 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Skills, Brittle Grounding: Diagnosing Restricted Generalization in Vision-Language Action Policies via Multi-Object Picking
Feb 27, 2026Vision-language action (VLA) policies often report strong manipulation benchmark performance with relatively few demonstrations, but it remains unclear whether this reflects robust language-to-object grounding or reliance on object--location correlations that do not transfer beyond the training distribution. We present a controlled multi-object picking study that progressively increases object placement variability up to full workspace randomization and evaluates held-out object--location pairings that break familiar associations without increasing spatial difficulty. Across these stress tests and data scaling, we find that for representative VLA policies, including SmolVLA and $π_{0.5}$, execution of the manipulation primitive remains substantially more reliable than instruction-conditioned task success in harder regimes, suggesting that manipulation skill acquisition is decoupled from instruction following. We recommend augmenting manipulation benchmarks with task ladders and decomposed metrics that separately measure primitive execution and instruction-conditioned success to better diagnose instruction-grounded generalization.
Disentangled Object-Centric Image Representation for Robotic Manipulation
Mar 14, 2025Learning robotic manipulation skills from vision is a promising approach for developing robotics applications that can generalize broadly to real-world scenarios. As such, many approaches to enable this vision have been explored with fruitful results. Particularly, object-centric representation methods have been shown to provide better inductive biases for skill learning, leading to improved performance and generalization. Nonetheless, we show that object-centric methods can struggle to learn simple manipulation skills in multi-object environments. Thus, we propose DOCIR, an object-centric framework that introduces a disentangled representation for objects of interest, obstacles, and robot embodiment. We show that this approach leads to state-of-the-art performance for learning pick and place skills from visual inputs in multi-object environments and generalizes at test time to changing objects of interest and distractors in the scene. Furthermore, we show its efficacy both in simulation and zero-shot transfer to the real world.
Unbiased Learning to Rank Meets Reality: Lessons from Baidu's Large-Scale Search Dataset
Apr 03, 2024Unbiased learning-to-rank (ULTR) is a well-established framework for learning from user clicks, which are often biased by the ranker collecting the data. While theoretically justified and extensively tested in simulation, ULTR techniques lack empirical validation, especially on modern search engines. The dataset released for the WSDM Cup 2023, collected from Baidu's search engine, offers a rare opportunity to assess the real-world performance of prominent ULTR techniques. Despite multiple submissions during the WSDM Cup 2023 and the subsequent NTCIR ULTRE-2 task, it remains unclear whether the observed improvements stem from applying ULTR or other learning techniques. We revisit and extend the available experiments. We find that unbiased learning-to-rank techniques do not bring clear performance improvements, especially compared to the stark differences brought by the choice of ranking loss and query-document features. Our experiments reveal that ULTR robustly improves click prediction. However, these gains in click prediction do not translate to enhanced ranking performance on expert relevance annotations, implying that conclusions strongly depend on how success is measured in this benchmark.
SARDINE: A Simulator for Automated Recommendation in Dynamic and Interactive Environments
Nov 28, 2023Simulators can provide valuable insights for researchers and practitioners who wish to improve recommender systems, because they allow one to easily tweak the experimental setup in which recommender systems operate, and as a result lower the cost of identifying general trends and uncovering novel findings about the candidate methods. A key requirement to enable this accelerated improvement cycle is that the simulator is able to span the various sources of complexity that can be found in the real recommendation environment that it simulates. With the emergence of interactive and data-driven methods - e.g., reinforcement learning or online and counterfactual learning-to-rank - that aim to achieve user-related goals beyond the traditional accuracy-centric objectives, adequate simulators are needed. In particular, such simulators must model the various mechanisms that render the recommendation environment dynamic and interactive, e.g., the effect of recommendations on the user or the effect of biased data on subsequent iterations of the recommender system. We therefore propose SARDINE, a flexible and interpretable recommendation simulator that can help accelerate research in interactive and data-driven recommender systems. We demonstrate its usefulness by studying existing methods within nine diverse environments derived from SARDINE, and even uncover novel insights about them.
