 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Text Classification with LLM-Refined Taxonomies
Jan 26, 2026Hierarchical text classification (HTC) depends on taxonomies that organize labels into structured hierarchies. However, many real-world taxonomies introduce ambiguities, such as identical leaf names under similar parent nodes, which prevent language models (LMs) from learning clear decision boundaries. In this paper, we present TaxMorph, a framework that uses large language models (LLMs) to transform entire taxonomies through operations such as renaming, merging, splitting, and reordering. Unlike prior work, our method revises the full hierarchy to better match the semantics encoded by LMs. Experiments across three HTC benchmarks show that LLM-refined taxonomies consistently outperform human-curated ones in various settings up to +2.9pp. in F1. To better understand these improvements, we compare how well LMs can assign leaf nodes to parent nodes and vice versa across human-curated and LLM-refined taxonomies. We find that human-curated taxonomies lead to more easily separable clusters in embedding space. However, the LLM-refined taxonomies align more closely with the model's actual confusion patterns during classification. In other words, even though they are harder to separate, they better reflect the model's inductive biases. These findings suggest that LLM-guided refinement creates taxonomies that are more compatible with how models learn, improving HTC performance.
Multi-parameter Control for the (1+($λ$,$λ$))-GA on OneMax via Deep Reinforcement Learning
May 19, 2025It is well known that evolutionary algorithms can benefit from dynamic choices of the key parameters that control their behavior, to adjust their search strategy to the different stages of the optimization process. A prominent example where dynamic parameter choices have shown a provable super-constant speed-up is the $(1+(\lambda,\lambda))$ Genetic Algorithm optimizing the OneMax function. While optimal parameter control policies result in linear expected running times, this is not possible with static parameter choices. This result has spurred a lot of interest in parameter control policies. However, many works, in particular theoretical running time analyses, focus on controlling one single parameter. Deriving policies for controlling multiple parameters remains very challenging. In this work we reconsider the problem of the $(1+(\lambda,\lambda))$ Genetic Algorithm optimizing OneMax. We decouple its four main parameters and investigate how well state-of-the-art deep reinforcement learning techniques can approximate good control policies. We show that although making deep reinforcement learning learn effectively is a challenging task, once it works, it is very powerful and is able to find policies that outperform all previously known control policies on the same benchmark. Based on the results found through reinforcement learning, we derive a simple control policy that consistently outperforms the default theory-recommended setting by $27\%$ and the irace-tuned policy, the strongest existing control policy on this benchmark, by $13\%$, for all tested problem sizes up to $40{,}000$.
On the Importance of Reward Design in Reinforcement Learning-based Dynamic Algorithm Configuration: A Case Study on OneMax with (1+($λ$,$λ$))-GA
Feb 27, 2025Dynamic Algorithm Configuration (DAC) has garnered significant attention in recent years, particularly in the prevalence of machine learning and deep learning algorithms. Numerous studies have leveraged the robustness of decision-making in Reinforcement Learning (RL) to address the optimization challenges associated with algorithm configuration. However, making an RL agent work properly is a non-trivial task, especially in reward design, which necessitates a substantial amount of handcrafted knowledge based on domain expertise. In this work, we study the importance of reward design in the context of DAC via a case study on controlling the population size of the $(1+(\lambda,\lambda))$-GA optimizing OneMax. We observed that a poorly designed reward can hinder the RL agent's ability to learn an optimal policy because of a lack of exploration, leading to both scalability and learning divergence issues. To address those challenges, we propose the application of a reward shaping mechanism to facilitate enhanced exploration of the environment by the RL agent. Our work not only demonstrates the ability of RL in dynamically configuring the $(1+(\lambda,\lambda))$-GA, but also confirms the advantages of reward shaping in the scalability of RL agents across various sizes of OneMax problems.
