 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplore and Match: End-to-End Video Grounding with Transformer
Paper and Code
Jan 25, 2022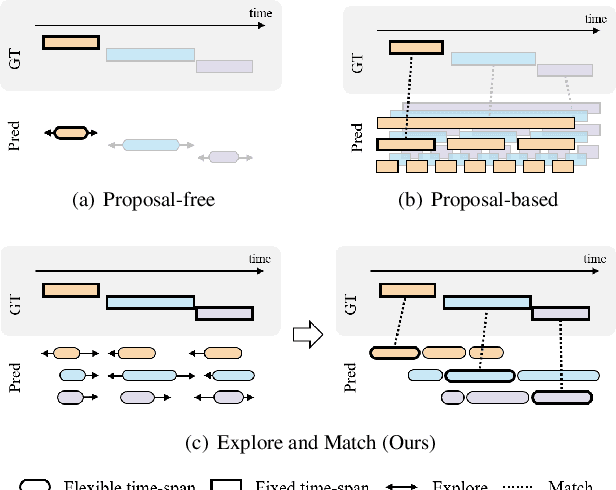
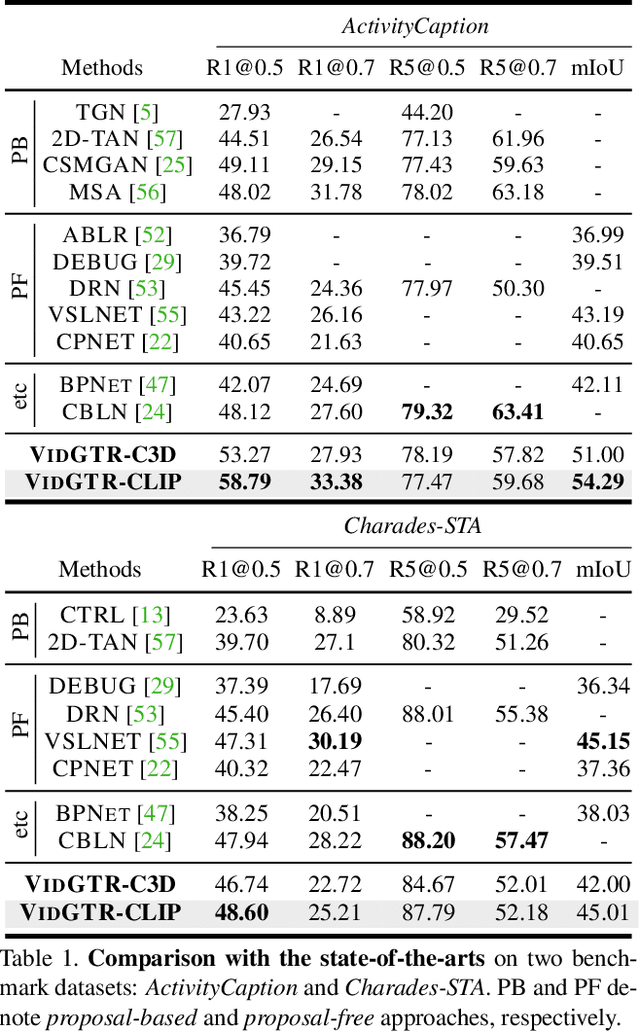
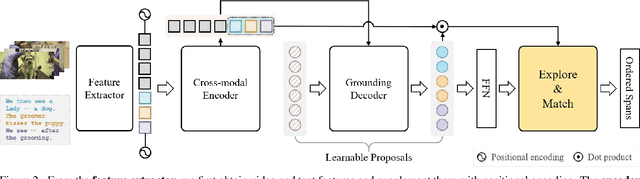
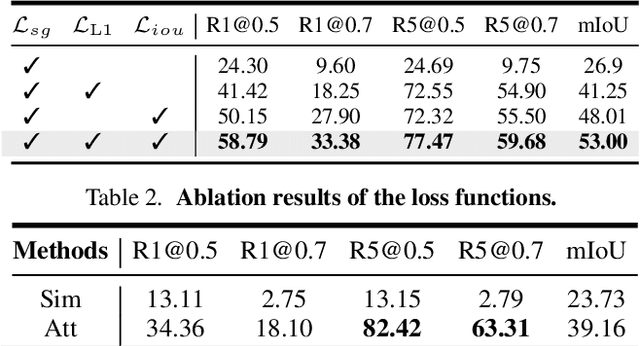
We present a new paradigm named explore-and-match for video grounding, which aims to seamlessly unify two streams of video grounding methods: proposal-based and proposal-free. To achieve this goal, we formulate video grounding as a set prediction problem and design an end-to-end trainable Video Grounding Transformer (VidGTR) that can utilize the architectural strengths of rich contextualization and parallel decoding for set prediction. The overall training is balanced by two key losses that play different roles, namely span localization loss and set guidance loss. These two losses force each proposal to regress the target timespan and identify the target query. Throughout the training, VidGTR first explores the search space to diversify the initial proposals and then matches the proposals to the corresponding targets to fit them in a fine-grained manner. The explore-and-match scheme successfully combines the strengths of two complementary methods, without encoding prior knowledge into the pipeline. As a result, VidGTR sets new state-of-the-art results on two video grounding benchmarks with double the inference speed.