 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning JPEG Compression Artifacts for Image Manipulation Detection and Localization
Aug 30, 2021
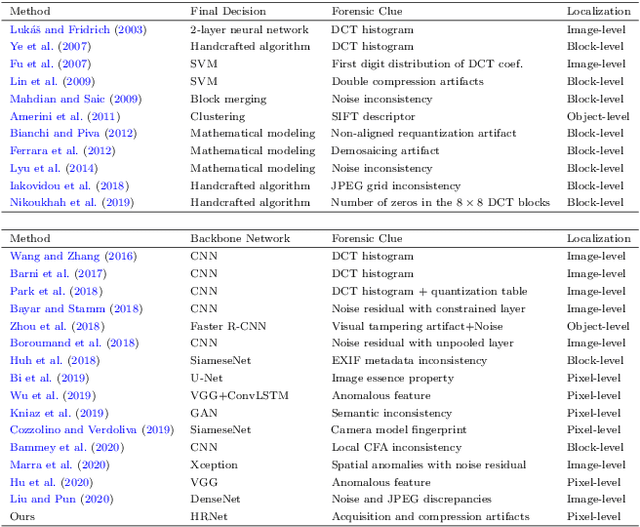
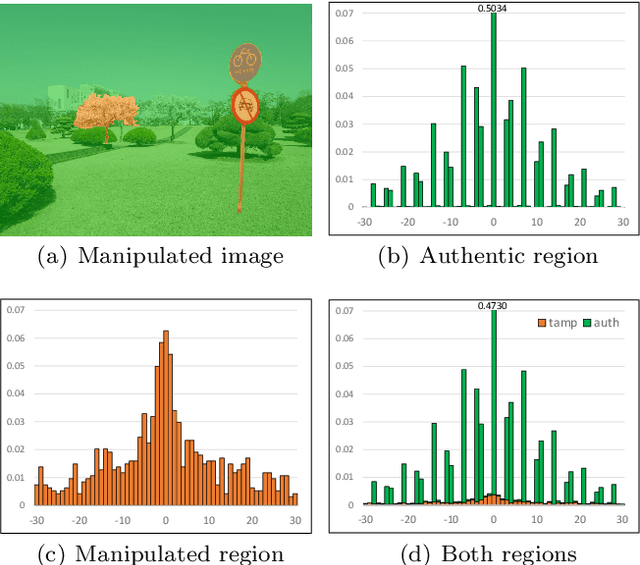
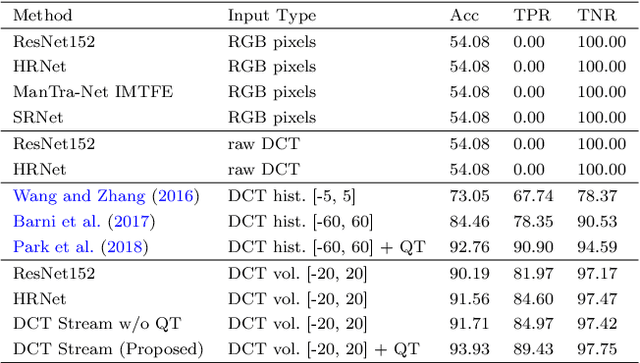
Detecting and localizing image manipulation are necessary to counter malicious use of image editing techniques. Accordingly, it is essential to distinguish between authentic and tampered regions by analyzing intrinsic statistics in an image. We focus on JPEG compression artifacts left during image acquisition and editing. We propose a convolutional neural network (CNN) that uses discrete cosine transform (DCT) coefficients, where compression artifacts remain, to localize image manipulation. Standard CNNs cannot learn the distribution of DCT coefficients because the convolution throws away the spatial coordinates, which are essential for DCT coefficients. We illustrate how to design and train a neural network that can learn the distribution of DCT coefficients. Furthermore, we introduce Compression Artifact Tracing Network (CAT-Net) that jointly uses image acquisition artifacts and compression artifacts. It significantly outperforms traditional and deep neural network-based methods in detecting and localizing tampered regions.