DoLFIn: Distributions over Latent Features for Interpretability
Nov 10, 2020Interpreting the inner workings of neural models is a key step in ensuring the robustness and trustworthiness of the models, but work on neural network interpretability typically faces a trade-off: either the models are too constrained to be very useful, or the solutions found by the models are too complex to interpret. We propose a novel strategy for achieving interpretability that -- in our experiments -- avoids this trade-off. Our approach builds on the success of using probability as the central quantity, such as for instance within the attention mechanism. In our architecture, DoLFIn (Distributions over Latent Features for Interpretability), we do no determine beforehand what each feature represents, and features go altogether into an unordered set. Each feature has an associated probability ranging from 0 to 1, weighing its importance for further processing. We show that, unlike attention and saliency map approaches, this set-up makes it straight-forward to compute the probability with which an input component supports the decision the neural model makes. To demonstrate the usefulness of the approach, we apply DoLFIn to text classification, and show that DoLFIn not only provides interpretable solutions, but even slightly outperforms the classical CNN and BiLSTM text classifiers on the SST2 and AG-news datasets.
Revisiting Unsupervised Relation Extraction
Apr 30, 2020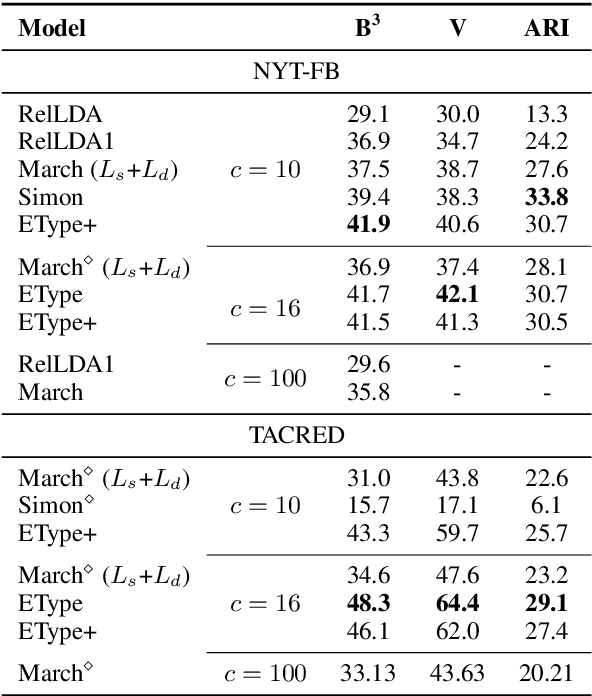
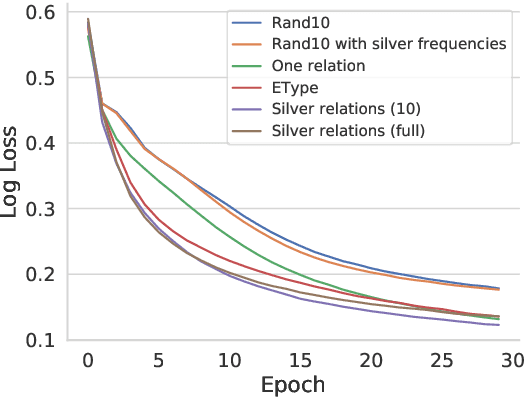
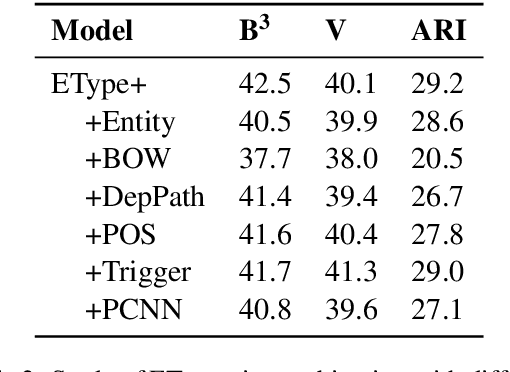
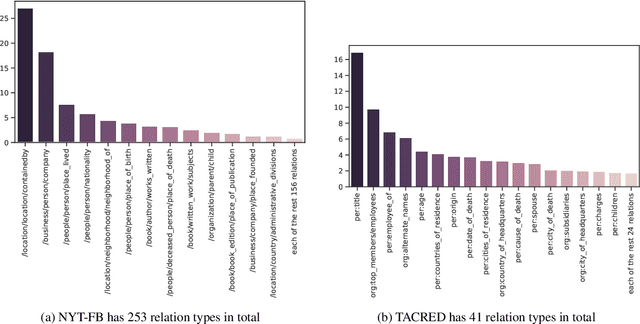
Unsupervised relation extraction (URE) extracts relations between named entities from raw text without manually-labelled data and existing knowledge bases (KBs). URE methods can be categorised into generative and discriminative approaches, which rely either on hand-crafted features or surface form. However, we demonstrate that by using only named entities to induce relation types, we can outperform existing methods on two popular datasets. We conduct a comparison and evaluation of our findings with other URE techniques, to ascertain the important features in URE. We conclude that entity types provide a strong inductive bias for URE.
