 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlack-Box Hallucination Detection via Consistency Under the Uncertain Expression
Sep 26, 2025Despite the great advancement of Language modeling in recent days, Large Language Models (LLMs) such as GPT3 are notorious for generating non-factual responses, so-called "hallucination" problems. Existing methods for detecting and alleviating this hallucination problem require external resources or the internal state of LLMs, such as the output probability of each token. Given the LLM's restricted external API availability and the limited scope of external resources, there is an urgent demand to establish the Black-Box approach as the cornerstone for effective hallucination detection. In this work, we propose a simple black-box hallucination detection metric after the investigation of the behavior of LLMs under expression of uncertainty. Our comprehensive analysis reveals that LLMs generate consistent responses when they present factual responses while non-consistent responses vice versa. Based on the analysis, we propose an efficient black-box hallucination detection metric with the expression of uncertainty. The experiment demonstrates that our metric is more predictive of the factuality in model responses than baselines that use internal knowledge of LLMs.
LLMs can be easily Confused by Instructional Distractions
Feb 05, 2025



Despite the fact that large language models (LLMs) show exceptional skill in instruction following tasks, this strength can turn into a vulnerability when the models are required to disregard certain instructions. Instruction-following tasks typically involve a clear task description and input text containing the target data to be processed. However, when the input itself resembles an instruction, confusion may arise, even if there is explicit prompting to distinguish between the task instruction and the input. We refer to this phenomenon as instructional distraction. In this paper, we introduce a novel benchmark, named DIM-Bench, specifically designed to assess LLMs' performance under instructional distraction. The benchmark categorizes real-world instances of instructional distraction and evaluates LLMs across four instruction tasks: rewriting, proofreading, translation, and style transfer -- alongside five input tasks: reasoning, code generation, mathematical reasoning, bias detection, and question answering. Our experimental results reveal that even the most advanced LLMs are susceptible to instructional distraction, often failing to accurately follow user intent in such cases.
SWITCH: Studying with Teacher for Knowledge Distillation of Large Language Models
Oct 25, 2024Despite the success of Large Language Models (LLMs), they still face challenges related to high inference costs and memory requirements. To address these issues, Knowledge Distillation (KD) has emerged as a popular method for model compression, with student-generated outputs (SGOs) being particularly notable for reducing the mismatch between training and inference. However, SGOs often produce noisy and biased sequences, which can lead to misguidance from the teacher model, especially in long sequences. To mitigate these challenges, we propose SWITCH (Studying WIth TeaCHer for Knowledge Distillation), a novel approach that strategically incorporates the teacher model during the student's sequence generation. SWITCH identifies discrepancies between the token probabilities of the teacher and student models, allowing the teacher to intervene selectively, particularly in long sequences that are more prone to teacher misguidance. Extensive experimental results across three model families and five instruction-following datasets show that SWITCH surpasses traditional KD methods, particularly excelling in the generation of long sequential data.
OPAL: Outlier-Preserved Microscaling Quantization A ccelerator for Generative Large Language Models
Sep 06, 2024



To overcome the burden on the memory size and bandwidth due to ever-increasing size of large language models (LLMs), aggressive weight quantization has been recently studied, while lacking research on quantizing activations. In this paper, we present a hardware-software co-design method that results in an energy-efficient LLM accelerator, named OPAL, for generation tasks. First of all, a novel activation quantization method that leverages the microscaling data format while preserving several outliers per sub-tensor block (e.g., four out of 128 elements) is proposed. Second, on top of preserving outliers, mixed precision is utilized that sets 5-bit for inputs to sensitive layers in the decoder block of an LLM, while keeping inputs to less sensitive layers to 3-bit. Finally, we present the OPAL hardware architecture that consists of FP units for handling outliers and vectorized INT multipliers for dominant non-outlier related operations. In addition, OPAL uses log2-based approximation on softmax operations that only requires shift and subtraction to maximize power efficiency. As a result, we are able to improve the energy efficiency by 1.6~2.2x, and reduce the area by 2.4~3.1x with negligible accuracy loss, i.e., <1 perplexity increase.
LifeTox: Unveiling Implicit Toxicity in Life Advice
Nov 16, 2023As large language models become increasingly integrated into daily life, detecting implicit toxicity across diverse contexts is crucial. To this end, we introduce LifeTox, a dataset designed for identifying implicit toxicity within a broad range of advice-seeking scenarios. Unlike existing safety datasets, LifeTox comprises diverse contexts derived from personal experiences through open-ended questions. Experiments demonstrate that RoBERTa fine-tuned on LifeTox matches or surpasses the zero-shot performance of large language models in toxicity classification tasks. These results underscore the efficacy of LifeTox in addressing the complex challenges inherent in implicit toxicity.
