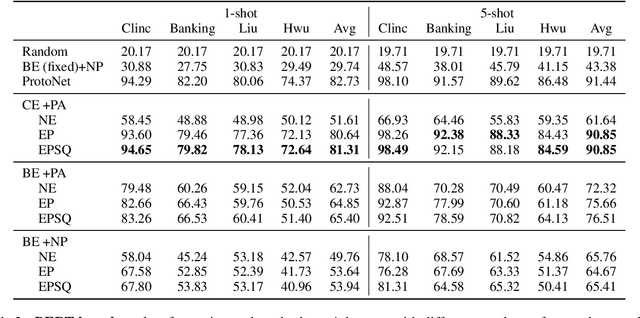
Few-shot Intent Classification (FSIC) is one of the key challenges in modular task-oriented dialog systems. While advanced FSIC methods are similar in using pretrained language models to encode texts and nearest neighbour-based inference for classification, these methods differ in details. They start from different pretrained text encoders, use different encoding architectures with varying similarity functions, and adopt different training regimes. Coupling these mostly independent design decisions and the lack of accompanying ablation studies are big obstacle to identify the factors that drive the reported FSIC performance. We study these details across three key dimensions: (1) Encoding architectures: Cross-Encoder vs Bi-Encoders; (2) Similarity function: Parameterized (i.e., trainable) functions vs non-parameterized function; (3) Training regimes: Episodic meta-learning vs the straightforward (i.e., non-episodic) training. Our experimental results on seven FSIC benchmarks reveal three important findings. First, the unexplored combination of the cross-encoder architecture (with parameterized similarity scoring function) and episodic meta-learning consistently yields the best FSIC performance. Second, Episodic training yields a more robust FSIC classifier than non-episodic one. Third, in meta-learning methods, splitting an episode to support and query sets is not a must. Our findings paves the way for conducting state-of-the-art research in FSIC and more importantly raise the community's attention to details of FSIC methods. We release our code and data publicly.
Revisiting Unsupervised Relation Extraction
Apr 30, 2020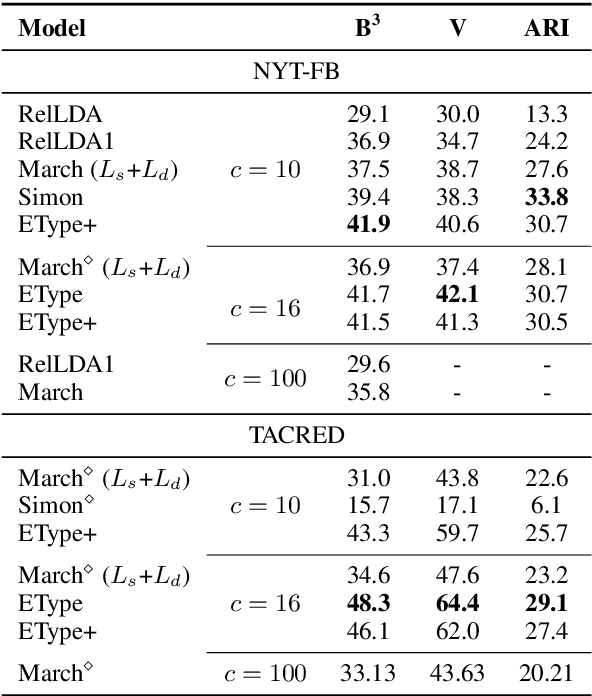
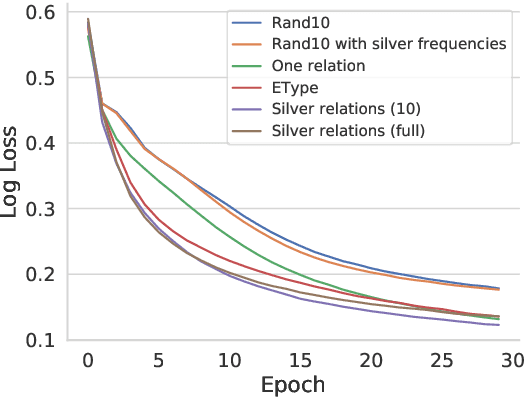
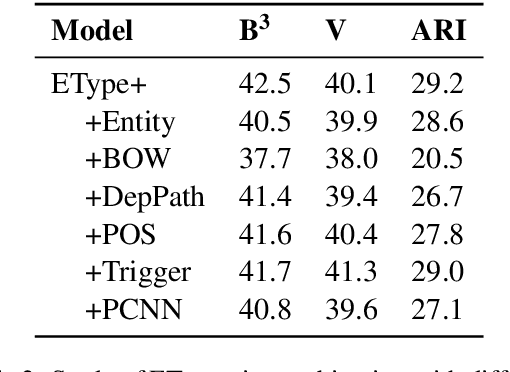
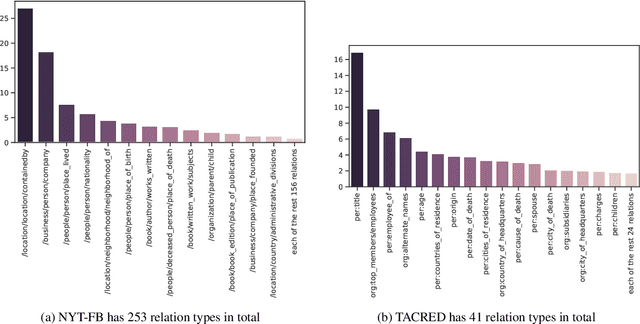
Unsupervised relation extraction (URE) extracts relations between named entities from raw text without manually-labelled data and existing knowledge bases (KBs). URE methods can be categorised into generative and discriminative approaches, which rely either on hand-crafted features or surface form. However, we demonstrate that by using only named entities to induce relation types, we can outperform existing methods on two popular datasets. We conduct a comparison and evaluation of our findings with other URE techniques, to ascertain the important features in URE. We conclude that entity types provide a strong inductive bias for URE.