 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePR-IQA: Partial-Reference Image Quality Assessment for Diffusion-Based Novel View Synthesis
Apr 07, 2026Diffusion models are promising for sparse-view novel view synthesis (NVS), as they can generate pseudo-ground-truth views to aid 3D reconstruction pipelines like 3D Gaussian Splatting (3DGS). However, these synthesized images often contain photometric and geometric inconsistencies, and their direct use for supervision can impair reconstruction. To address this, we propose Partial-Reference Image Quality Assessment (PR-IQA), a framework that evaluates diffusion-generated views using reference images from different poses, eliminating the need for ground truth. PR-IQA first computes a geometrically consistent partial quality map in overlapping regions. It then performs quality completion to inpaint this partial map into a dense, full-image map. This completion is achieved via a cross-attention mechanism that incorporates reference-view context, ensuring cross-view consistency and enabling thorough quality assessment. When integrated into a diffusion-augmented 3DGS pipeline, PR-IQA restricts supervision to high-confidence regions identified by its quality maps. Experiments demonstrate that PR-IQA outperforms existing IQA methods, achieving full-reference-level accuracy without ground-truth supervision. Thus, our quality-aware 3DGS approach more effectively filters inconsistencies, producing superior 3D reconstructions and NVS results. The project page is available at https://kakaomacao.github.io/pr-iqa-project-page/.
VisAgent: Narrative-Preserving Story Visualization Framework
Mar 04, 2025Story visualization is the transformation of narrative elements into image sequences. While existing research has primarily focused on visual contextual coherence, the deeper narrative essence of stories often remains overlooked. This limitation hinders the practical application of these approaches, as generated images frequently fail to capture the intended meaning and nuances of the narrative fully. To address these challenges, we propose VisAgent, a training-free multi-agent framework designed to comprehend and visualize pivotal scenes within a given story. By considering story distillation, semantic consistency, and contextual coherence, VisAgent employs an agentic workflow. In this workflow, multiple specialized agents collaborate to: (i) refine layered prompts based on the narrative structure and (ii) seamlessly integrate \gt{generated} elements, including refined prompts, scene elements, and subject placement, into the final image. The empirically validated effectiveness confirms the framework's suitability for practical story visualization applications.
Nearly Zero-Cost Protection Against Mimicry by Personalized Diffusion Models
Dec 16, 2024Recent advancements in diffusion models revolutionize image generation but pose risks of misuse, such as replicating artworks or generating deepfakes. Existing image protection methods, though effective, struggle to balance protection efficacy, invisibility, and latency, thus limiting practical use. We introduce perturbation pre-training to reduce latency and propose a mixture-of-perturbations approach that dynamically adapts to input images to minimize performance degradation. Our novel training strategy computes protection loss across multiple VAE feature spaces, while adaptive targeted protection at inference enhances robustness and invisibility. Experiments show comparable protection performance with improved invisibility and drastically reduced inference time. The code and demo are available at \url{https://webtoon.github.io/impasto}
SAFIRE: Segment Any Forged Image Region
Dec 11, 2024



Most techniques approach the problem of image forgery localization as a binary segmentation task, training neural networks to label original areas as 0 and forged areas as 1. In contrast, we tackle this issue from a more fundamental perspective by partitioning images according to their originating sources. To this end, we propose Segment Any Forged Image Region (SAFIRE), which solves forgery localization using point prompting. Each point on an image is used to segment the source region containing itself. This allows us to partition images into multiple source regions, a capability achieved for the first time. Additionally, rather than memorizing certain forgery traces, SAFIRE naturally focuses on uniform characteristics within each source region. This approach leads to more stable and effective learning, achieving superior performance in both the new task and the traditional binary forgery localization.
* Accepted at AAAI 2025. Code is available at: https://github.com/mjkwon2021/SAFIRE
Imperceptible Protection against Style Imitation from Diffusion Models
Mar 28, 2024Recent progress in diffusion models has profoundly enhanced the fidelity of image generation. However, this has raised concerns about copyright infringements. While prior methods have introduced adversarial perturbations to prevent style imitation, most are accompanied by the degradation of artworks' visual quality. Recognizing the importance of maintaining this, we develop a visually improved protection method that preserves its protection capability. To this end, we create a perceptual map to identify areas most sensitive to human eyes. We then adjust the protection intensity guided by an instance-aware refinement. We also integrate a perceptual constraints bank to further improve the imperceptibility. Results show that our method substantially elevates the quality of the protected image without compromising on protection efficacy.
