 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaST: Feature-aware Sampling and Tuning for Personalized Preference Alignment with Limited Data
Aug 06, 2025LLM-powered conversational assistants are often deployed in a one-size-fits-all manner, which fails to accommodate individual user preferences. Recently, LLM personalization -- tailoring models to align with specific user preferences -- has gained increasing attention as a way to bridge this gap. In this work, we specifically focus on a practical yet challenging setting where only a small set of preference annotations can be collected per user -- a problem we define as Personalized Preference Alignment with Limited Data (PPALLI). To support research in this area, we introduce two datasets -- DnD and ELIP -- and benchmark a variety of alignment techniques on them. We further propose FaST, a highly parameter-efficient approach that leverages high-level features automatically discovered from the data, achieving the best overall performance.
Guaranteed Generation from Large Language Models
Oct 09, 2024

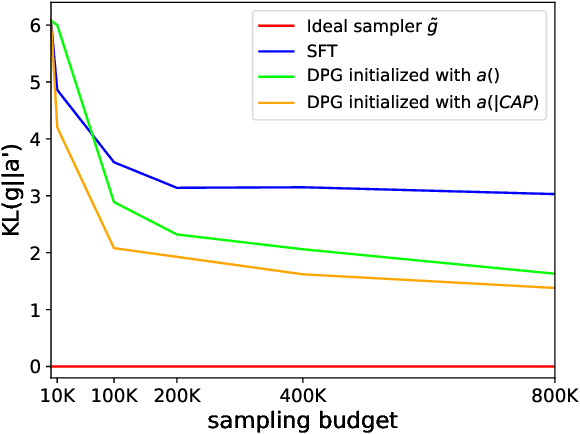

As large language models (LLMs) are increasingly used across various applications, there is a growing need to control text generation to satisfy specific constraints or requirements. This raises a crucial question: Is it possible to guarantee strict constraint satisfaction in generated outputs while preserving the distribution of the original model as much as possible? We first define the ideal distribution - the one closest to the original model, which also always satisfies the expressed constraint - as the ultimate goal of guaranteed generation. We then state a fundamental limitation, namely that it is impossible to reach that goal through autoregressive training alone. This motivates the necessity of combining training-time and inference-time methods to enforce such guarantees. Based on this insight, we propose GUARD, a simple yet effective approach that combines an autoregressive proposal distribution with rejection sampling. Through GUARD's theoretical properties, we show how controlling the KL divergence between a specific proposal and the target ideal distribution simultaneously optimizes inference speed and distributional closeness. To validate these theoretical concepts, we conduct extensive experiments on two text generation settings with hard-to-satisfy constraints: a lexical constraint scenario and a sentiment reversal scenario. These experiments show that GUARD achieves perfect constraint satisfaction while almost preserving the ideal distribution with highly improved inference efficiency. GUARD provides a principled approach to enforcing strict guarantees for LLMs without compromising their generative capabilities.
