 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Contrastive Learning on Blended Images for Long-tailed Recognition
Nov 22, 2022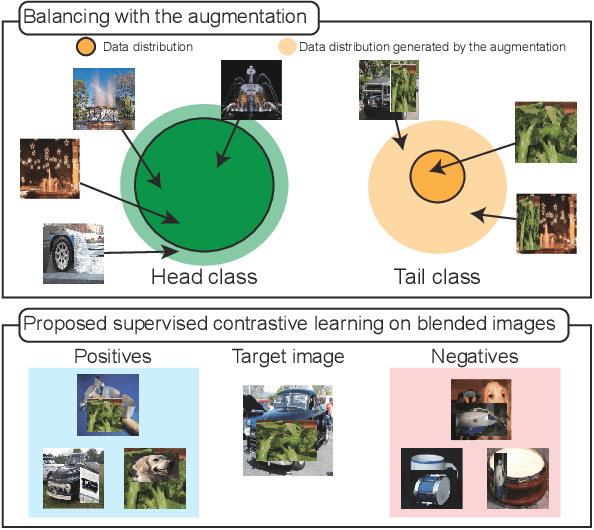
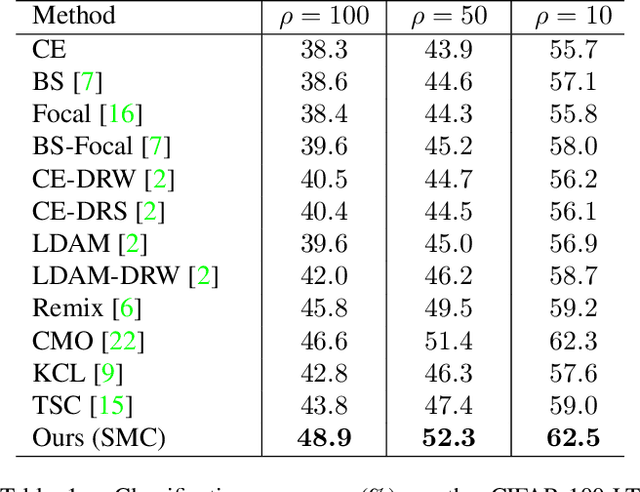

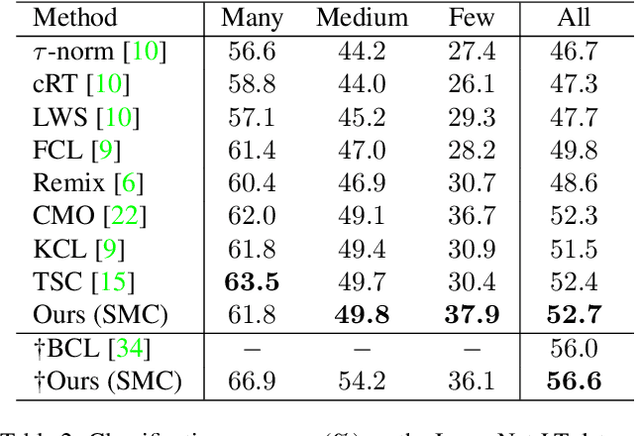
Real-world data often have a long-tailed distribution, where the number of samples per class is not equal over training classes. The imbalanced data form a biased feature space, which deteriorates the performance of the recognition model. In this paper, we propose a novel long-tailed recognition method to balance the latent feature space. First, we introduce a MixUp-based data augmentation technique to reduce the bias of the long-tailed data. Furthermore, we propose a new supervised contrastive learning method, named Supervised contrastive learning on Mixed Classes (SMC), for blended images. SMC creates a set of positives based on the class labels of the original images. The combination ratio of positives weights the positives in the training loss. SMC with the class-mixture-based loss explores more diverse data space, enhancing the generalization capability of the model. Extensive experiments on various benchmarks show the effectiveness of our one-stage training method.