A Framework for Portrait Stylization with Skin-Tone Awareness and Nudity Identification
Mar 21, 2024
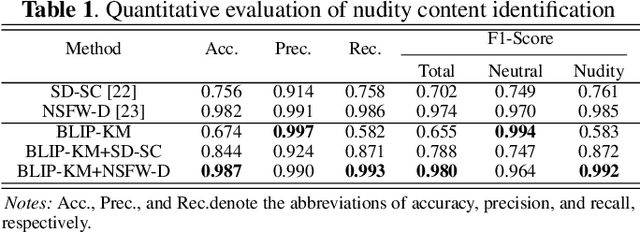
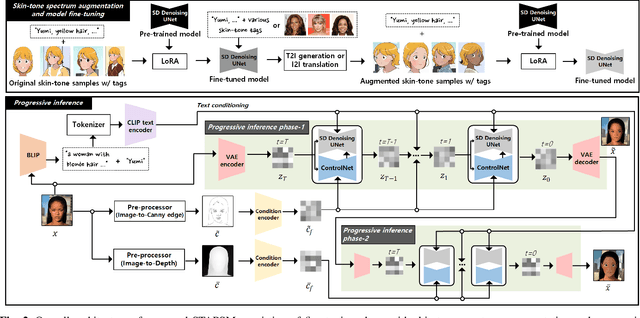

Portrait stylization is a challenging task involving the transformation of an input portrait image into a specific style while preserving its inherent characteristics. The recent introduction of Stable Diffusion (SD) has significantly improved the quality of outcomes in this field. However, a practical stylization framework that can effectively filter harmful input content and preserve the distinct characteristics of an input, such as skin-tone, while maintaining the quality of stylization remains lacking. These challenges have hindered the wide deployment of such a framework. To address these issues, this study proposes a portrait stylization framework that incorporates a nudity content identification module (NCIM) and a skin-tone-aware portrait stylization module (STAPSM). In experiments, NCIM showed good performance in enhancing explicit content filtering, and STAPSM accurately represented a diverse range of skin tones. Our proposed framework has been successfully deployed in practice, and it has effectively satisfied critical requirements of real-world applications.
DreamStyler: Paint by Style Inversion with Text-to-Image Diffusion Models
Sep 13, 2023Recent progresses in large-scale text-to-image models have yielded remarkable accomplishments, finding various applications in art domain. However, expressing unique characteristics of an artwork (e.g. brushwork, colortone, or composition) with text prompts alone may encounter limitations due to the inherent constraints of verbal description. To this end, we introduce DreamStyler, a novel framework designed for artistic image synthesis, proficient in both text-to-image synthesis and style transfer. DreamStyler optimizes a multi-stage textual embedding with a context-aware text prompt, resulting in prominent image quality. In addition, with content and style guidance, DreamStyler exhibits flexibility to accommodate a range of style references. Experimental results demonstrate its superior performance across multiple scenarios, suggesting its promising potential in artistic product creation.
