 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisAgent: Narrative-Preserving Story Visualization Framework
Mar 04, 2025Story visualization is the transformation of narrative elements into image sequences. While existing research has primarily focused on visual contextual coherence, the deeper narrative essence of stories often remains overlooked. This limitation hinders the practical application of these approaches, as generated images frequently fail to capture the intended meaning and nuances of the narrative fully. To address these challenges, we propose VisAgent, a training-free multi-agent framework designed to comprehend and visualize pivotal scenes within a given story. By considering story distillation, semantic consistency, and contextual coherence, VisAgent employs an agentic workflow. In this workflow, multiple specialized agents collaborate to: (i) refine layered prompts based on the narrative structure and (ii) seamlessly integrate \gt{generated} elements, including refined prompts, scene elements, and subject placement, into the final image. The empirically validated effectiveness confirms the framework's suitability for practical story visualization applications.
MatteFormer: Transformer-Based Image Matting via Prior-Tokens
Mar 29, 2022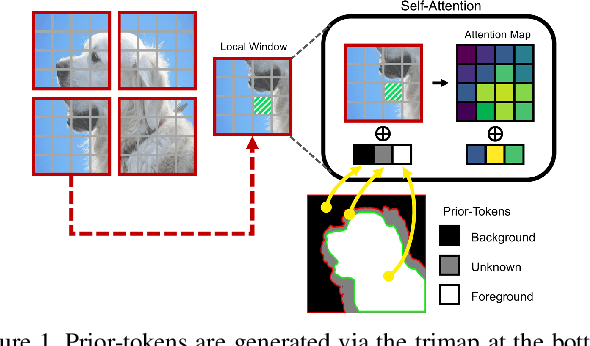


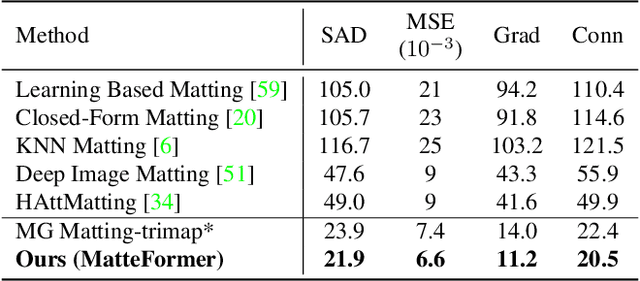
In this paper, we propose a transformer-based image matting model called MatteFormer, which takes full advantage of trimap information in the transformer block. Our method first introduces a prior-token which is a global representation of each trimap region (e.g. foreground, background and unknown). These prior-tokens are used as global priors and participate in the self-attention mechanism of each block. Each stage of the encoder is composed of PAST (Prior-Attentive Swin Transformer) block, which is based on the Swin Transformer block, but differs in a couple of aspects: 1) It has PA-WSA (Prior-Attentive Window Self-Attention) layer, performing self-attention not only with spatial-tokens but also with prior-tokens. 2) It has prior-memory which saves prior-tokens accumulatively from the previous blocks and transfers them to the next block. We evaluate our MatteFormer on the commonly used image matting datasets: Composition-1k and Distinctions-646. Experiment results show that our proposed method achieves state-of-the-art performance with a large margin. Our codes are available at https://github.com/webtoon/matteformer.