 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFRIDAY: Mitigating Unintentional Facial Identity in Deepfake Detectors Guided by Facial Recognizers
Dec 19, 2024Previous Deepfake detection methods perform well within their training domains, but their effectiveness diminishes significantly with new synthesis techniques. Recent studies have revealed that detection models often create decision boundaries based on facial identity rather than synthetic artifacts, resulting in poor performance on cross-domain datasets. To address this limitation, we propose Facial Recognition Identity Attenuation (FRIDAY), a novel training method that mitigates facial identity influence using a face recognizer. Specifically, we first train a face recognizer using the same backbone as the Deepfake detector. The recognizer is then frozen and employed during the detector's training to reduce facial identity information. This is achieved by feeding input images into both the recognizer and the detector, and minimizing the similarity of their feature embeddings through our Facial Identity Attenuating loss. This process encourages the detector to generate embeddings distinct from the recognizer, effectively reducing the impact of facial identity. Extensive experiments demonstrate that our approach significantly enhances detection performance on both in-domain and cross-domain datasets.
SAFIRE: Segment Any Forged Image Region
Dec 11, 2024



Most techniques approach the problem of image forgery localization as a binary segmentation task, training neural networks to label original areas as 0 and forged areas as 1. In contrast, we tackle this issue from a more fundamental perspective by partitioning images according to their originating sources. To this end, we propose Segment Any Forged Image Region (SAFIRE), which solves forgery localization using point prompting. Each point on an image is used to segment the source region containing itself. This allows us to partition images into multiple source regions, a capability achieved for the first time. Additionally, rather than memorizing certain forgery traces, SAFIRE naturally focuses on uniform characteristics within each source region. This approach leads to more stable and effective learning, achieving superior performance in both the new task and the traditional binary forgery localization.
* Accepted at AAAI 2025. Code is available at: https://github.com/mjkwon2021/SAFIRE
Breaking Temporal Consistency: Generating Video Universal Adversarial Perturbations Using Image Models
Nov 17, 2023As video analysis using deep learning models becomes more widespread, the vulnerability of such models to adversarial attacks is becoming a pressing concern. In particular, Universal Adversarial Perturbation (UAP) poses a significant threat, as a single perturbation can mislead deep learning models on entire datasets. We propose a novel video UAP using image data and image model. This enables us to take advantage of the rich image data and image model-based studies available for video applications. However, there is a challenge that image models are limited in their ability to analyze the temporal aspects of videos, which is crucial for a successful video attack. To address this challenge, we introduce the Breaking Temporal Consistency (BTC) method, which is the first attempt to incorporate temporal information into video attacks using image models. We aim to generate adversarial videos that have opposite patterns to the original. Specifically, BTC-UAP minimizes the feature similarity between neighboring frames in videos. Our approach is simple but effective at attacking unseen video models. Additionally, it is applicable to videos of varying lengths and invariant to temporal shifts. Our approach surpasses existing methods in terms of effectiveness on various datasets, including ImageNet, UCF-101, and Kinetics-400.
Introducing Competition to Boost the Transferability of Targeted Adversarial Examples through Clean Feature Mixup
May 24, 2023Deep neural networks are widely known to be susceptible to adversarial examples, which can cause incorrect predictions through subtle input modifications. These adversarial examples tend to be transferable between models, but targeted attacks still have lower attack success rates due to significant variations in decision boundaries. To enhance the transferability of targeted adversarial examples, we propose introducing competition into the optimization process. Our idea is to craft adversarial perturbations in the presence of two new types of competitor noises: adversarial perturbations towards different target classes and friendly perturbations towards the correct class. With these competitors, even if an adversarial example deceives a network to extract specific features leading to the target class, this disturbance can be suppressed by other competitors. Therefore, within this competition, adversarial examples should take different attack strategies by leveraging more diverse features to overwhelm their interference, leading to improving their transferability to different models. Considering the computational complexity, we efficiently simulate various interference from these two types of competitors in feature space by randomly mixing up stored clean features in the model inference and named this method Clean Feature Mixup (CFM). Our extensive experimental results on the ImageNet-Compatible and CIFAR-10 datasets show that the proposed method outperforms the existing baselines with a clear margin. Our code is available at https://github.com/dreamflake/CFM.