Frame-rate Up-conversion Detection Based on Convolutional Neural Network for Learning Spatiotemporal Features
Mar 25, 2021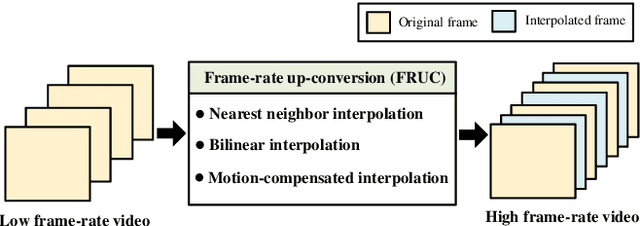
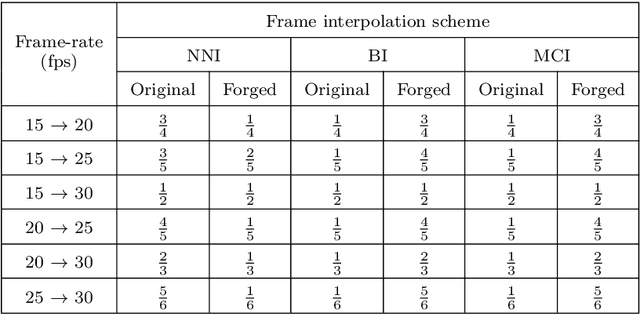
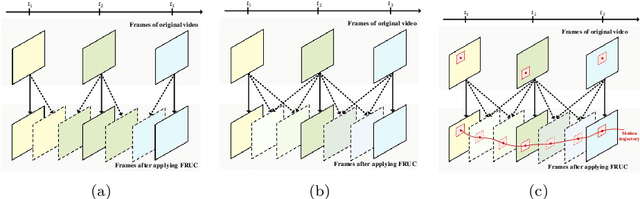
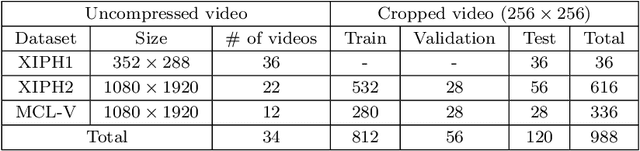
With the advance in user-friendly and powerful video editing tools, anyone can easily manipulate videos without leaving prominent visual traces. Frame-rate up-conversion (FRUC), a representative temporal-domain operation, increases the motion continuity of videos with a lower frame-rate and is used by malicious counterfeiters in video tampering such as generating fake frame-rate video without improving the quality or mixing temporally spliced videos. FRUC is based on frame interpolation schemes and subtle artifacts that remain in interpolated frames are often difficult to distinguish. Hence, detecting such forgery traces is a critical issue in video forensics. This paper proposes a frame-rate conversion detection network (FCDNet) that learns forensic features caused by FRUC in an end-to-end fashion. The proposed network uses a stack of consecutive frames as the input and effectively learns interpolation artifacts using network blocks to learn spatiotemporal features. This study is the first attempt to apply a neural network to the detection of FRUC. Moreover, it can cover the following three types of frame interpolation schemes: nearest neighbor interpolation, bilinear interpolation, and motion-compensated interpolation. In contrast to existing methods that exploit all frames to verify integrity, the proposed approach achieves a high detection speed because it observes only six frames to test its authenticity. Extensive experiments were conducted with conventional forensic methods and neural networks for video forensic tasks to validate our research. The proposed network achieved state-of-the-art performance in terms of detecting the interpolated artifacts of FRUC. The experimental results also demonstrate that our trained model is robust for an unseen dataset, unlearned frame-rate, and unlearned quality factor.