Boosting Entity Linking Performance by Leveraging Unlabeled Documents
Jun 04, 2019
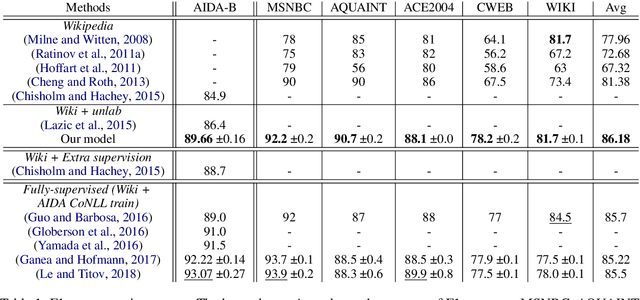

Modern entity linking systems rely on large collections of documents specifically annotated for the task (e.g., AIDA CoNLL). In contrast, we propose an approach which exploits only naturally occurring information: unlabeled documents and Wikipedia. Our approach consists of two stages. First, we construct a high recall list of candidate entities for each mention in an unlabeled document. Second, we use the candidate lists as weak supervision to constrain our document-level entity linking model. The model treats entities as latent variables and, when estimated on a collection of unlabelled texts, learns to choose entities relying both on local context of each mention and on coherence with other entities in the document. The resulting approach rivals fully-supervised state-of-the-art systems on standard test sets. It also approaches their performance in the very challenging setting: when tested on a test set sampled from the data used to estimate the supervised systems. By comparing to Wikipedia-only training of our model, we demonstrate that modeling unlabeled documents is beneficial.
Distant Learning for Entity Linking with Automatic Noise Detection
Jun 04, 2019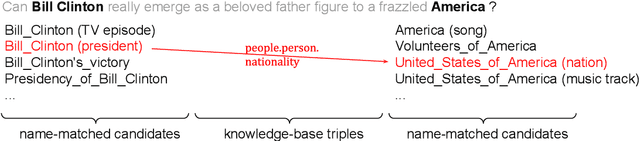
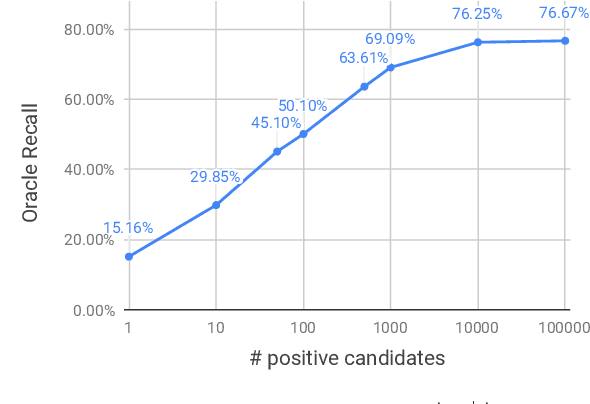
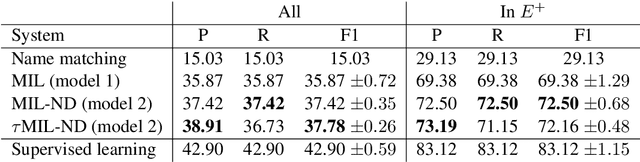
Accurate entity linkers have been produced for domains and languages where annotated data (i.e., texts linked to a knowledge base) is available. However, little progress has been made for the settings where no or very limited amounts of labeled data are present (e.g., legal or most scientific domains). In this work, we show how we can learn to link mentions without having any labeled examples, only a knowledge base and a collection of unannotated texts from the corresponding domain. In order to achieve this, we frame the task as a multi-instance learning problem and rely on surface matching to create initial noisy labels. As the learning signal is weak and our surrogate labels are noisy, we introduce a noise detection component in our model: it lets the model detect and disregard examples which are likely to be noisy. Our method, jointly learning to detect noise and link entities, greatly outperforms the surface matching baseline. For a subset of entity categories, it even approaches the performance of supervised learning.
