 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Section Weights for Multi-Label Document Classification
Nov 26, 2023Multi-label document classification is a traditional task in NLP. Compared to single-label classification, each document can be assigned multiple classes. This problem is crucially important in various domains, such as tagging scientific articles. Documents are often structured into several sections such as abstract and title. Current approaches treat different sections equally for multi-label classification. We argue that this is not a realistic assumption, leading to sub-optimal results. Instead, we propose a new method called Learning Section Weights (LSW), leveraging the contribution of each distinct section for multi-label classification. Via multiple feed-forward layers, LSW learns to assign weights to each section of, and incorporate the weights in the prediction. We demonstrate our approach on scientific articles. Experimental results on public (arXiv) and private (Elsevier) datasets confirm the superiority of LSW, compared to state-of-the-art multi-label document classification methods. In particular, LSW achieves a 1.3% improvement in terms of macro averaged F1-score while it achieves 1.3% in terms of macro averaged recall on the publicly available arXiv dataset.
One Strike, You're Out: Detecting Markush Structures in Low Signal-to-Noise Ratio Images
Nov 24, 2023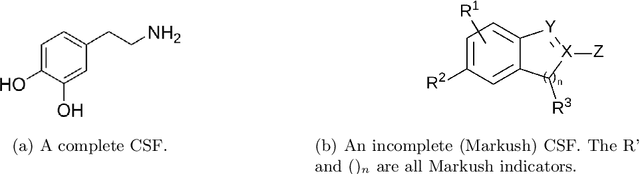

Modern research increasingly relies on automated methods to assist researchers. An example of this is Optical Chemical Structure Recognition (OCSR), which aids chemists in retrieving information about chemicals from large amounts of documents. Markush structures are chemical structures that cannot be parsed correctly by OCSR and cause errors. The focus of this research was to propose and test a novel method for classifying Markush structures. Within this method, a comparison was made between fixed-feature extraction