 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Section Weights for Multi-Label Document Classification
Nov 26, 2023Multi-label document classification is a traditional task in NLP. Compared to single-label classification, each document can be assigned multiple classes. This problem is crucially important in various domains, such as tagging scientific articles. Documents are often structured into several sections such as abstract and title. Current approaches treat different sections equally for multi-label classification. We argue that this is not a realistic assumption, leading to sub-optimal results. Instead, we propose a new method called Learning Section Weights (LSW), leveraging the contribution of each distinct section for multi-label classification. Via multiple feed-forward layers, LSW learns to assign weights to each section of, and incorporate the weights in the prediction. We demonstrate our approach on scientific articles. Experimental results on public (arXiv) and private (Elsevier) datasets confirm the superiority of LSW, compared to state-of-the-art multi-label document classification methods. In particular, LSW achieves a 1.3% improvement in terms of macro averaged F1-score while it achieves 1.3% in terms of macro averaged recall on the publicly available arXiv dataset.
Deep $k$-Means: Jointly Clustering with $k$-Means and Learning Representations
Jun 26, 2018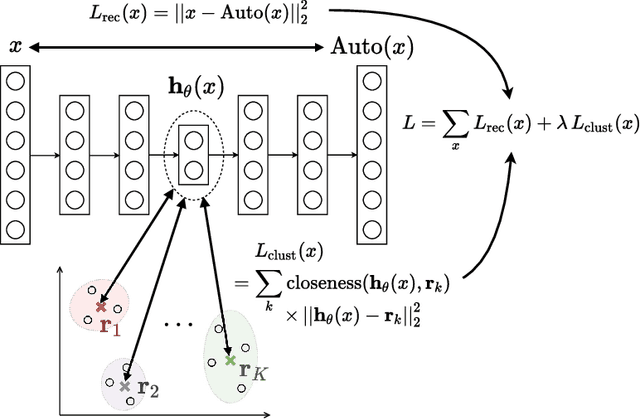
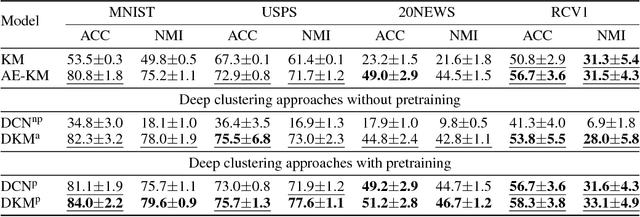
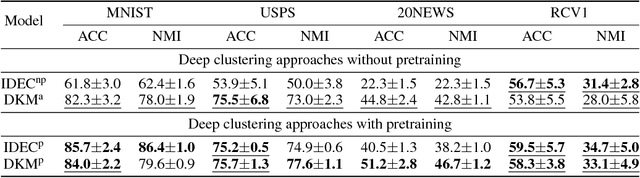
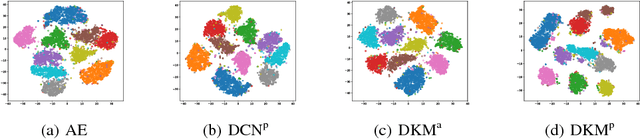
We study in this paper the problem of jointly clustering and learning representations. As several previous studies have shown, learning representations that are both faithful to the data to be clustered and adapted to the clustering algorithm can lead to better clustering performance, all the more so that the two tasks are performed jointly. We propose here such an approach for $k$-Means clustering based on a continuous reparametrization of the objective function that leads to a truly joint solution. The behavior of our approach is illustrated on various datasets showing its efficacy in learning representations for objects while clustering them.