 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Self-Attention Network with Temporal Alignment for Audio-Visual Emotion Recognition
Mar 11, 2026Audio-visual emotion recognition (AVER) methods typically fuse utterance-level features, and even frame-level attention models seldom address the frame-rate mismatch across modalities. In this paper, we propose a Transformer-based framework focusing on the temporal alignment of multimodal features. Our design employs a multimodal self-attention encoder that simultaneously captures intra- and inter-modal dependencies within a shared feature space. To address heterogeneous sampling rates, we incorporate Temporally-aligned Rotary Position Embeddings (TaRoPE), which implicitly synchronize audio and video tokens. Furthermore, we introduce a Cross-Temporal Matching (CTM) loss that enforces consistency among temporally proximate pairs, guiding the encoder toward better alignment. Experiments on CREMA-D and RAVDESS datasets demonstrate consistent improvements over recent baselines, suggesting that explicitly addressing frame-rate mismatch helps preserve temporal cues and enhances cross-modal fusion.
Difficulty-aware Balancing Margin Loss for Long-tailed Recognition
Dec 20, 2024When trained with severely imbalanced data, deep neural networks often struggle to accurately recognize classes with only a few samples. Previous studies in long-tailed recognition have attempted to rebalance biased learning using known sample distributions, primarily addressing different classification difficulties at the class level. However, these approaches often overlook the instance difficulty variation within each class. In this paper, we propose a difficulty-aware balancing margin (DBM) loss, which considers both class imbalance and instance difficulty. DBM loss comprises two components: a class-wise margin to mitigate learning bias caused by imbalanced class frequencies, and an instance-wise margin assigned to hard positive samples based on their individual difficulty. DBM loss improves class discriminativity by assigning larger margins to more difficult samples. Our method seamlessly combines with existing approaches and consistently improves performance across various long-tailed recognition benchmarks.
DiffRef3D: A Diffusion-based Proposal Refinement Framework for 3D Object Detection
Oct 25, 2023Denoising diffusion models show remarkable performances in generative tasks, and their potential applications in perception tasks are gaining interest. In this paper, we introduce a novel framework named DiffRef3D which adopts the diffusion process on 3D object detection with point clouds for the first time. Specifically, we formulate the proposal refinement stage of two-stage 3D object detectors as a conditional diffusion process. During training, DiffRef3D gradually adds noise to the residuals between proposals and target objects, then applies the noisy residuals to proposals to generate hypotheses. The refinement module utilizes these hypotheses to denoise the noisy residuals and generate accurate box predictions. In the inference phase, DiffRef3D generates initial hypotheses by sampling noise from a Gaussian distribution as residuals and refines the hypotheses through iterative steps. DiffRef3D is a versatile proposal refinement framework that consistently improves the performance of existing 3D object detection models. We demonstrate the significance of DiffRef3D through extensive experiments on the KITTI benchmark. Code will be available.
PG-RCNN: Semantic Surface Point Generation for 3D Object Detection
Jul 24, 2023One of the main challenges in LiDAR-based 3D object detection is that the sensors often fail to capture the complete spatial information about the objects due to long distance and occlusion. Two-stage detectors with point cloud completion approaches tackle this problem by adding more points to the regions of interest (RoIs) with a pre-trained network. However, these methods generate dense point clouds of objects for all region proposals, assuming that objects always exist in the RoIs. This leads to the indiscriminate point generation for incorrect proposals as well. Motivated by this, we propose Point Generation R-CNN (PG-RCNN), a novel end-to-end detector that generates semantic surface points of foreground objects for accurate detection. Our method uses a jointly trained RoI point generation module to process the contextual information of RoIs and estimate the complete shape and displacement of foreground objects. For every generated point, PG-RCNN assigns a semantic feature that indicates the estimated foreground probability. Extensive experiments show that the point clouds generated by our method provide geometrically and semantically rich information for refining false positive and misaligned proposals. PG-RCNN achieves competitive performance on the KITTI benchmark, with significantly fewer parameters than state-of-the-art models. The code is available at https://github.com/quotation2520/PG-RCNN.
