 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoMamba: Spatio-Temporal Selective State Space Model
Jul 11, 2024



We introduce VideoMamba, a novel adaptation of the pure Mamba architecture, specifically designed for video recognition. Unlike transformers that rely on self-attention mechanisms leading to high computational costs by quadratic complexity, VideoMamba leverages Mamba's linear complexity and selective SSM mechanism for more efficient processing. The proposed Spatio-Temporal Forward and Backward SSM allows the model to effectively capture the complex relationship between non-sequential spatial and sequential temporal information in video. Consequently, VideoMamba is not only resource-efficient but also effective in capturing long-range dependency in videos, demonstrated by competitive performance and outstanding efficiency on a variety of video understanding benchmarks. Our work highlights the potential of VideoMamba as a powerful tool for video understanding, offering a simple yet effective baseline for future research in video analysis.
Multi-image Super-resolution via Quality Map Associated Temporal Attention Network
Feb 26, 2022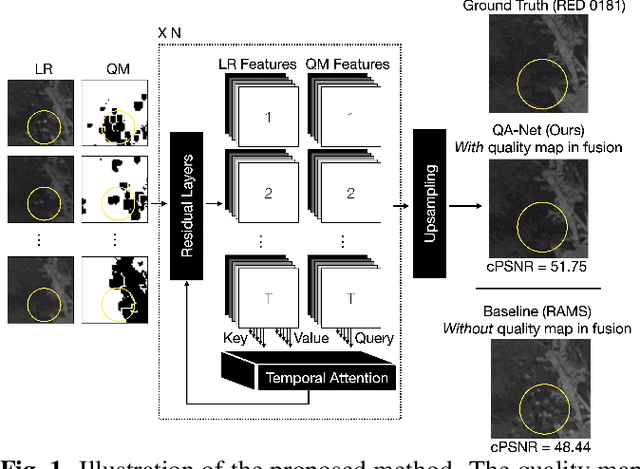
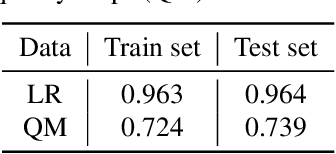
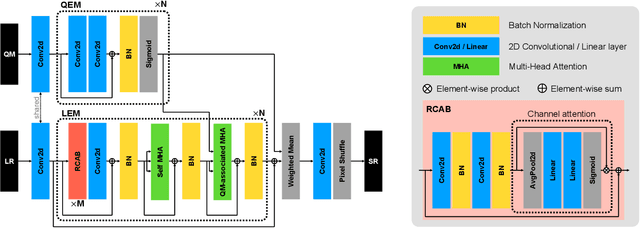
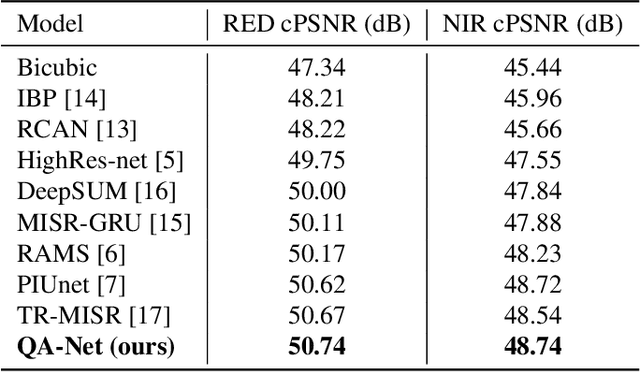
With the rising interest in deep learning-based methods in remote sensing, neural networks have made remarkable advancements in multi-image fusion and super-resolution. To fully exploit the advantages of multi-image super-resolution, temporal attention is crucial as it allows a model to focus on reliable features rather than noises. Despite the presence of quality maps (QMs) that indicate noises in images, most of the methods tested in the PROBA-V dataset have not been used QMs for temporal attention. We present a quality map associated temporal attention network (QA-Net), a novel method that incorporates QMs into both feature representation and fusion processes for the first time. Low-resolution features are temporally attended by QM features in repeated multi-head attention modules. The proposed method achieved state-of-the-art results in the PROBA-V dataset.