LightNorm: Area and Energy-Efficient Batch Normalization Hardware for On-Device DNN Training
Nov 04, 2022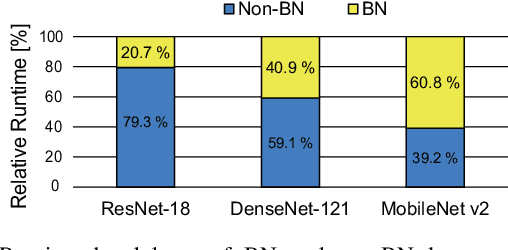
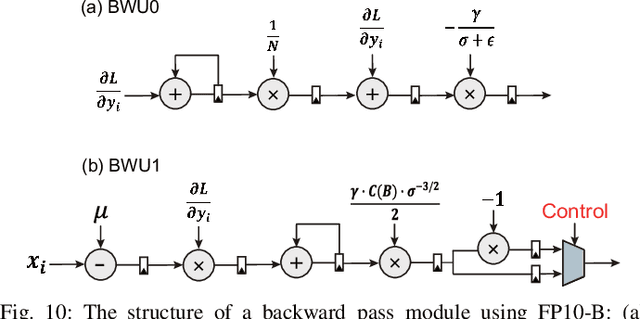
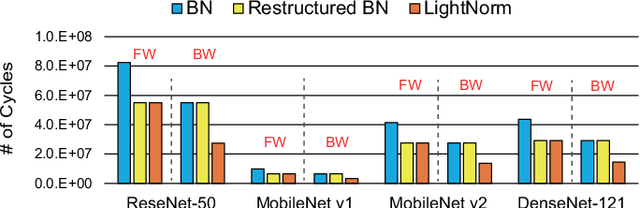
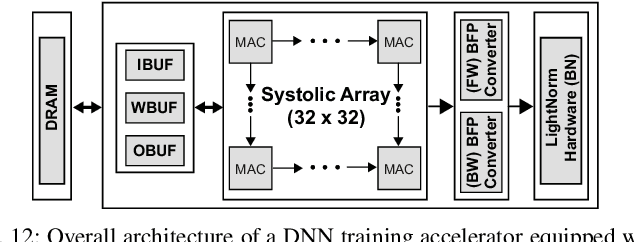
When training early-stage deep neural networks (DNNs), generating intermediate features via convolution or linear layers occupied most of the execution time. Accordingly, extensive research has been done to reduce the computational burden of the convolution or linear layers. In recent mobile-friendly DNNs, however, the relative number of operations involved in processing these layers has significantly reduced. As a result, the proportion of the execution time of other layers, such as batch normalization layers, has increased. Thus, in this work, we conduct a detailed analysis of the batch normalization layer to efficiently reduce the runtime overhead in the batch normalization process. Backed up by the thorough analysis, we present an extremely efficient batch normalization, named LightNorm, and its associated hardware module. In more detail, we fuse three approximation techniques that are i) low bit-precision, ii) range batch normalization, and iii) block floating point. All these approximate techniques are carefully utilized not only to maintain the statistics of intermediate feature maps, but also to minimize the off-chip memory accesses. By using the proposed LightNorm hardware, we can achieve significant area and energy savings during the DNN training without hurting the training accuracy. This makes the proposed hardware a great candidate for the on-device training.
FlexBlock: A Flexible DNN Training Accelerator with Multi-Mode Block Floating Point Support
Mar 13, 2022
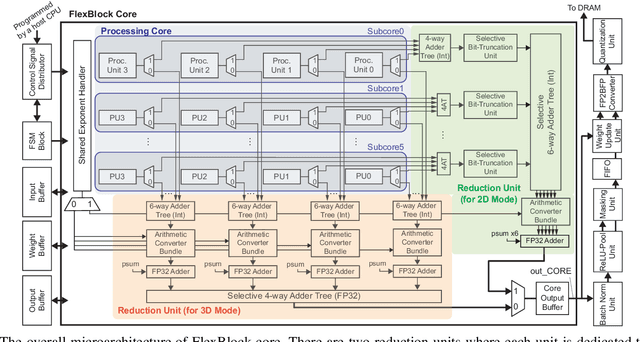
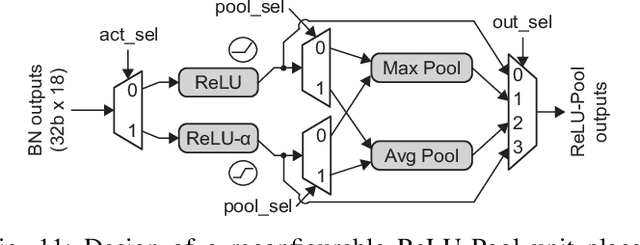
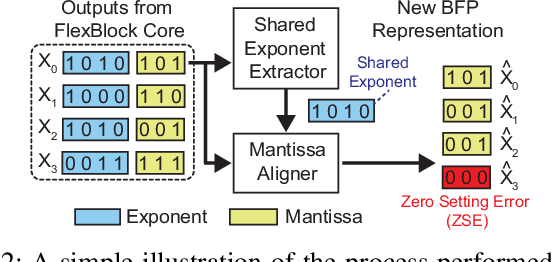
Training deep neural networks (DNNs) is a computationally expensive job, which can take weeks or months even with high performance GPUs. As a remedy for this challenge, community has started exploring the use of more efficient data representations in the training process, e.g., block floating point (BFP). However, prior work on BFP-based DNN accelerators rely on a specific BFP representation making them less versatile. This paper builds upon an algorithmic observation that we can accelerate the training by leveraging multiple BFP precisions without compromising the finally achieved accuracy. Backed up by this algorithmic opportunity, we develop a flexible DNN training accelerator, dubbed FlexBlock, which supports three different BFP precision modes, possibly different among activation, weight, and gradient tensors. While several prior works proposed such multi-precision support for DNN accelerators, not only do they focus only on the inference, but also their core utilization is suboptimal at a fixed precision and specific layer types when the training is considered. Instead, FlexBlock is designed in such a way that high core utilization is achievable for i) various layer types, and ii) three BFP precisions by mapping data in a hierarchical manner to its compute units. We evaluate the effectiveness of FlexBlock architecture using well-known DNNs on CIFAR, ImageNet and WMT14 datasets. As a result, training in FlexBlock significantly improves the training speed by 1.5~5.3x and the energy efficiency by 2.4~7.0x on average compared to other training accelerators and incurs marginal accuracy loss compared to full-precision training.