WAN: Watermarking Attack Network
Aug 14, 2020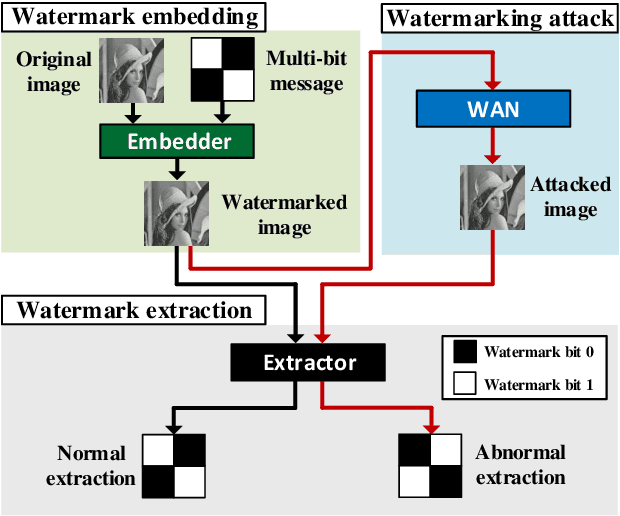

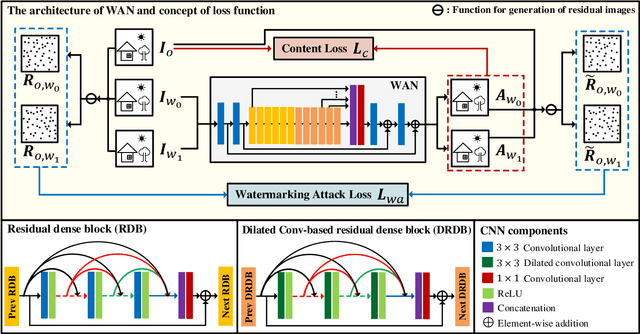

Multi-bit watermarking (MW) has been developed to improve robustness against signal processing operations and geometric distortions. To this end, several benchmark tools that simulate possible attacks on images to test robustness are available. However, limitations in these general attacks exist since they cannot exploit specific characteristics of the targeted MW. In addition, these attacks are usually devised without consideration for visual quality, which rarely occurs in the real world. To address these limitations, we propose a watermarking attack network (WAN), a fully trainable watermarking benchmark tool, that utilizes the weak points of the target MW and removes inserted watermark and inserts inverted bit information, thereby considerably reducing watermark extractability. To hinder the extraction of hidden information while ensuring high visual quality, we utilize a residual dense blocks-based architecture specialized in local and global feature learning. A novel watermarking attack loss is introduced to break the MW systems. We empirically demonstrate that the WAN can successfully fool a variety of MW systems.
Deep Convolutional Neural Network for Identifying Seam-Carving Forgery
Jul 07, 2020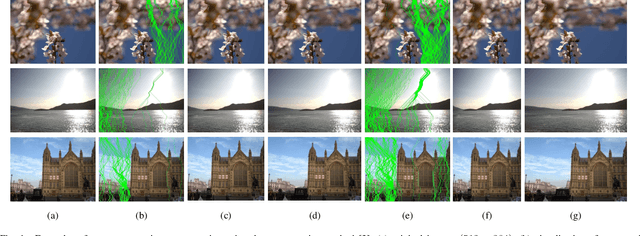
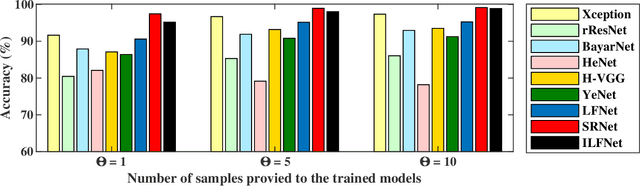

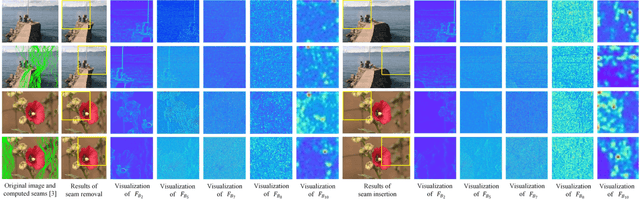
Seam carving is a representative content-aware image retargeting approach to adjust the size of an image while preserving its visually prominent content. To maintain visually important content, seam-carving algorithms first calculate the connected path of pixels, referred to as the seam, according to a defined cost function and then adjust the size of an image by removing and duplicating repeatedly calculated seams. Seam carving is actively exploited to overcome diversity in the resolution of images between applications and devices; hence, detecting the distortion caused by seam carving has become important in image forensics. In this paper, we propose a convolutional neural network (CNN)-based approach to classifying seam-carving-based image retargeting for reduction and expansion. To attain the ability to learn low-level features, we designed a CNN architecture comprising five types of network blocks specialized for capturing subtle signals. An ensemble module is further adopted to both enhance performance and comprehensively analyze the features in the local areas of the given image. To validate the effectiveness of our work, extensive experiments based on various CNN-based baselines were conducted. Compared to the baselines, our work exhibits state-of-the-art performance in terms of three-class classification (original, seam inserted, and seam removed). In addition, our model with the ensemble module is robust for various unseen cases. The experimental results also demonstrate that our method can be applied to localize both seam-removed and seam-inserted areas.