Improving the Transferability of Targeted Adversarial Examples through Object-Based Diverse Input
Mar 17, 2022
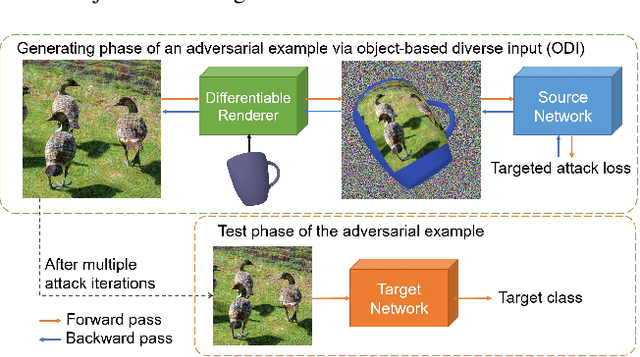
The transferability of adversarial examples allows the deception on black-box models, and transfer-based targeted attacks have attracted a lot of interest due to their practical applicability. To maximize the transfer success rate, adversarial examples should avoid overfitting to the source model, and image augmentation is one of the primary approaches for this. However, prior works utilize simple image transformations such as resizing, which limits input diversity. To tackle this limitation, we propose the object-based diverse input (ODI) method that draws an adversarial image on a 3D object and induces the rendered image to be classified as the target class. Our motivation comes from the humans' superior perception of an image printed on a 3D object. If the image is clear enough, humans can recognize the image content in a variety of viewing conditions. Likewise, if an adversarial example looks like the target class to the model, the model should also classify the rendered image of the 3D object as the target class. The ODI method effectively diversifies the input by leveraging an ensemble of multiple source objects and randomizing viewing conditions. In our experimental results on the ImageNet-Compatible dataset, this method boosts the average targeted attack success rate from 28.3% to 47.0% compared to the state-of-the-art methods. We also demonstrate the applicability of the ODI method to adversarial examples on the face verification task and its superior performance improvement. Our code is available at https://github.com/dreamflake/ODI.
Learning JPEG Compression Artifacts for Image Manipulation Detection and Localization
Aug 30, 2021
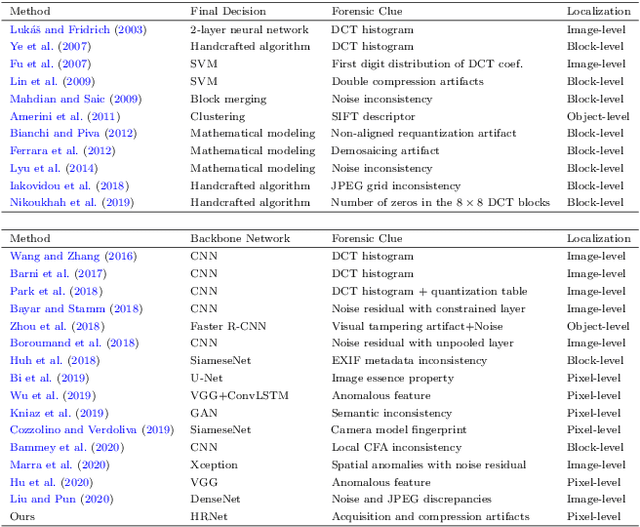
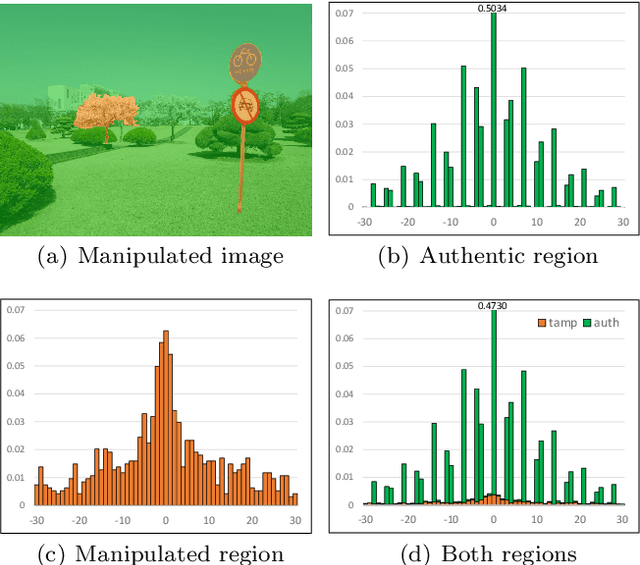
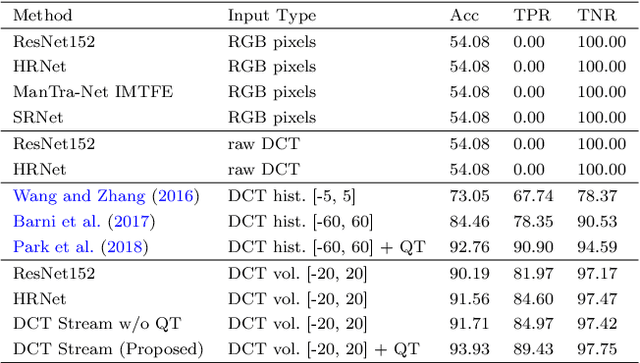
Detecting and localizing image manipulation are necessary to counter malicious use of image editing techniques. Accordingly, it is essential to distinguish between authentic and tampered regions by analyzing intrinsic statistics in an image. We focus on JPEG compression artifacts left during image acquisition and editing. We propose a convolutional neural network (CNN) that uses discrete cosine transform (DCT) coefficients, where compression artifacts remain, to localize image manipulation. Standard CNNs cannot learn the distribution of DCT coefficients because the convolution throws away the spatial coordinates, which are essential for DCT coefficients. We illustrate how to design and train a neural network that can learn the distribution of DCT coefficients. Furthermore, we introduce Compression Artifact Tracing Network (CAT-Net) that jointly uses image acquisition artifacts and compression artifacts. It significantly outperforms traditional and deep neural network-based methods in detecting and localizing tampered regions.