Distributional Reinforcement Learning with Dual Expectile-Quantile Regression
May 26, 2023



Successful applications of distributional reinforcement learning with quantile regression prompt a natural question: can we use other statistics to represent the distribution of returns? In particular, expectile regression is known to be more efficient than quantile regression for approximating distributions, especially on extreme values, and by providing a straightforward estimator of the mean it is a natural candidate for reinforcement learning. Prior work has answered this question positively in the case of expectiles, with the major caveat that expensive computations must be performed to ensure convergence. In this work, we propose a dual expectile-quantile approach which solves the shortcomings of previous work while leveraging the complementary properties of expectiles and quantiles. Our method outperforms both quantile-based and expectile-based baselines on the MuJoCo continuous control benchmark.
An Offline Metric for the Debiasedness of Click Models
Apr 19, 2023A well-known problem when learning from user clicks are inherent biases prevalent in the data, such as position or trust bias. Click models are a common method for extracting information from user clicks, such as document relevance in web search, or to estimate click biases for downstream applications such as counterfactual learning-to-rank, ad placement, or fair ranking. Recent work shows that the current evaluation practices in the community fail to guarantee that a well-performing click model generalizes well to downstream tasks in which the ranking distribution differs from the training distribution, i.e., under covariate shift. In this work, we propose an evaluation metric based on conditional independence testing to detect a lack of robustness to covariate shift in click models. We introduce the concept of debiasedness and a metric for measuring it. We prove that debiasedness is a necessary condition for recovering unbiased and consistent relevance scores and for the invariance of click prediction under covariate shift. In extensive semi-synthetic experiments, we show that our proposed metric helps to predict the downstream performance of click models under covariate shift and is useful in an off-policy model selection setting.
Generative Slate Recommendation with Reinforcement Learning
Jan 24, 2023Recent research has employed reinforcement learning (RL) algorithms to optimize long-term user engagement in recommender systems, thereby avoiding common pitfalls such as user boredom and filter bubbles. They capture the sequential and interactive nature of recommendations, and thus offer a principled way to deal with long-term rewards and avoid myopic behaviors. However, RL approaches are intractable in the slate recommendation scenario - where a list of items is recommended at each interaction turn - due to the combinatorial action space. In that setting, an action corresponds to a slate that may contain any combination of items. While previous work has proposed well-chosen decompositions of actions so as to ensure tractability, these rely on restrictive and sometimes unrealistic assumptions. Instead, in this work we propose to encode slates in a continuous, low-dimensional latent space learned by a variational auto-encoder. Then, the RL agent selects continuous actions in this latent space, which are ultimately decoded into the corresponding slates. By doing so, we are able to (i) relax assumptions required by previous work, and (ii) improve the quality of the action selection by modeling full slates instead of independent items, in particular by enabling diversity. Our experiments performed on a wide array of simulated environments confirm the effectiveness of our generative modeling of slates over baselines in practical scenarios where the restrictive assumptions underlying the baselines are lifted. Our findings suggest that representation learning using generative models is a promising direction towards generalizable RL-based slate recommendation.
Offline Evaluation for Reinforcement Learning-based Recommendation: A Critical Issue and Some Alternatives
Jan 03, 2023In this paper, we argue that the paradigm commonly adopted for offline evaluation of sequential recommender systems is unsuitable for evaluating reinforcement learning-based recommenders. We find that most of the existing offline evaluation practices for reinforcement learning-based recommendation are based on a next-item prediction protocol, and detail three shortcomings of such an evaluation protocol. Notably, it cannot reflect the potential benefits that reinforcement learning (RL) is expected to bring while it hides critical deficiencies of certain offline RL agents. Our suggestions for alternative ways to evaluate RL-based recommender systems aim to shed light on the existing possibilities and inspire future research on reliable evaluation protocols.
