 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenign-to-Toxic Jailbreaking: Inducing Harmful Responses from Harmless Prompts
May 26, 2025Optimization-based jailbreaks typically adopt the Toxic-Continuation setting in large vision-language models (LVLMs), following the standard next-token prediction objective. In this setting, an adversarial image is optimized to make the model predict the next token of a toxic prompt. However, we find that the Toxic-Continuation paradigm is effective at continuing already-toxic inputs, but struggles to induce safety misalignment when explicit toxic signals are absent. We propose a new paradigm: Benign-to-Toxic (B2T) jailbreak. Unlike prior work, we optimize adversarial images to induce toxic outputs from benign conditioning. Since benign conditioning contains no safety violations, the image alone must break the model's safety mechanisms. Our method outperforms prior approaches, transfers in black-box settings, and complements text-based jailbreaks. These results reveal an underexplored vulnerability in multimodal alignment and introduce a fundamentally new direction for jailbreak approaches.
ReflAct: World-Grounded Decision Making in LLM Agents via Goal-State Reflection
May 21, 2025Recent advances in LLM agents have largely built on reasoning backbones like ReAct, which interleave thought and action in complex environments. However, ReAct often produces ungrounded or incoherent reasoning steps, leading to misalignment between the agent's actual state and goal. Our analysis finds that this stems from ReAct's inability to maintain consistent internal beliefs and goal alignment, causing compounding errors and hallucinations. To address this, we introduce ReflAct, a novel backbone that shifts reasoning from merely planning next actions to continuously reflecting on the agent's state relative to its goal. By explicitly grounding decisions in states and enforcing ongoing goal alignment, ReflAct dramatically improves strategic reliability. This design delivers substantial empirical gains: ReflAct surpasses ReAct by 27.7% on average, achieving a 93.3% success rate in ALFWorld. Notably, ReflAct even outperforms ReAct with added enhancement modules (e.g., Reflexion, WKM), showing that strengthening the core reasoning backbone is key to reliable agent performance.
Drift: Decoding-time Personalized Alignments with Implicit User Preferences
Feb 21, 2025Personalized alignments for individual users have been a long-standing goal in large language models (LLMs). We introduce Drift, a novel framework that personalizes LLMs at decoding time with implicit user preferences. Traditional Reinforcement Learning from Human Feedback (RLHF) requires thousands of annotated examples and expensive gradient updates. In contrast, Drift personalizes LLMs in a training-free manner, using only a few dozen examples to steer a frozen model through efficient preference modeling. Our approach models user preferences as a composition of predefined, interpretable attributes and aligns them at decoding time to enable personalized generation. Experiments on both a synthetic persona dataset (Perspective) and a real human-annotated dataset (PRISM) demonstrate that Drift significantly outperforms RLHF baselines while using only 50-100 examples. Our results and analysis show that Drift is both computationally efficient and interpretable.
Doubly-Universal Adversarial Perturbations: Deceiving Vision-Language Models Across Both Images and Text with a Single Perturbation
Dec 11, 2024



Large Vision-Language Models (VLMs) have demonstrated remarkable performance across multimodal tasks by integrating vision encoders with large language models (LLMs). However, these models remain vulnerable to adversarial attacks. Among such attacks, Universal Adversarial Perturbations (UAPs) are especially powerful, as a single optimized perturbation can mislead the model across various input images. In this work, we introduce a novel UAP specifically designed for VLMs: the Doubly-Universal Adversarial Perturbation (Doubly-UAP), capable of universally deceiving VLMs across both image and text inputs. To successfully disrupt the vision encoder's fundamental process, we analyze the core components of the attention mechanism. After identifying value vectors in the middle-to-late layers as the most vulnerable, we optimize Doubly-UAP in a label-free manner with a frozen model. Despite being developed as a black-box to the LLM, Doubly-UAP achieves high attack success rates on VLMs, consistently outperforming baseline methods across vision-language tasks. Extensive ablation studies and analyses further demonstrate the robustness of Doubly-UAP and provide insights into how it influences internal attention mechanisms.
Guaranteed Generation from Large Language Models
Oct 09, 2024