Learning JPEG Compression Artifacts for Image Manipulation Detection and Localization
Aug 30, 2021
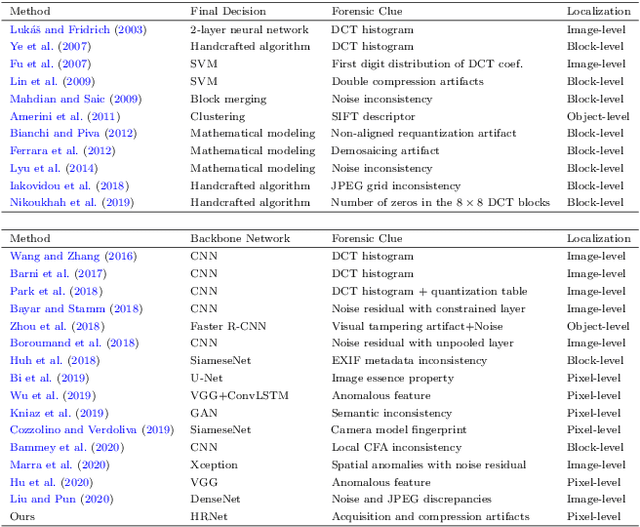
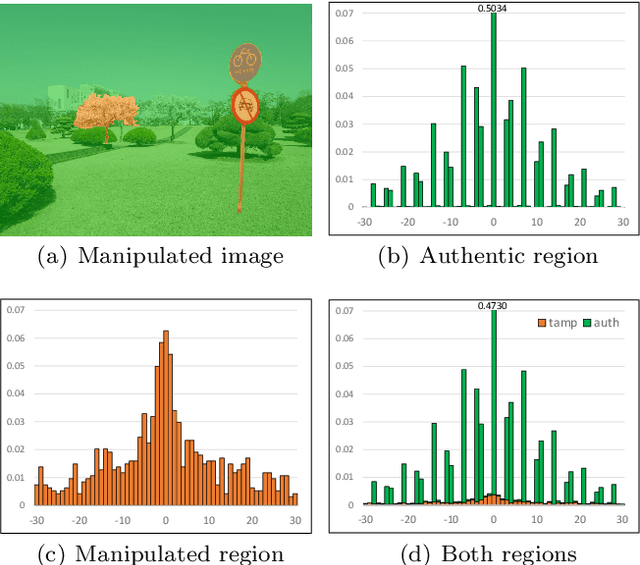
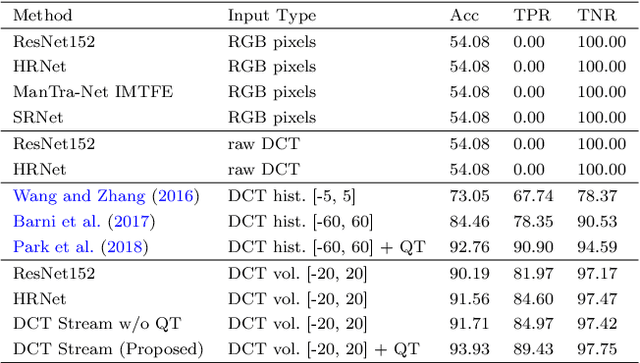
Detecting and localizing image manipulation are necessary to counter malicious use of image editing techniques. Accordingly, it is essential to distinguish between authentic and tampered regions by analyzing intrinsic statistics in an image. We focus on JPEG compression artifacts left during image acquisition and editing. We propose a convolutional neural network (CNN) that uses discrete cosine transform (DCT) coefficients, where compression artifacts remain, to localize image manipulation. Standard CNNs cannot learn the distribution of DCT coefficients because the convolution throws away the spatial coordinates, which are essential for DCT coefficients. We illustrate how to design and train a neural network that can learn the distribution of DCT coefficients. Furthermore, we introduce Compression Artifact Tracing Network (CAT-Net) that jointly uses image acquisition artifacts and compression artifacts. It significantly outperforms traditional and deep neural network-based methods in detecting and localizing tampered regions.
Detection of Double Compression in MPEG-4 Videos Using Refined Features-based CNN
Jul 19, 2021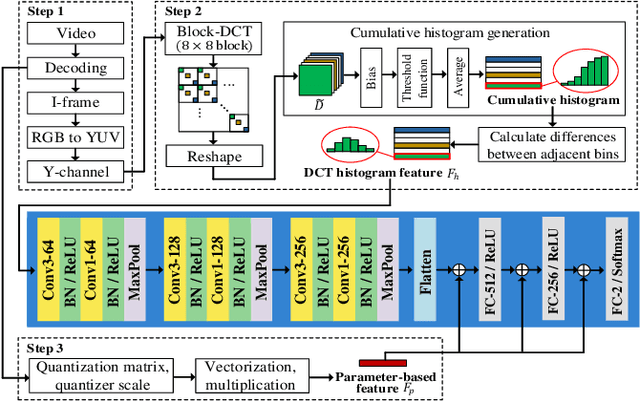
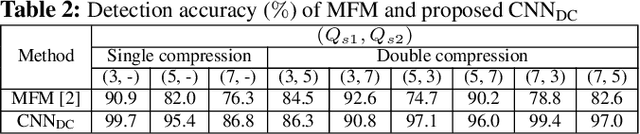
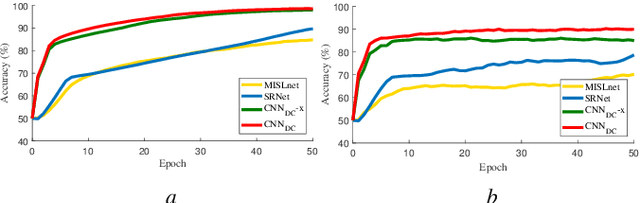
Double compression is accompanied by various types of video manipulation and its traces can be exploited to determine whether a video is a forgery. This Letter presents a convolutional neural network for detecting double compression in MPEG-4 videos. Through analysis of the intra-coding process, we utilize two refined features for capturing the subtle artifacts caused by double compression. The discrete cosine transform (DCT) histogram feature effectively detects the change of statistical characteristics in DCT coefficients and the parameter-based feature is utilized as auxiliary information to help the network learn double compression artifacts. When compared with state-of-the-art networks and forensic method, the results show that the proposed approach achieves a higher performance.