Detection of Double Compression in MPEG-4 Videos Using Refined Features-based CNN
Jul 19, 2021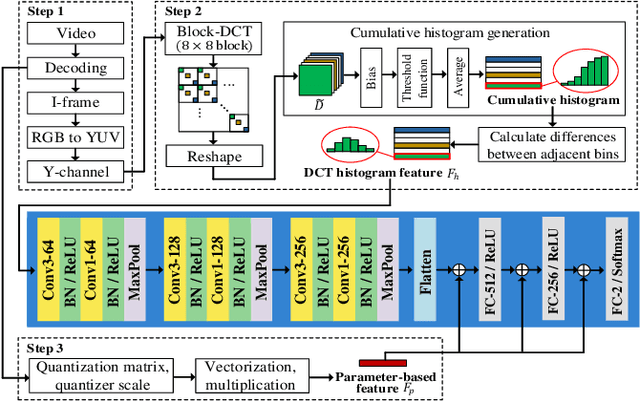
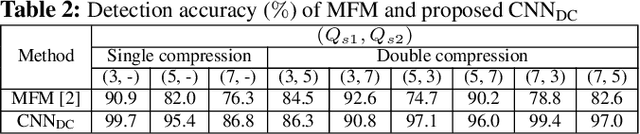
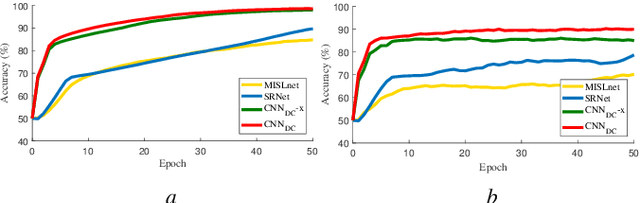
Double compression is accompanied by various types of video manipulation and its traces can be exploited to determine whether a video is a forgery. This Letter presents a convolutional neural network for detecting double compression in MPEG-4 videos. Through analysis of the intra-coding process, we utilize two refined features for capturing the subtle artifacts caused by double compression. The discrete cosine transform (DCT) histogram feature effectively detects the change of statistical characteristics in DCT coefficients and the parameter-based feature is utilized as auxiliary information to help the network learn double compression artifacts. When compared with state-of-the-art networks and forensic method, the results show that the proposed approach achieves a higher performance.
Frame-rate Up-conversion Detection Based on Convolutional Neural Network for Learning Spatiotemporal Features
Mar 25, 2021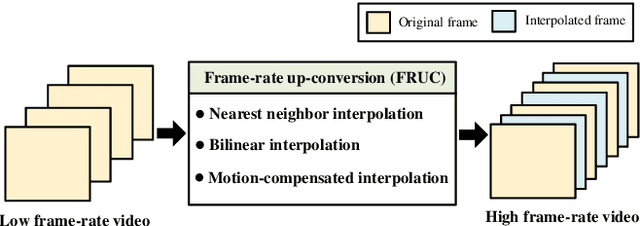
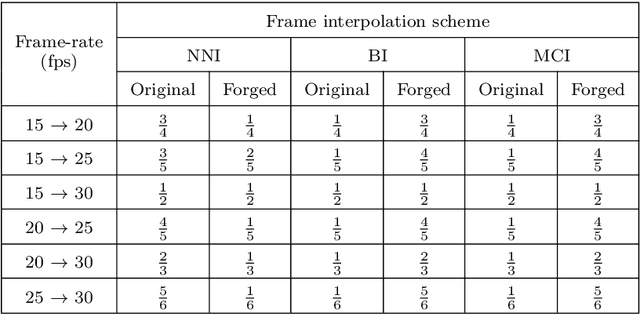
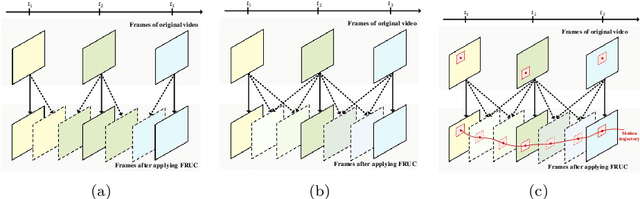
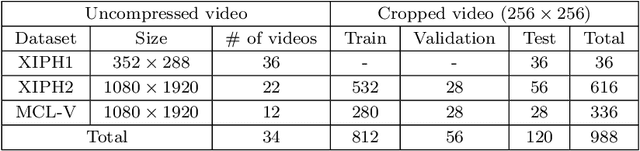
With the advance in user-friendly and powerful video editing tools, anyone can easily manipulate videos without leaving prominent visual traces. Frame-rate up-conversion (FRUC), a representative temporal-domain operation, increases the motion continuity of videos with a lower frame-rate and is used by malicious counterfeiters in video tampering such as generating fake frame-rate video without improving the quality or mixing temporally spliced videos. FRUC is based on frame interpolation schemes and subtle artifacts that remain in interpolated frames are often difficult to distinguish. Hence, detecting such forgery traces is a critical issue in video forensics. This paper proposes a frame-rate conversion detection network (FCDNet) that learns forensic features caused by FRUC in an end-to-end fashion. The proposed network uses a stack of consecutive frames as the input and effectively learns interpolation artifacts using network blocks to learn spatiotemporal features. This study is the first attempt to apply a neural network to the detection of FRUC. Moreover, it can cover the following three types of frame interpolation schemes: nearest neighbor