ELITR-Bench: A Meeting Assistant Benchmark for Long-Context Language Models
Mar 29, 2024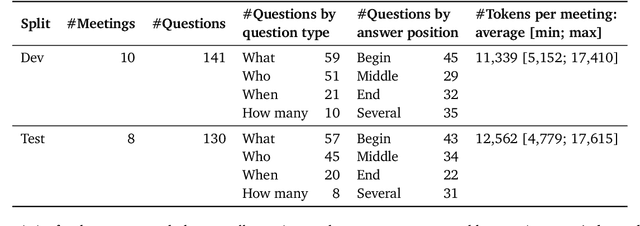
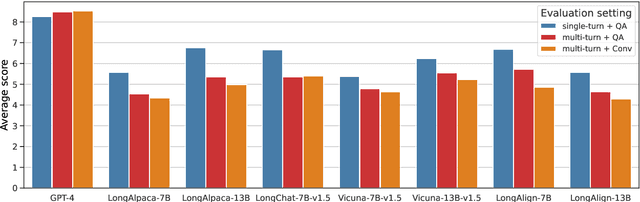
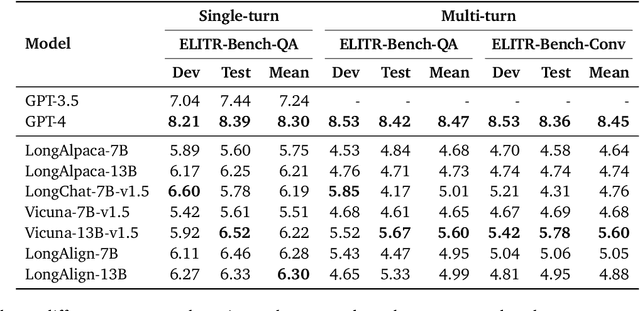
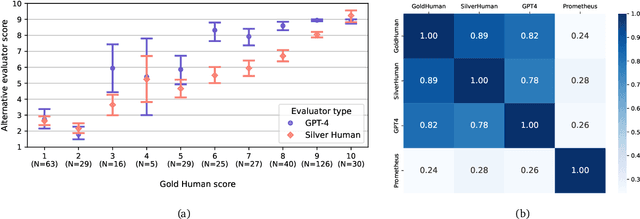
Research on Large Language Models (LLMs) has recently witnessed an increasing interest in extending models' context size to better capture dependencies within long documents. While benchmarks have been proposed to assess long-range abilities, existing efforts primarily considered generic tasks that are not necessarily aligned with real-world applications. In contrast, our work proposes a new benchmark for long-context LLMs focused on a practical meeting assistant scenario. In this scenario, the long contexts consist of transcripts obtained by automatic speech recognition, presenting unique challenges for LLMs due to the inherent noisiness and oral nature of such data. Our benchmark, named ELITR-Bench, augments the existing ELITR corpus' transcripts with 271 manually crafted questions and their ground-truth answers. Our experiments with recent long-context LLMs on ELITR-Bench highlight a gap between open-source and proprietary models, especially when questions are asked sequentially within a conversation. We also provide a thorough analysis of our GPT-4-based evaluation method, encompassing insights from a crowdsourcing study. Our findings suggest that while GPT-4's evaluation scores are correlated with human judges', its ability to differentiate among more than three score levels may be limited.
SARDINE: A Simulator for Automated Recommendation in Dynamic and Interactive Environments
Nov 28, 2023Simulators can provide valuable insights for researchers and practitioners who wish to improve recommender systems, because they allow one to easily tweak the experimental setup in which recommender systems operate, and as a result lower the cost of identifying general trends and uncovering novel findings about the candidate methods. A key requirement to enable this accelerated improvement cycle is that the simulator is able to span the various sources of complexity that can be found in the real recommendation environment that it simulates. With the emergence of interactive and data-driven methods - e.g., reinforcement learning or online and counterfactual learning-to-rank - that aim to achieve user-related goals beyond the traditional accuracy-centric objectives, adequate simulators are needed. In particular, such simulators must model the various mechanisms that render the recommendation environment dynamic and interactive, e.g., the effect of recommendations on the user or the effect of biased data on subsequent iterations of the recommender system. We therefore propose SARDINE, a flexible and interpretable recommendation simulator that can help accelerate research in interactive and data-driven recommender systems. We demonstrate its usefulness by studying existing methods within nine diverse environments derived from SARDINE, and even uncover novel insights about them.