Frame-rate Up-conversion Detection Based on Convolutional Neural Network for Learning Spatiotemporal Features
Mar 25, 2021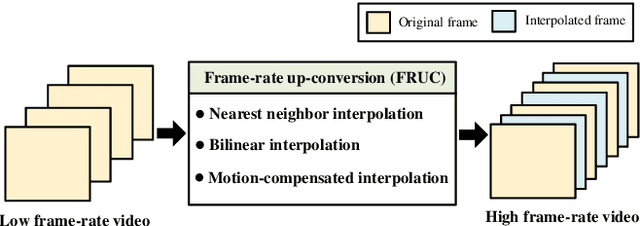
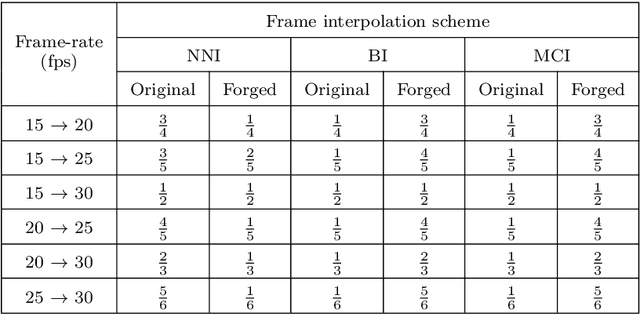
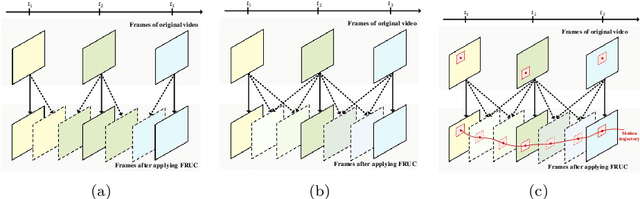
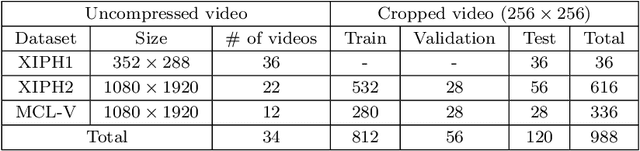
With the advance in user-friendly and powerful video editing tools, anyone can easily manipulate videos without leaving prominent visual traces. Frame-rate up-conversion (FRUC), a representative temporal-domain operation, increases the motion continuity of videos with a lower frame-rate and is used by malicious counterfeiters in video tampering such as generating fake frame-rate video without improving the quality or mixing temporally spliced videos. FRUC is based on frame interpolation schemes and subtle artifacts that remain in interpolated frames are often difficult to distinguish. Hence, detecting such forgery traces is a critical issue in video forensics. This paper proposes a frame-rate conversion detection network (FCDNet) that learns forensic features caused by FRUC in an end-to-end fashion. The proposed network uses a stack of consecutive frames as the input and effectively learns interpolation artifacts using network blocks to learn spatiotemporal features. This study is the first attempt to apply a neural network to the detection of FRUC. Moreover, it can cover the following three types of frame interpolation schemes: nearest neighbor interpolation, bilinear interpolation, and motion-compensated interpolation. In contrast to existing methods that exploit all frames to verify integrity, the proposed approach achieves a high detection speed because it observes only six frames to test its authenticity. Extensive experiments were conducted with conventional forensic methods and neural networks for video forensic tasks to validate our research. The proposed network achieved state-of-the-art performance in terms of detecting the interpolated artifacts of FRUC. The experimental results also demonstrate that our trained model is robust for an unseen dataset, unlearned frame-rate, and unlearned quality factor.