 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOPAL: Outlier-Preserved Microscaling Quantization A ccelerator for Generative Large Language Models
Sep 06, 2024



To overcome the burden on the memory size and bandwidth due to ever-increasing size of large language models (LLMs), aggressive weight quantization has been recently studied, while lacking research on quantizing activations. In this paper, we present a hardware-software co-design method that results in an energy-efficient LLM accelerator, named OPAL, for generation tasks. First of all, a novel activation quantization method that leverages the microscaling data format while preserving several outliers per sub-tensor block (e.g., four out of 128 elements) is proposed. Second, on top of preserving outliers, mixed precision is utilized that sets 5-bit for inputs to sensitive layers in the decoder block of an LLM, while keeping inputs to less sensitive layers to 3-bit. Finally, we present the OPAL hardware architecture that consists of FP units for handling outliers and vectorized INT multipliers for dominant non-outlier related operations. In addition, OPAL uses log2-based approximation on softmax operations that only requires shift and subtraction to maximize power efficiency. As a result, we are able to improve the energy efficiency by 1.6~2.2x, and reduce the area by 2.4~3.1x with negligible accuracy loss, i.e., <1 perplexity increase.
LightNorm: Area and Energy-Efficient Batch Normalization Hardware for On-Device DNN Training
Nov 04, 2022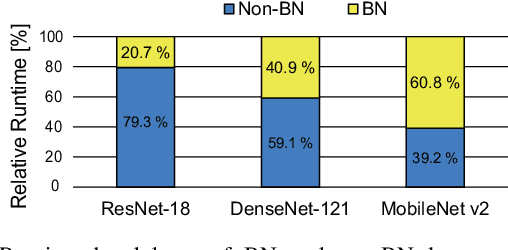
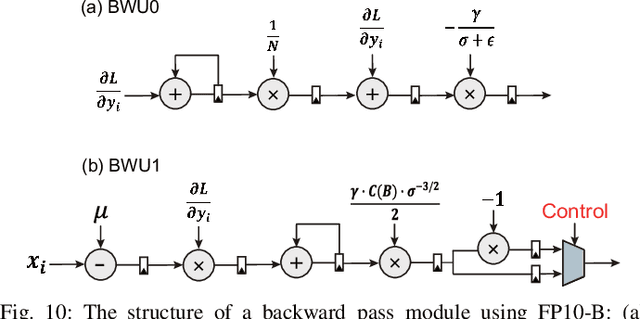
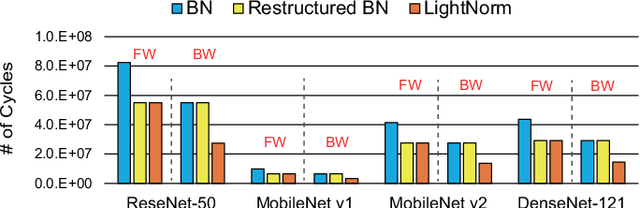
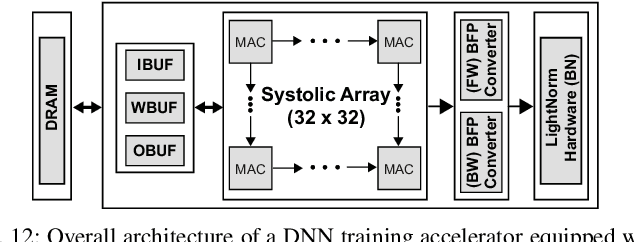
When training early-stage deep neural networks (DNNs), generating intermediate features via convolution or linear layers occupied most of the execution time. Accordingly, extensive research has been done to reduce the computational burden of the convolution or linear layers. In recent mobile-friendly DNNs, however, the relative number of operations involved in processing these layers has significantly reduced. As a result, the proportion of the execution time of other layers, such as batch normalization layers, has increased. Thus, in this work, we conduct a detailed analysis of the batch normalization layer to efficiently reduce the runtime overhead in the batch normalization process. Backed up by the thorough analysis, we present an extremely efficient batch normalization, named LightNorm, and its associated hardware module. In more detail, we fuse three approximation techniques that are i) low bit-precision, ii) range batch normalization, and iii) block floating point. All these approximate techniques are carefully utilized not only to maintain the statistics of intermediate feature maps, but also to minimize the off-chip memory accesses. By using the proposed LightNorm hardware, we can achieve significant area and energy savings during the DNN training without hurting the training accuracy. This makes the proposed hardware a great candidate for the on-device training.
ZeBRA: Precisely Destroying Neural Networks with Zero-Data Based Repeated Bit Flip Attack
Nov 18, 2021


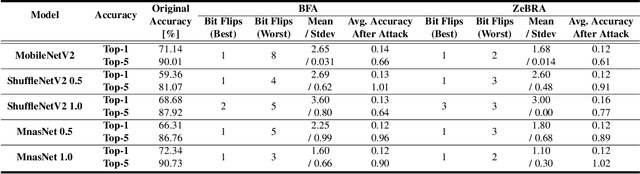
In this paper, we present Zero-data Based Repeated bit flip Attack (ZeBRA) that precisely destroys deep neural networks (DNNs) by synthesizing its own attack datasets. Many prior works on adversarial weight attack require not only the weight parameters, but also the training or test dataset in searching vulnerable bits to be attacked. We propose to synthesize the attack dataset, named distilled target data, by utilizing the statistics of batch normalization layers in the victim DNN model. Equipped with the distilled target data, our ZeBRA algorithm can search vulnerable bits in the model without accessing training or test dataset. Thus, our approach makes the adversarial weight attack more fatal to the security of DNNs. Our experimental results show that 2.0x (CIFAR-10) and 1.6x (ImageNet) less number of bit flips are required on average to destroy DNNs compared to the previous attack method. Our code is available at https://github. com/pdh930105/ZeBRA.