Generative Slate Recommendation with Reinforcement Learning
Jan 24, 2023Recent research has employed reinforcement learning (RL) algorithms to optimize long-term user engagement in recommender systems, thereby avoiding common pitfalls such as user boredom and filter bubbles. They capture the sequential and interactive nature of recommendations, and thus offer a principled way to deal with long-term rewards and avoid myopic behaviors. However, RL approaches are intractable in the slate recommendation scenario - where a list of items is recommended at each interaction turn - due to the combinatorial action space. In that setting, an action corresponds to a slate that may contain any combination of items. While previous work has proposed well-chosen decompositions of actions so as to ensure tractability, these rely on restrictive and sometimes unrealistic assumptions. Instead, in this work we propose to encode slates in a continuous, low-dimensional latent space learned by a variational auto-encoder. Then, the RL agent selects continuous actions in this latent space, which are ultimately decoded into the corresponding slates. By doing so, we are able to (i) relax assumptions required by previous work, and (ii) improve the quality of the action selection by modeling full slates instead of independent items, in particular by enabling diversity. Our experiments performed on a wide array of simulated environments confirm the effectiveness of our generative modeling of slates over baselines in practical scenarios where the restrictive assumptions underlying the baselines are lifted. Our findings suggest that representation learning using generative models is a promising direction towards generalizable RL-based slate recommendation.
Offline Evaluation for Reinforcement Learning-based Recommendation: A Critical Issue and Some Alternatives
Jan 03, 2023In this paper, we argue that the paradigm commonly adopted for offline evaluation of sequential recommender systems is unsuitable for evaluating reinforcement learning-based recommenders. We find that most of the existing offline evaluation practices for reinforcement learning-based recommendation are based on a next-item prediction protocol, and detail three shortcomings of such an evaluation protocol. Notably, it cannot reflect the potential benefits that reinforcement learning (RL) is expected to bring while it hides critical deficiencies of certain offline RL agents. Our suggestions for alternative ways to evaluate RL-based recommender systems aim to shed light on the existing possibilities and inspire future research on reliable evaluation protocols.