Pareto-Optimal Fairness-Utility Amortizations in Rankings with a DBN Exposure Model
May 16, 2022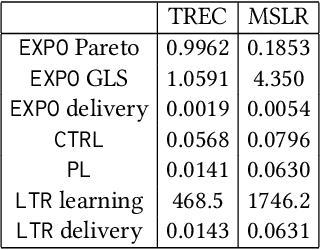
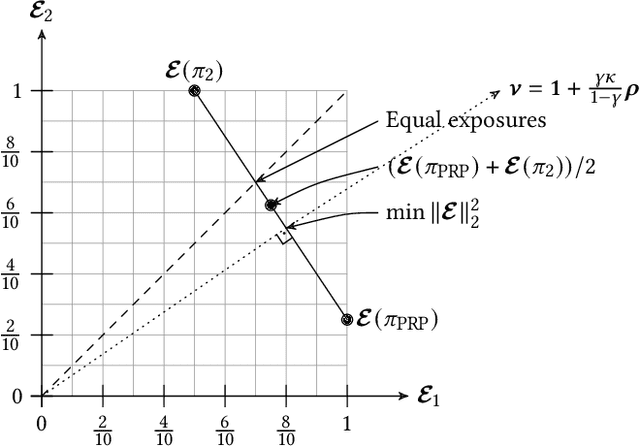
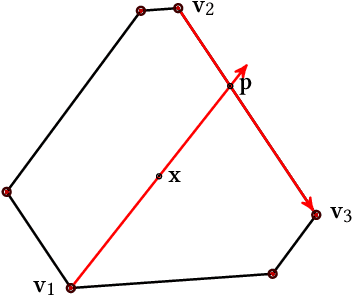
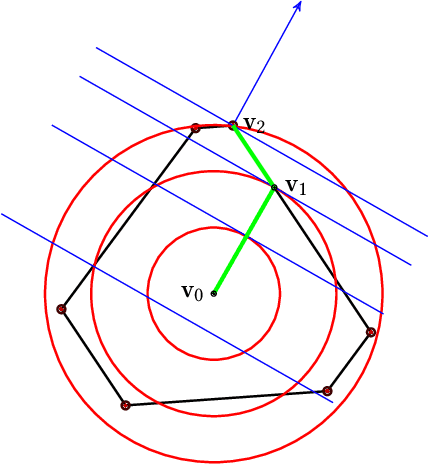
In recent years, it has become clear that rankings delivered in many areas need not only be useful to the users but also respect fairness of exposure for the item producers. We consider the problem of finding ranking policies that achieve a Pareto-optimal tradeoff between these two aspects. Several methods were proposed to solve it; for instance a popular one is to use linear programming with a Birkhoff-von Neumann decomposition. These methods, however, are based on a classical Position Based exposure Model (PBM), which assumes independence between the items (hence the exposure only depends on the rank). In many applications, this assumption is unrealistic and the community increasingly moves towards considering other models that include dependences, such as the Dynamic Bayesian Network (DBN) exposure model. For such models, computing (exact) optimal fair ranking policies remains an open question. We answer this question by leveraging a new geometrical method based on the so-called expohedron proposed recently for the PBM (Kletti et al., WSDM'22). We lay out the structure of a new geometrical object (the DBN-expohedron), and propose for it a Carath\'eodory decomposition algorithm of complexity $O(n^3)$, where $n$ is the number of documents to rank. Such an algorithm enables expressing any feasible expected exposure vector as a distribution over at most $n$ rankings; furthermore we show that we can compute the whole set of Pareto-optimal expected exposure vectors with the same complexity $O(n^3)$. Our work constitutes the first exact algorithm able to efficiently find a Pareto-optimal distribution of rankings. It is applicable to a broad range of fairness notions, including classical notions of meritocratic and demographic fairness. We empirically evaluate our method on the TREC2020 and MSLR datasets and compare it to several baselines in terms of Pareto-optimality and speed.