Multi-image Super-resolution via Quality Map Associated Temporal Attention Network
Feb 26, 2022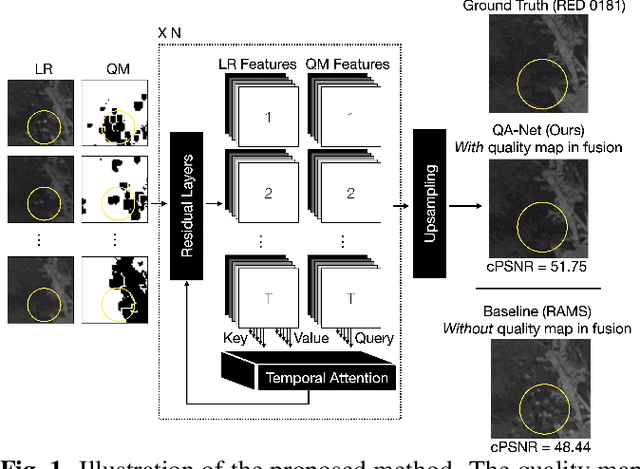
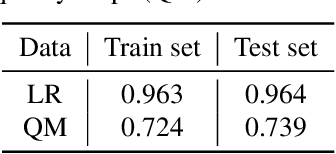
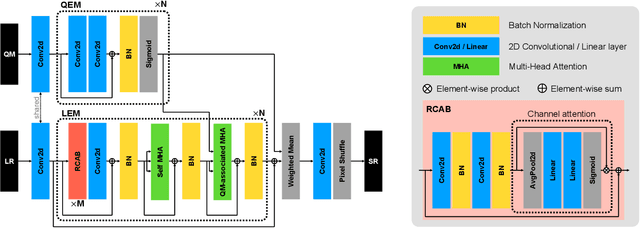
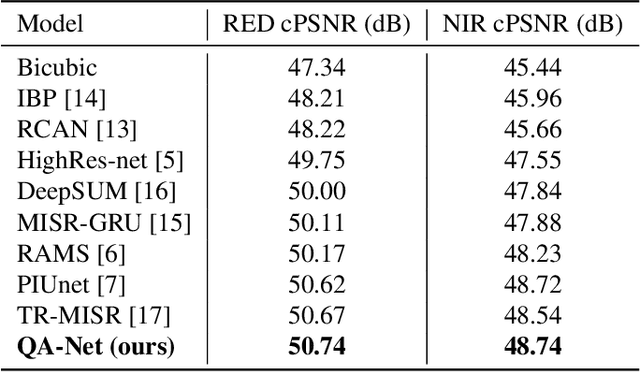
With the rising interest in deep learning-based methods in remote sensing, neural networks have made remarkable advancements in multi-image fusion and super-resolution. To fully exploit the advantages of multi-image super-resolution, temporal attention is crucial as it allows a model to focus on reliable features rather than noises. Despite the presence of quality maps (QMs) that indicate noises in images, most of the methods tested in the PROBA-V dataset have not been used QMs for temporal attention. We present a quality map associated temporal attention network (QA-Net), a novel method that incorporates QMs into both feature representation and fusion processes for the first time. Low-resolution features are temporally attended by QM features in repeated multi-head attention modules. The proposed method achieved state-of-the-art results in the PROBA-V dataset.
Explore and Match: End-to-End Video Grounding with Transformer
Jan 25, 2022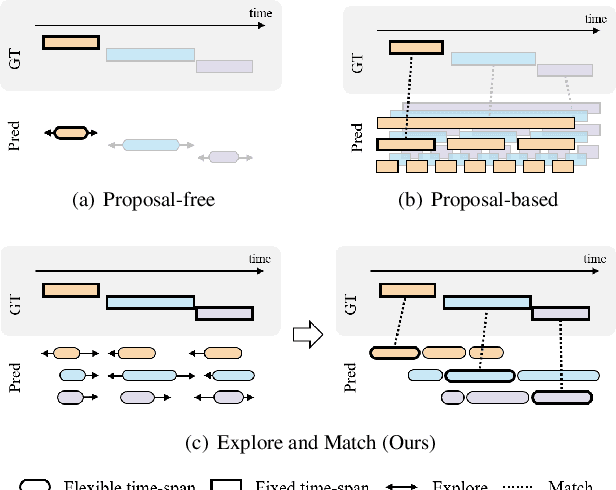
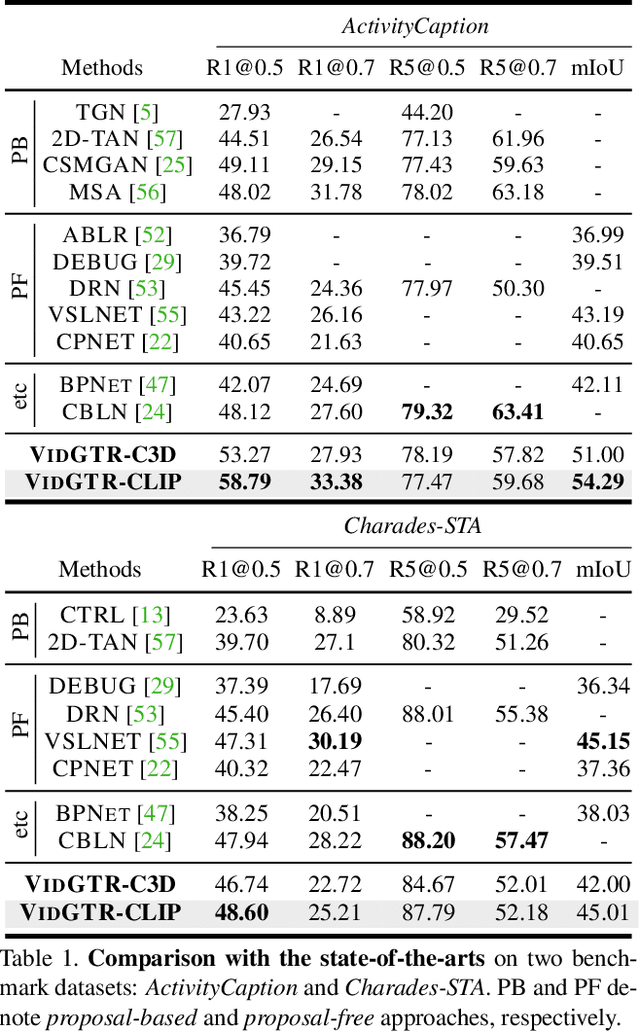
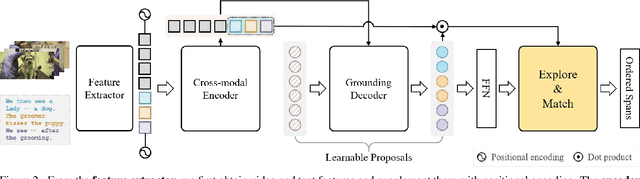
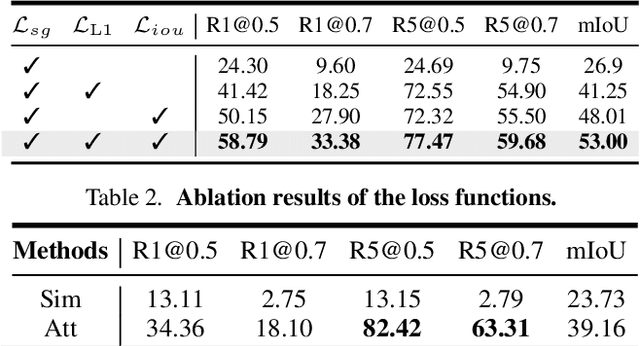
We present a new paradigm named explore-and-match for video grounding, which aims to seamlessly unify two streams of video grounding methods: proposal-based and proposal-free. To achieve this goal, we formulate video grounding as a set prediction problem and design an end-to-end trainable Video Grounding Transformer (VidGTR) that can utilize the architectural strengths of rich contextualization and parallel decoding for set prediction. The overall