interpolation, bilinear interpolation, and motion-compensated interpolation. In contrast to existing methods that exploit all frames to verify integrity, the proposed approach achieves a high detection speed because it observes only six frames to test its authenticity. Extensive experiments were conducted with conventional forensic methods and neural networks for video forensic tasks to validate our research. The proposed network achieved state-of-the-art performance in terms of detecting the interpolated artifacts of FRUC. The experimental results also demonstrate that our trained model is robust for an unseen dataset, unlearned frame-rate, and unlearned quality factor.
Deep Convolutional Neural Network for Identifying Seam-Carving Forgery
Jul 07, 2020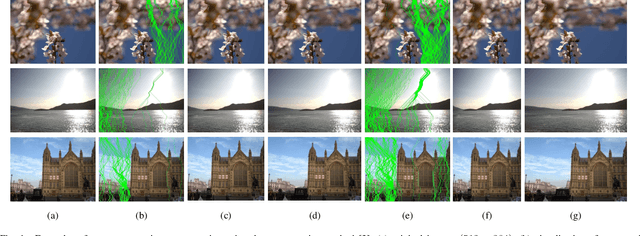
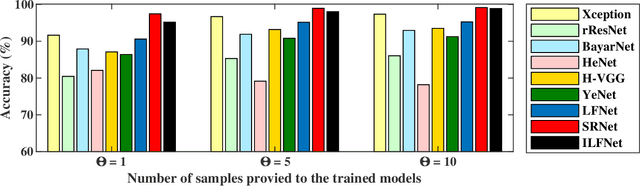

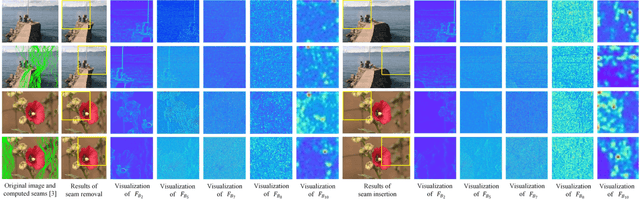
Seam carving is a representative content-aware image retargeting approach to adjust the size of an image while preserving its visually prominent content. To maintain visually important content, seam-carving algorithms first calculate the connected path of pixels, referred to as the seam, according to a defined cost function and then adjust the size of an image by removing and duplicating repeatedly calculated seams. Seam carving is actively exploited to overcome diversity in the resolution of images between applications and devices; hence, detecting the distortion caused by seam carving has become important in image forensics. In this paper, we propose a convolutional neural network (CNN)-based approach to classifying seam-carving-based image retargeting for reduction and expansion. To attain the ability to learn low-level features, we designed a CNN architecture comprising five types of network blocks specialized for capturing subtle signals. An ensemble module is further adopted to both enhance performance and comprehensively analyze the features in the local areas of the given image. To validate the effectiveness of our work, extensive experiments based on various CNN-based baselines were conducted. Compared to the baselines, our work exhibits state-of-the-art performance in terms of three-class classification (original, seam inserted, and seam removed). In addition, our model with the ensemble module is robust for various unseen cases. The experimental results also demonstrate that our method can be applied to localize both seam-removed and seam-inserted areas.