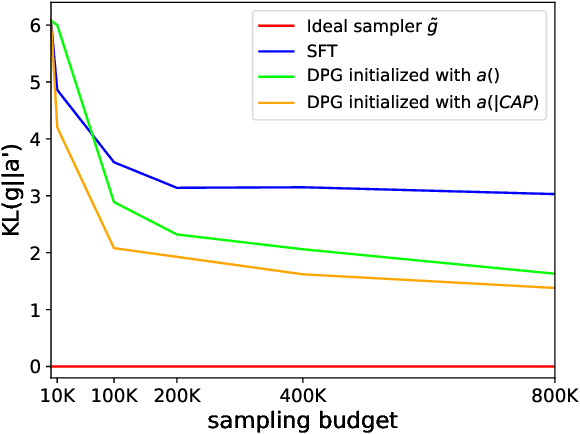

As large language models (LLMs) are increasingly used across various applications, there is a growing need to control text generation to satisfy specific constraints or requirements. This raises a crucial question: Is it possible to guarantee strict constraint satisfaction in generated outputs while preserving the distribution of the original model as much as possible? We first define the ideal distribution - the one closest to the original model, which also always satisfies the expressed constraint - as the ultimate goal of guaranteed generation. We then state a fundamental limitation, namely that it is impossible to reach that goal through autoregressive training alone. This motivates the necessity of combining training-time and inference-time methods to enforce such guarantees. Based on this insight, we propose GUARD, a simple yet effective approach that combines an autoregressive proposal distribution with rejection sampling. Through GUARD's theoretical properties, we show how controlling the KL divergence between a specific proposal and the target ideal distribution simultaneously optimizes inference speed and distributional closeness. To validate these theoretical concepts, we conduct extensive experiments on two text generation settings with hard-to-satisfy constraints: a lexical constraint scenario and a sentiment reversal scenario. These experiments show that GUARD achieves perfect constraint satisfaction while almost preserving the ideal distribution with highly improved inference efficiency. GUARD provides a principled approach to enforcing strict guarantees for LLMs without compromising their generative capabilities.
A Character-Centric Creative Story Generation via Imagination
Sep 25, 2024



Creative story generation with diverse and detailed story elements is a long-standing goal for large language models. While existing methodologies generate long and coherent stories, they fall significantly short of human capabilities in terms of diversity and character detail. To address this, we introduce a novel story generation framework called CCI (Character-centric Creative story generation via Imagination). CCI features two innovative modules for creative story generation: IG (Image-Guided Imagination) and MW (Multi-Writer model). In the IG module, we utilize DALL-E 3 to create visual representations of key story elements. The IG generates more novel and concrete characters, backgrounds, and main plots than text-only methods. The MW module uses these story elements created by IG to generate multiple description candidates for the protagonist and select the best one. This method incorporates vivid and rich character descriptions into the story. We compared the stories generated by CCI and baseline models through human evaluation and statistical analysis. The results showed significant improvements in the creativity. Furthermore, by enabling interactive multi-modal story generation with users, we have opened up possibilities for human-LLM integration in cultural development.
VideoMamba: Spatio-Temporal Selective State Space Model
Jul 11, 2024