and end-to-end learning (CNN). The end-to-end method performed significantly better than the fixed-feature method, achieving 0.928 (0.035 SD) Macro F1 compared to the fixed-feature method's 0.701 (0.052 SD). Because of the nature of the experiment, these figures are a lower bound and can be improved further. These results suggest that Markush structures can be filtered out effectively and accurately using the proposed method. When implemented into OCSR pipelines, this method can improve their performance and use to other researchers.
Stress Testing BERT Anaphora Resolution Models for Reaction Extraction in Chemical Patents
Jun 23, 2023
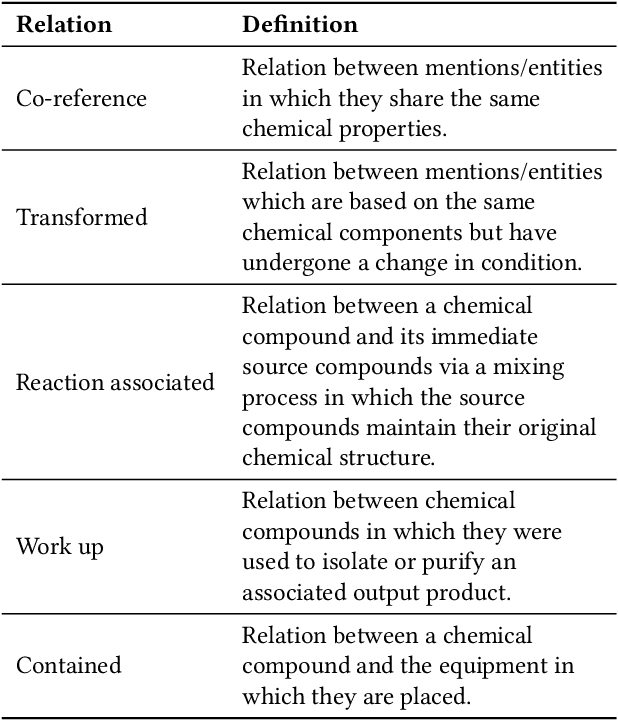
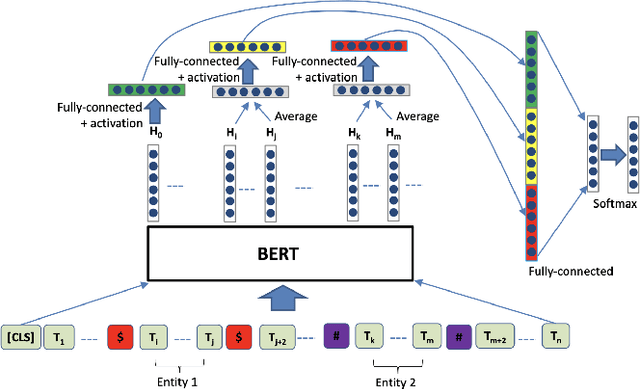
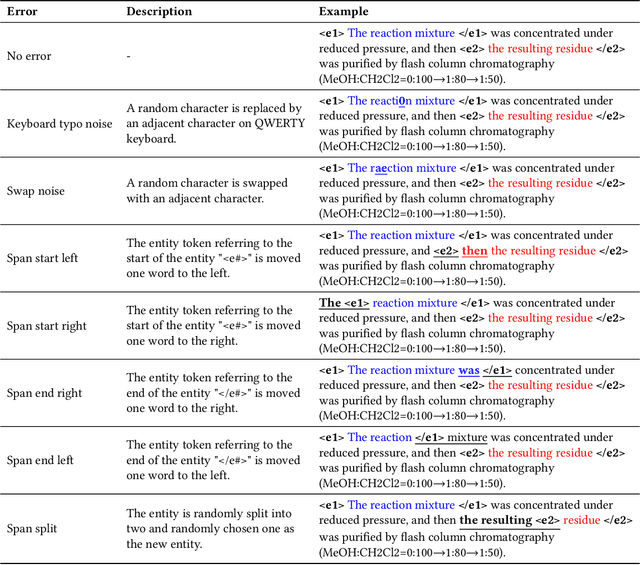
The high volume of published chemical patents and the importance of a timely acquisition of their information gives rise to automating information extraction from chemical patents. Anaphora resolution is an important component of comprehensive information extraction, and is critical for extracting reactions. In chemical patents, there are five anaphoric relations of interest: co-reference, transformed, reaction associated, work up, and contained. Our goal is to investigate how the performance of anaphora resolution models for reaction texts in chemical patents differs in a noise-free and noisy environment and to what extent we can improve the robustness against noise of the model.
Word Embeddings for Chemical Patent Natural Language Processing
Oct 24, 2020
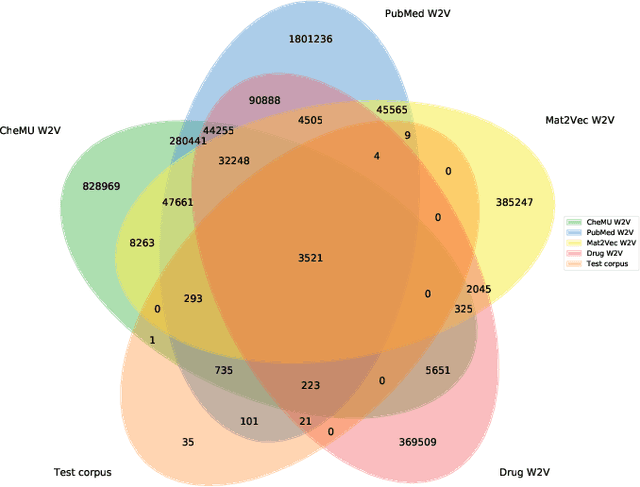
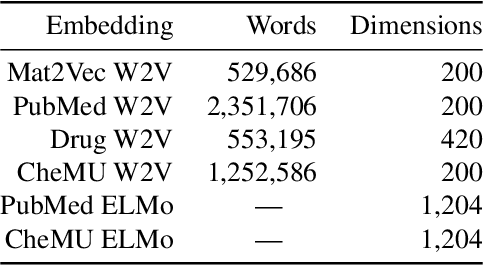
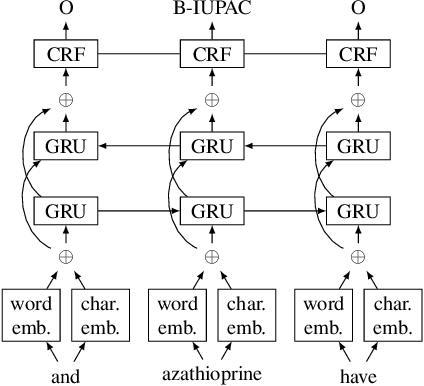
We evaluate chemical patent word embeddings against known biomedical embeddings and show that they outperform the latter extrinsically and intrinsically. We also show that using contextualized embeddings can induce predictive models of reasonable performance for this domain over a relatively small gold standard.