MAC-DO: Charge Based Multi-Bit Analog In-Memory Accelerator Compatible with DRAM Using Output Stationary Mapping
Jul 16, 2022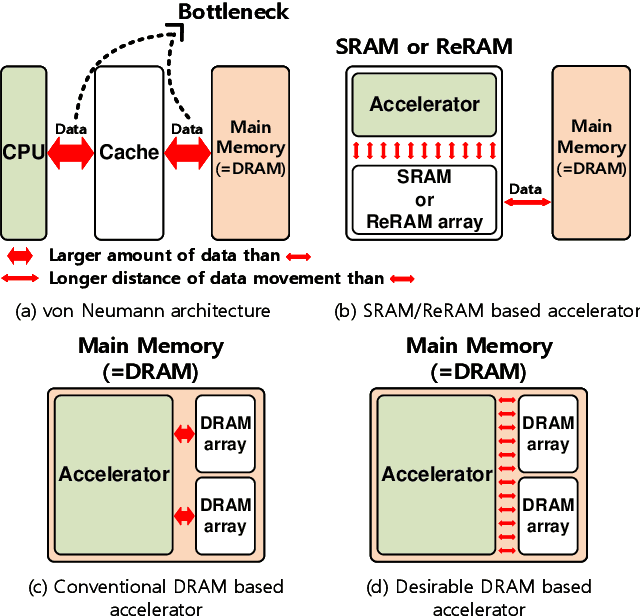


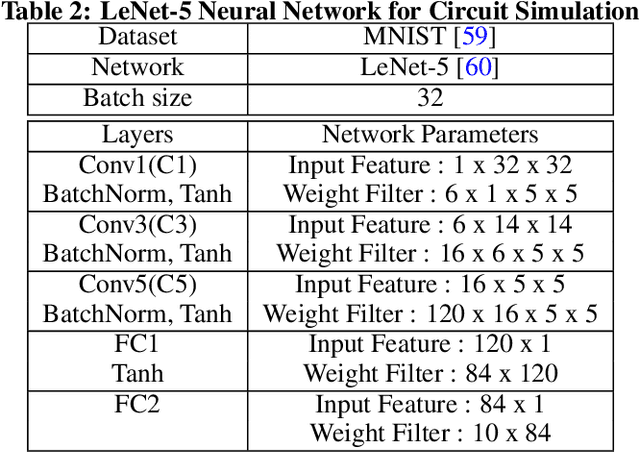
Deep neural networks (DNN) have been proved for its effectiveness in various areas such as classification problems, image processing, video segmentation, and speech recognition. The accelerator-in-memory (AiM) architectures are a promising solution to efficiently accelerate DNNs as they can avoid the memory bottleneck of the traditional von Neumann architecture. As the main memory is usually DRAM in many systems, a highly parallel multiply-accumulate (MAC) array within the DRAM can maximize the benefit of AiM by reducing both the distance and amount of data movement between the processor and the main memory. This paper presents an analog MAC array based AiM architecture named MAC-DO. In contrast with previous in-DRAM accelerators, MAC-DO makes an entire DRAM array participate in MAC computations simultaneously without idle cells, leading to higher throughput and energy efficiency. This improvement is made possible by exploiting a new analog computation method based on charge steering. In addition, MAC-DO innately supports multi-bit MACs with good linearity. MAC-DO is still compatible with current 1T1C DRAM technology without any modifications of a DRAM cell and array. A MAC-DO array can accelerate matrix multiplications based on output stationary mapping and thus supports most of the computations performed in DNNs. Our evaluation using transistor-level simulation shows that a test MAC-DO array with 16 x 16 MAC-DO cells achieves 188.7 TOPS/W, and shows 97.07% Top-1 accuracy for MNIST dataset without retraining.
