 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightNorm: Area and Energy-Efficient Batch Normalization Hardware for On-Device DNN Training
Nov 04, 2022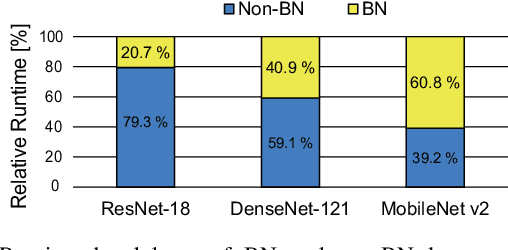
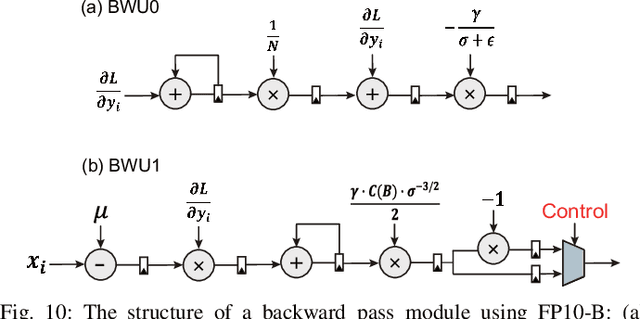
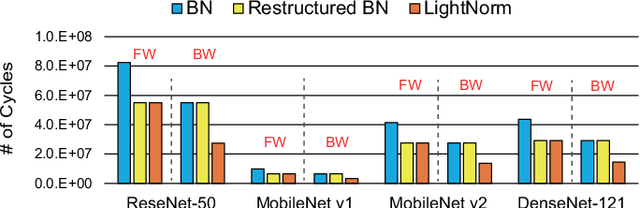
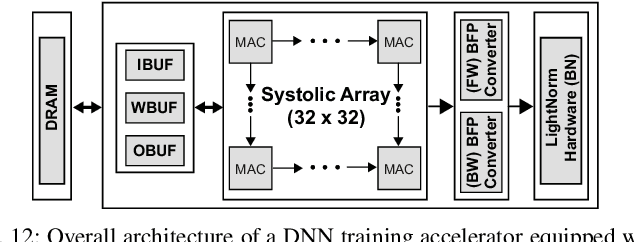
When training early-stage deep neural networks (DNNs), generating intermediate features via convolution or linear layers occupied most of the execution time. Accordingly, extensive research has been done to reduce the computational burden of the convolution or linear layers. In recent mobile-friendly DNNs, however, the relative number of operations involved in processing these layers has significantly reduced. As a result, the proportion of the execution time of other layers, such as batch normalization layers, has increased. Thus, in this work, we conduct a detailed analysis of the batch normalization layer to efficiently reduce the runtime overhead in the batch normalization process. Backed up by the thorough analysis, we present an extremely efficient batch normalization, named LightNorm, and its associated hardware module. In more detail, we fuse three approximation techniques that are i) low bit-precision, ii) range batch normalization, and iii) block floating point. All these approximate techniques are carefully utilized not only to maintain the statistics of intermediate feature maps, but also to minimize the off-chip memory accesses. By using the proposed LightNorm hardware, we can achieve significant area and energy savings during the DNN training without hurting the training accuracy. This makes the proposed hardware a great candidate for the on-device training.
FlexBlock: A Flexible DNN Training Accelerator with Multi-Mode Block Floating Point Support
Mar 13, 2022
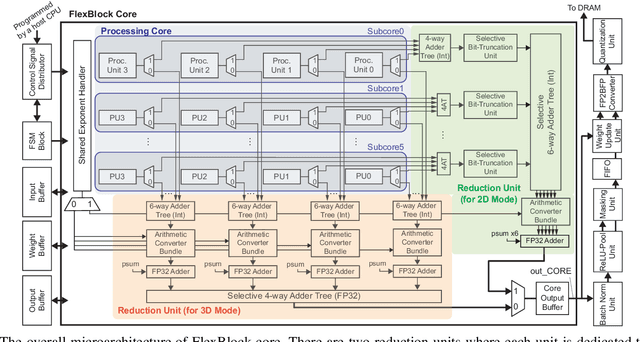
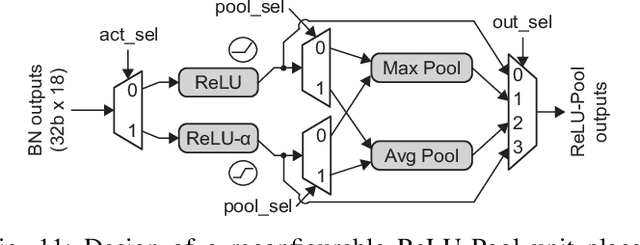
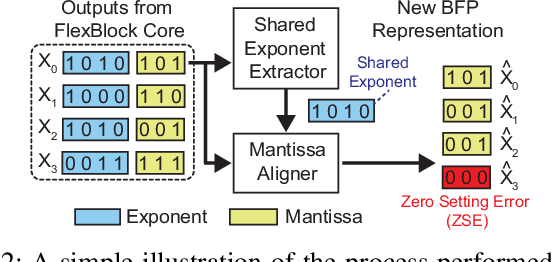
Training deep neural networks (DNNs) is a computationally expensive job, which can take weeks or months even with high performance GPUs. As a remedy for this challenge, community has started exploring the use of more efficient data representations in the training process, e.g., block floating point (BFP). However, prior work on BFP-based DNN accelerators rely on a specific BFP representation making them less versatile. This paper builds upon an algorithmic observation that we can accelerate the training by leveraging multiple BFP precisions without compromising the finally achieved accuracy. Backed up by this algorithmic opportunity, we develop a flexible DNN training accelerator, dubbed FlexBlock, which supports three different BFP precision modes, possibly different among activation, weight, and gradient tensors. While several prior works proposed such multi-precision support for DNN accelerators, not only do they focus only on the inference, but also their core utilization is suboptimal at a fixed precision and specific layer types when the training is considered. Instead, FlexBlock is designed in such a way that high core utilization is achievable for i) various layer types, and ii) three BFP precisions by mapping data in a hierarchical manner to its compute units. We evaluate the effectiveness of FlexBlock architecture using well-known DNNs on CIFAR, ImageNet and WMT14 datasets. As a result, training in FlexBlock significantly improves the training speed by 1.5~5.3x and the energy efficiency by 2.4~7.0x on average compared to other training accelerators and incurs marginal accuracy loss compared to full-precision training.