BitMix: Data Augmentation for Image Steganalysis
Jun 30, 2020
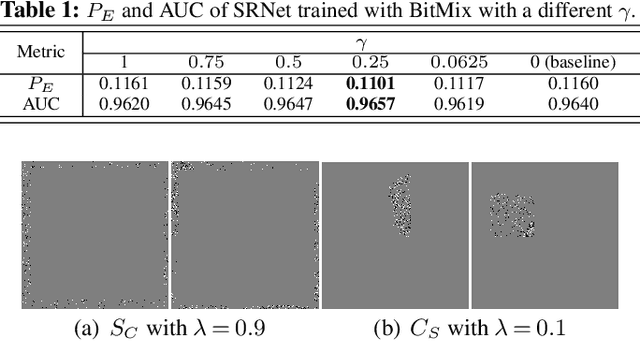
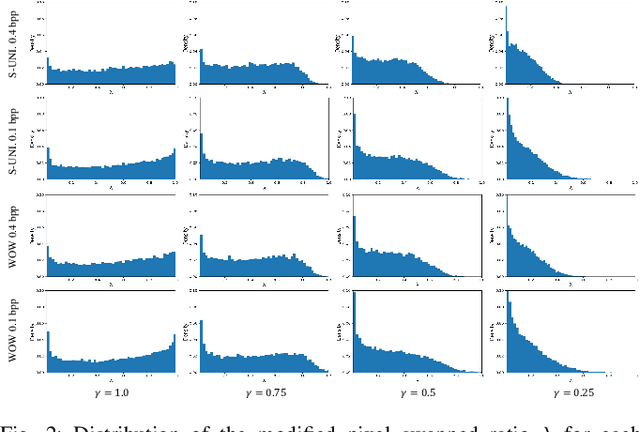
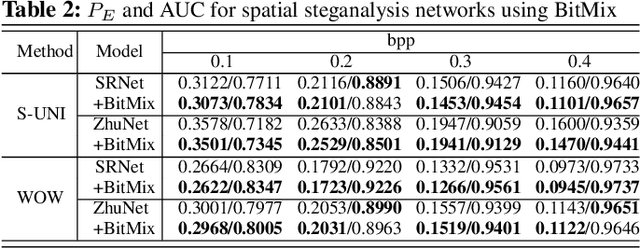
Convolutional neural networks (CNN) for image steganalysis demonstrate better performances with employing concepts from high-level vision tasks. The major employed concept is to use data augmentation to avoid overfitting due to limited data. To augment data without damaging the message embedding, only rotating multiples of 90 degrees or horizontally flipping are used in steganalysis, which generates eight fixed results from one sample. To overcome this limitation, we propose BitMix, a data augmentation method for spatial image steganalysis. BitMix mixes a cover and stego image pair by swapping the random patch and generates an embedding adaptive label with the ratio of the number of pixels modified in the swapped patch to those in the cover-stego pair. We explore optimal hyperparameters, the ratio of applying BitMix in the mini-batch, and the size of the bounding box for swapping patch. The results reveal that using BitMix improves the performance of spatial image steganalysis and better than other data augmentation methods.
Learning deep features for source color laser printer identification based on cascaded learning
Nov 01, 2017

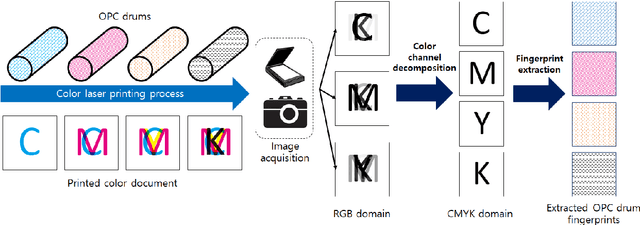
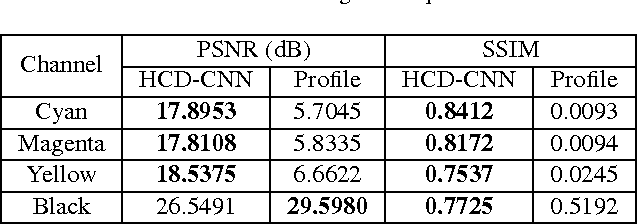
Color laser printers have fast printing speed and high resolution, and forgeries using color laser printers can cause significant harm to society. A source printer identification technique can be employed as a countermeasure to those forgeries. This paper presents a color laser printer identification method based on cascaded learning of deep neural networks. The refiner network is trained by adversarial training to refine the synthetic dataset for halftone color decomposition. The halftone color decomposing ConvNet is trained with the refined dataset, and the trained knowledge is transferred to the printer identifying ConvNet to enhance the accuracy. The robustness about rotation and scaling is considered in training process, which is not considered in existing methods. Experiments are performed on eight color laser printers, and the performance is compared with several existing methods. The experimental results clearly show that the proposed method outperforms existing source color laser printer identification methods.