Explore and Match: End-to-End Video Grounding with Transformer
Jan 25, 2022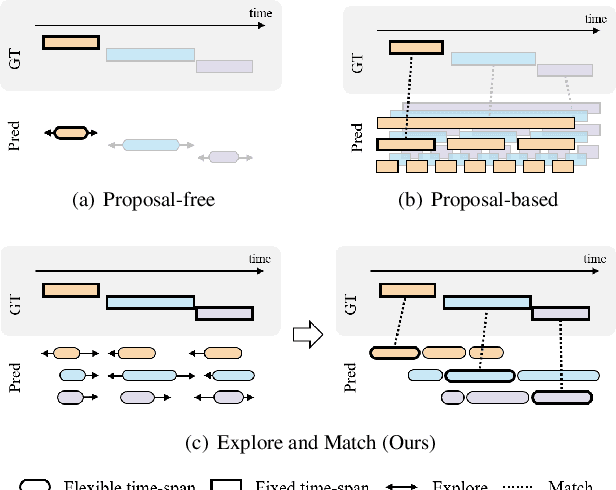
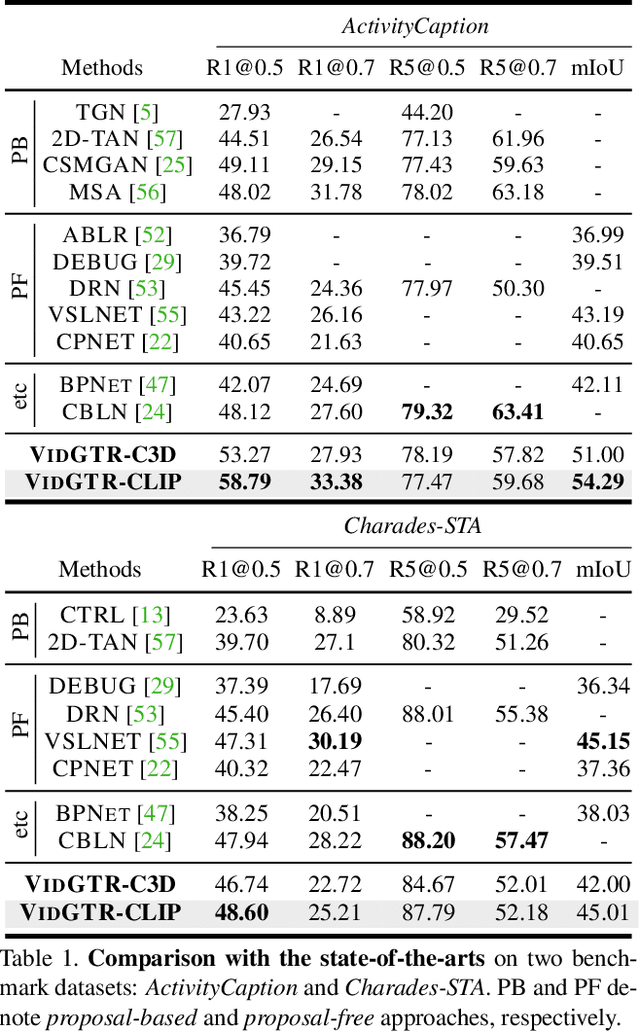
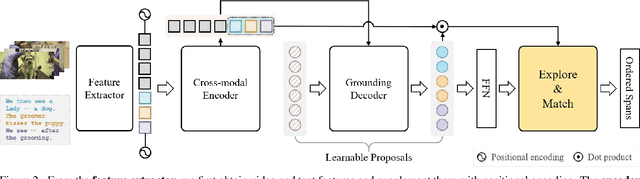
We present a new paradigm named explore-and-match for video grounding, which aims to seamlessly unify two streams of video grounding methods: proposal-based and proposal-free. To achieve this goal, we formulate video grounding as a set prediction problem and design an end-to-end trainable Video Grounding Transformer (VidGTR) that can utilize the architectural strengths of rich contextualization and parallel decoding for set prediction. The overall training is balanced by two key losses that play different roles, namely span localization loss and set guidance loss. These two losses force each proposal to regress the target timespan and identify the target query. Throughout the training, VidGTR first explores the search space to diversify the initial proposals and then matches the proposals to the corresponding targets to fit them in a fine-grained manner. The explore-and-match scheme successfully combines the strengths of two complementary methods, without encoding prior knowledge into the pipeline. As a result, VidGTR sets new state-of-the-art results on two video grounding benchmarks with double the inference speed.