Introducing the Expohedron for Efficient Pareto-optimal Fairness-Utility Amortizations in Repeated Rankings
Feb 07, 2022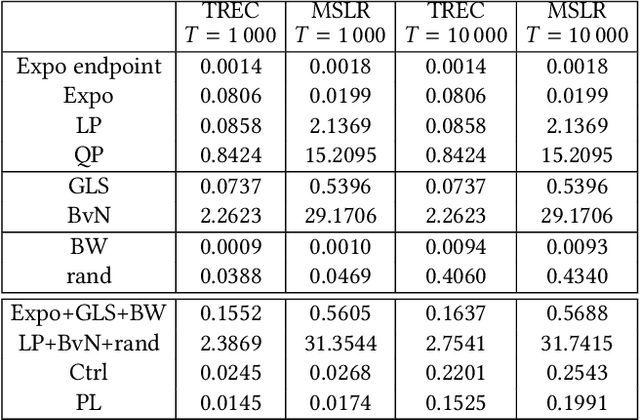
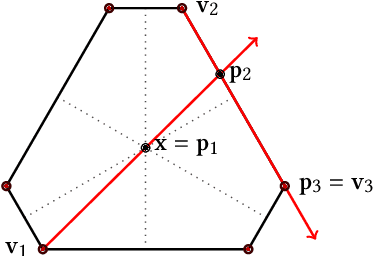
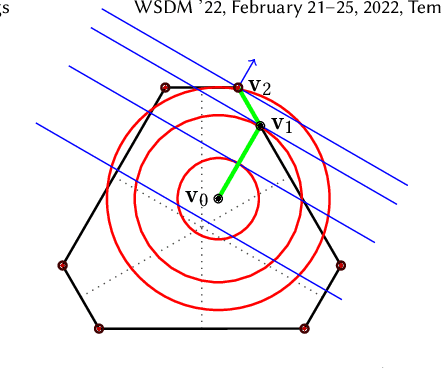
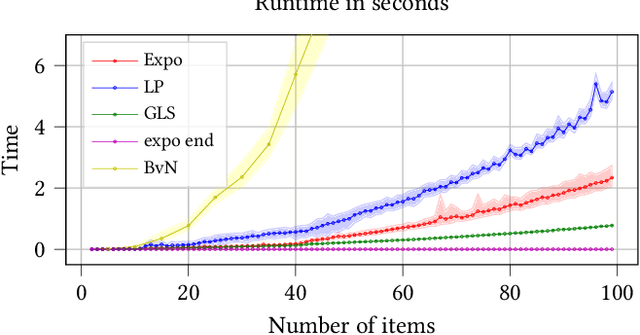
We consider the problem of computing a sequence of rankings that maximizes consumer-side utility while minimizing producer-side individual unfairness of exposure. While prior work has addressed this problem using linear or quadratic programs on bistochastic matrices, such approaches, relying on Birkhoff-von Neumann (BvN) decompositions, are too slow to be implemented at large scale. In this paper we introduce a geometrical object, a polytope that we call expohedron, whose points represent all achievable exposures of items for a Position Based Model (PBM). We exhibit some of its properties and lay out a Carath\'eodory decomposition algorithm with complexity $O(n^2\log(n))$ able to express any point inside the expohedron as a convex sum of at most $n$ vertices, where $n$ is the number of items to rank. Such a decomposition makes it possible to express any feasible target exposure as a distribution over at most $n$ rankings. Furthermore we show that we can use this polytope to recover the whole Pareto frontier of the multi-objective fairness-utility optimization problem, using a simple geometrical procedure with complexity $O(n^2\log(n))$. Our approach compares favorably to linear or quadratic programming baselines in terms of algorithmic complexity and empirical runtime and is applicable to any merit that is a non-decreasing function of item relevance. Furthermore our solution can be expressed as a distribution over only $n$ permutations, instead of the $(n-1)^2 + 1$ achieved with BvN decompositions. We perform experiments on synthetic and real-world datasets, confirming our theoretical results.