We introduce VideoMamba, a novel adaptation of the pure Mamba architecture, specifically designed for video recognition. Unlike transformers that rely on self-attention mechanisms leading to high computational costs by quadratic complexity, VideoMamba leverages Mamba's linear complexity and selective SSM mechanism for more efficient processing. The proposed Spatio-Temporal Forward and Backward SSM allows the model to effectively capture the complex relationship between non-sequential spatial and sequential temporal information in video. Consequently, VideoMamba is not only resource-efficient but also effective in capturing long-range dependency in videos, demonstrated by competitive performance and outstanding efficiency on a variety of video understanding benchmarks. Our work highlights the potential of VideoMamba as a powerful tool for video understanding, offering a simple yet effective baseline for future research in video analysis.
VLind-Bench: Measuring Language Priors in Large Vision-Language Models
Jun 17, 2024Large Vision-Language Models (LVLMs) have demonstrated outstanding performance across various multimodal tasks. However, they suffer from a problem known as language prior, where responses are generated based solely on textual patterns while disregarding image information. Addressing the issue of language prior is crucial, as it can lead to undesirable biases or hallucinations when dealing with images that are out of training distribution. Despite its importance, current methods for accurately measuring language priors in LVLMs are poorly studied. Although existing benchmarks based on counterfactual or out-of-distribution images can partially be used to measure language priors, they fail to disentangle language priors from other confounding factors. To this end, we propose a new benchmark called VLind-Bench, which is the first benchmark specifically designed to measure the language priors, or blindness, of LVLMs. It not only includes tests on counterfactual images to assess language priors but also involves a series of tests to evaluate more basic capabilities such as commonsense knowledge, visual perception, and commonsense biases. For each instance in our benchmark, we ensure that all these basic tests are passed before evaluating the language priors, thereby minimizing the influence of other factors on the assessment. The evaluation and analysis of recent LVLMs in our benchmark reveal that almost all models exhibit a significant reliance on language priors, presenting a strong challenge in the field.
AdvisorQA: Towards Helpful and Harmless Advice-seeking Question Answering with Collective Intelligence
Apr 18, 2024
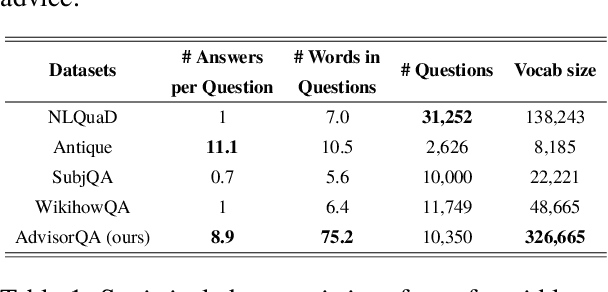
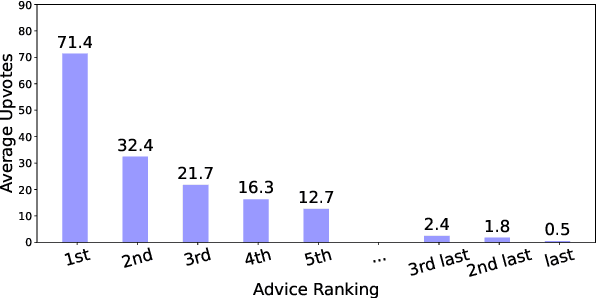

As the integration of large language models into daily life is on the rise, there is a clear gap in benchmarks for advising on subjective and personal dilemmas. To address this, we introduce AdvisorQA, the first benchmark developed to assess LLMs' capability in offering advice for deeply personalized concerns, utilizing the LifeProTips subreddit forum. This forum features a dynamic interaction where users post advice-seeking questions, receiving an average of 8.9 advice per query, with 164.2 upvotes from hundreds of users, embodying a collective intelligence framework. Therefore, we've completed a benchmark encompassing daily life questions, diverse corresponding responses, and majority vote ranking to train our helpfulness metric. Baseline experiments validate the efficacy of AdvisorQA through our helpfulness metric, GPT-4, and human evaluation, analyzing phenomena beyond the trade-off between helpfulness and harmlessness. AdvisorQA marks a significant leap in enhancing QA systems for providing personalized, empathetic advice, showcasing LLMs' improved understanding of human subjectivity.
Breaking Temporal Consistency: Generating Video Universal Adversarial Perturbations Using Image Models
Nov 17, 2023As video analysis using deep learning models becomes more widespread, the vulnerability of such models to adversarial attacks is becoming a pressing concern. In particular, Universal Adversarial Perturbation (UAP) poses a significant threat, as a single perturbation can mislead deep learning models on entire datasets. We propose a novel video UAP using image data and image model. This enables us to take advantage of the rich image data and image model-based studies available for video applications. However, there is a challenge that image models are limited in their ability to analyze the temporal aspects of videos, which is crucial for a successful video attack. To address this challenge, we introduce the Breaking Temporal Consistency (BTC) method, which is the first attempt to incorporate temporal information into video attacks using image models. We aim to generate adversarial videos that have opposite patterns to the original. Specifically, BTC-UAP minimizes the feature similarity between neighboring frames in videos. Our approach is simple but effective at attacking unseen video models. Additionally, it is applicable to videos of varying lengths and invariant to temporal shifts. Our approach surpasses existing methods in terms of effectiveness on various datasets, including ImageNet, UCF-101, and Kinetics-400.