training is balanced by two key losses that play different roles, namely span localization loss and set guidance loss. These two losses force each proposal to regress the target timespan and identify the target query. Throughout the training, VidGTR first explores the search space to diversify the initial proposals and then matches the proposals to the corresponding targets to fit them in a fine-grained manner. The explore-and-match scheme successfully combines the strengths of two complementary methods, without encoding prior knowledge into the pipeline. As a result, VidGTR sets new state-of-the-art results on two video grounding benchmarks with double the inference speed.
Improving Few-shot Learning with Weakly-supervised Object Localization
May 25, 2021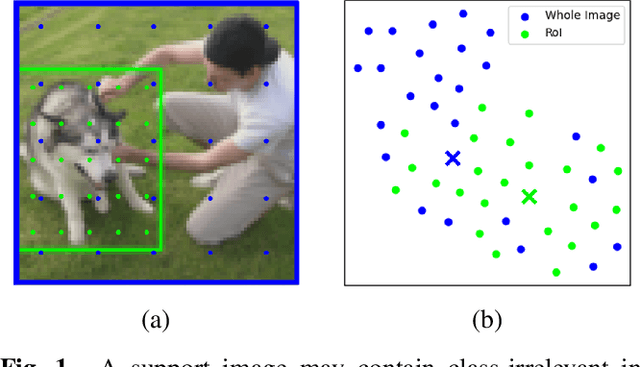
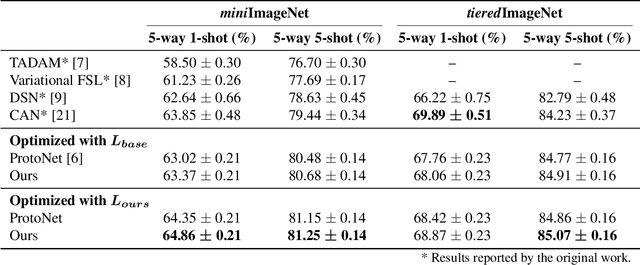
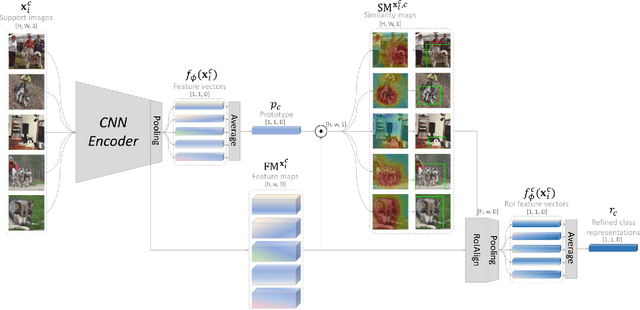

Few-shot learning often involves metric learning-based classifiers, which predict the image label by comparing the distance between the extracted feature vector and class representations. However, applying global pooling in the backend of the feature extractor may not produce an embedding that correctly focuses on the class object. In this work, we propose a novel framework that generates class representations by extracting features from class-relevant regions of the images. Given only a few exemplary images with image-level labels, our framework first localizes the class objects by spatially decomposing the similarity between the images and their class prototypes. Then, enhanced class representations are achieved from the localization results. We also propose a loss function to enhance distinctions of the refined features. Our method outperforms the baseline few-shot model in miniImageNet and tieredImageNet benchmarks.