Improving Few-shot Learning with Weakly-supervised Object Localization
May 25, 2021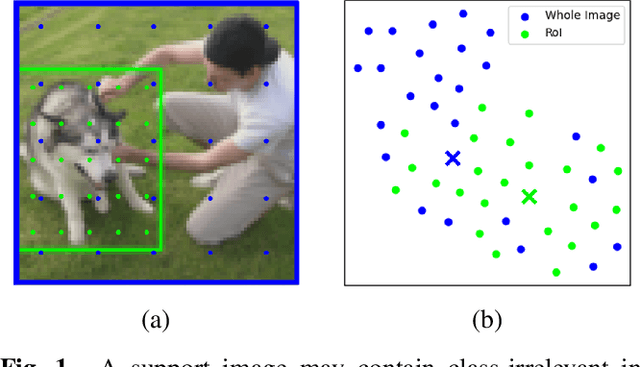
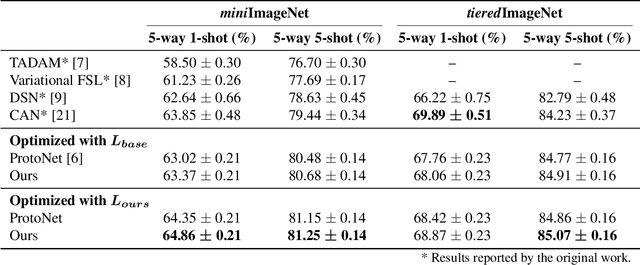
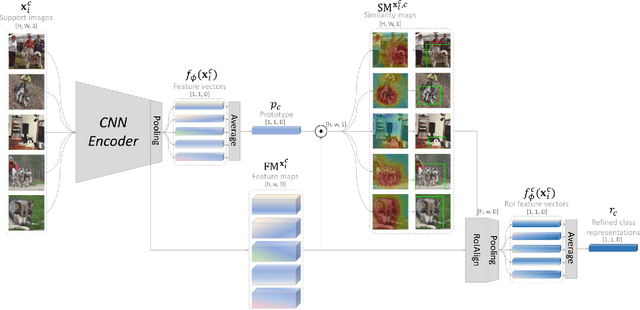

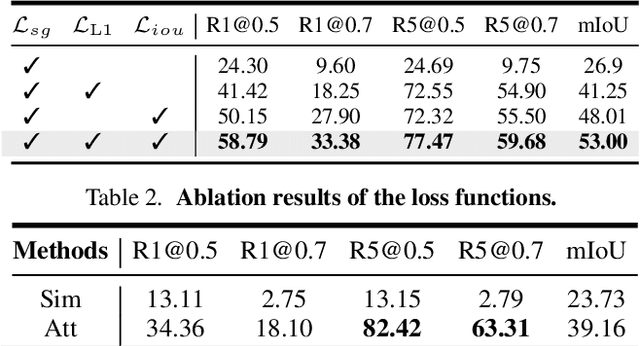
Few-shot learning often involves metric learning-based classifiers, which predict the image label by comparing the distance between the extracted feature vector and class representations. However, applying global pooling in the backend of the feature extractor may not produce an embedding that correctly focuses on the class object. In this work, we propose a novel framework that generates class representations by extracting features from class-relevant regions of the images. Given only a few exemplary images with image-level labels, our framework first localizes the class objects by spatially decomposing the similarity between the images and their class prototypes. Then, enhanced class representations are achieved from the localization results. We also propose a loss function to enhance distinctions of the refined features. Our method outperforms the baseline few-shot model in miniImageNet and tieredImageNet benchmarks.