Improving Entity Linking by Modeling Latent Relations between Mentions
Apr 27, 2018
Entity linking involves aligning textual mentions of named entities to their corresponding entries in a knowledge base. Entity linking systems often exploit relations between textual mentions in a document (e.g., coreference) to decide if the linking decisions are compatible. Unlike previous approaches, which relied on supervised systems or heuristics to predict these relations, we treat relations as latent variables in our neural entity-linking model. We induce the relations without any supervision while optimizing the entity-linking system in an end-to-end fashion. Our multi-relational model achieves the best reported scores on the standard benchmark (AIDA-CoNLL) and substantially outperforms its relation-agnostic version. Its training also converges much faster, suggesting that the injected structural bias helps to explain regularities in the training data.
LSTM-based Mixture-of-Experts for Knowledge-Aware Dialogues
May 05, 2016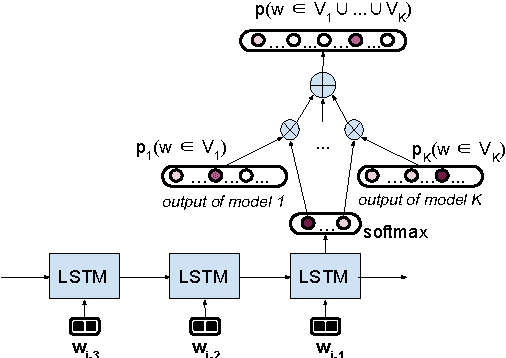

We introduce an LSTM-based method for dynamically integrating several word-prediction experts to obtain a conditional language model which can be good simultaneously at several subtasks. We illustrate this general approach with an application to dialogue where we integrate a neural chat model, good at conversational aspects, with a neural question-answering model, good at retrieving precise information from a knowledge-base, and show how the integration combines the strengths of the independent components. We hope that this focused contribution will attract attention on the benefits of using such mixtures of experts in NLP.
Quantifying the vanishing gradient and long distance dependency problem in recursive neural networks and recursive LSTMs
Mar 01, 2016



Recursive neural networks (RNN) and their recently proposed extension recursive long short term memory networks (RLSTM) are models that compute representations for sentences, by recursively combining word embeddings according to an externally provided parse tree. Both models thus, unlike recurrent networks, explicitly make use of the hierarchical structure of a sentence. In this paper, we demonstrate that RNNs nevertheless suffer from the vanishing gradient and long distance dependency problem, and that RLSTMs greatly improve over RNN's on these problems. We present an artificial learning task that allows us to quantify the severity of these problems for both models. We further show that a ratio of gradients (at the root node and a focal leaf node) is highly indicative of the success of backpropagation at optimizing the relevant weights low in the tree. This paper thus provides an explanation for existing, superior results of RLSTMs on tasks such as sentiment analysis, and suggests that the benefits of including hierarchical structure and of including LSTM-style gating are complementary.