SmoothI: Smooth Rank Indicators for Differentiable IR Metrics
May 03, 2021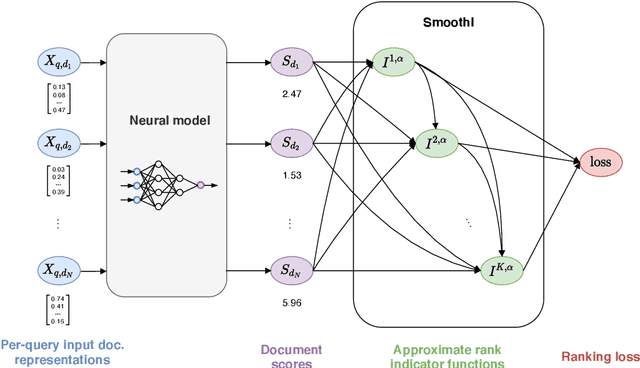
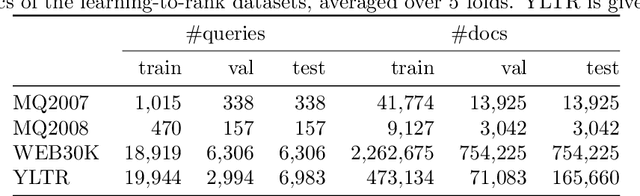
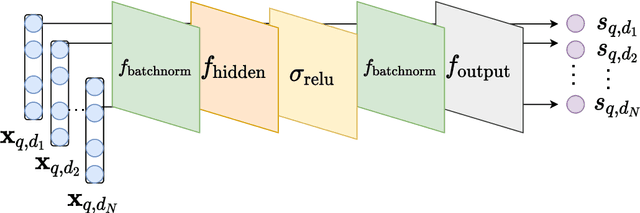
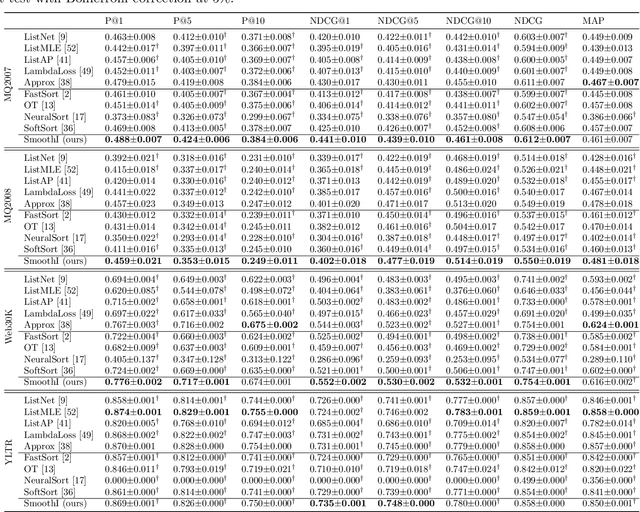
Information retrieval (IR) systems traditionally aim to maximize metrics built on rankings, such as precision or NDCG. However, the non-differentiability of the ranking operation prevents direct optimization of such metrics in state-of-the-art neural IR models, which rely entirely on the ability to compute meaningful gradients. To address this shortcoming, we propose SmoothI, a smooth approximation of rank indicators that serves as a basic building block to devise differentiable approximations of IR metrics. We further provide theoretical guarantees on SmoothI and derived approximations, showing in particular that the approximation errors decrease exponentially with an inverse temperature-like hyperparameter that controls the quality of the approximations. Extensive experiments conducted on four standard learning-to-rank datasets validate the efficacy of the listwise losses based on SmoothI, in comparison to previously proposed ones. Additional experiments with a vanilla BERT ranking model on a text-based IR task also confirm the benefits of our listwise approach.
Deep $k$-Means: Jointly Clustering with $k$-Means and Learning Representations
Jun 26, 2018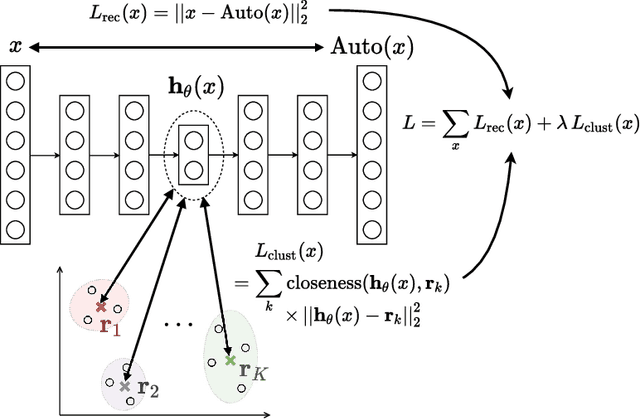
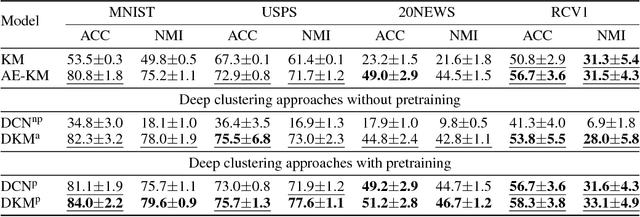
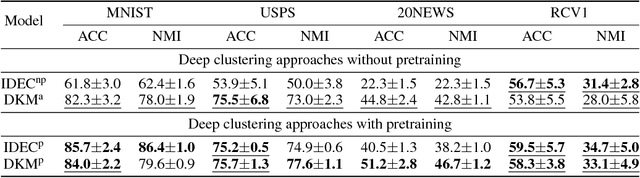
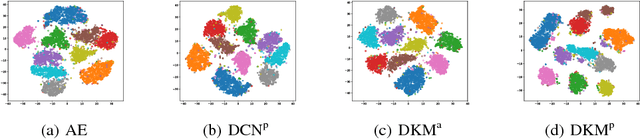
We study in this paper the problem of jointly clustering and learning representations. As several previous studies have shown, learning representations that are both faithful to the data to be clustered and adapted to the clustering algorithm can lead to better clustering performance, all the more so that the two tasks are performed jointly. We propose here such an approach for $k$-Means clustering based on a continuous reparametrization of the objective function that leads to a truly joint solution. The behavior of our approach is illustrated on various datasets showing its efficacy in learning representations for objects while clustering them.