Few-shot Open-set Recognition by Transformation Consistency
Mar 02, 2021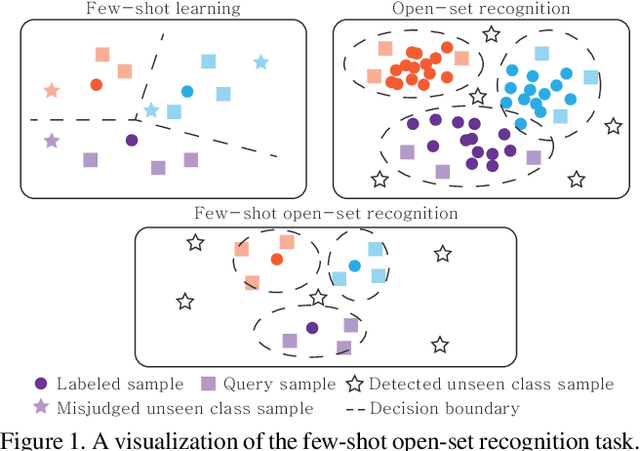
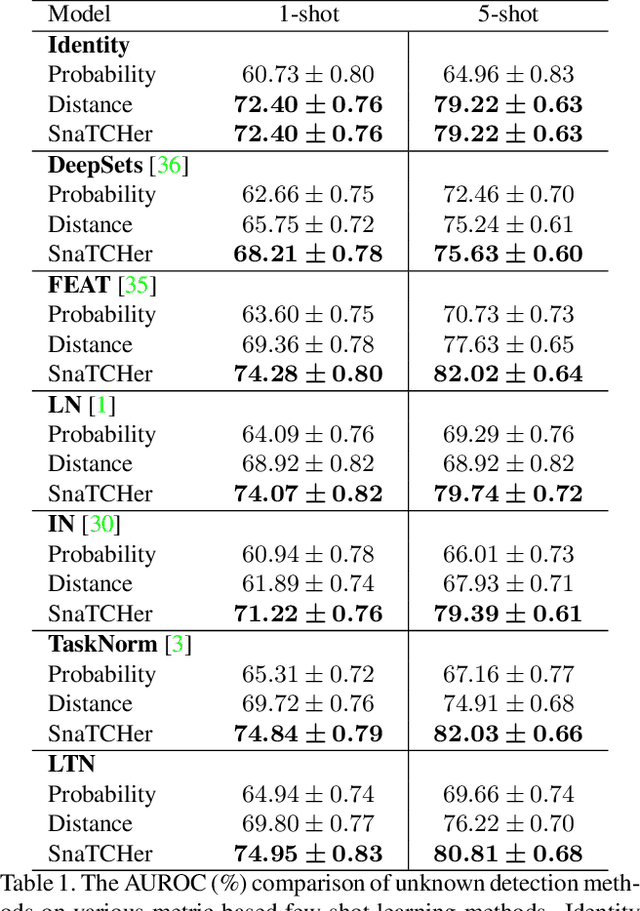
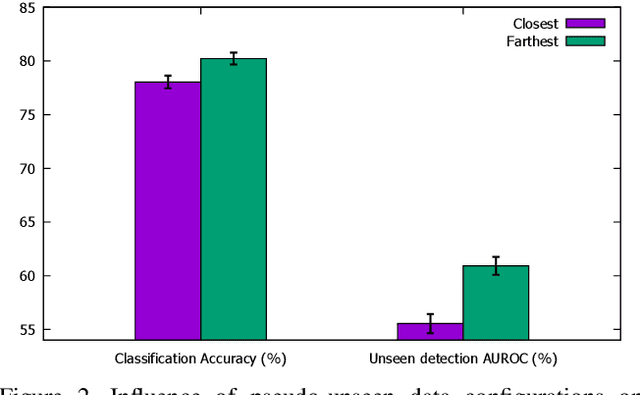
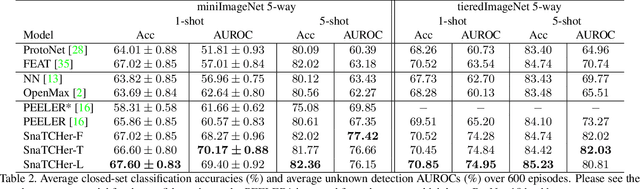
In this paper, we attack a few-shot open-set recognition (FSOSR) problem, which is a combination of few-shot learning (FSL) and open-set recognition (OSR). It aims to quickly adapt a model to a given small set of labeled samples while rejecting unseen class samples. Since OSR requires rich data and FSL considers closed-set classification, existing OSR and FSL methods show poor performances in solving FSOSR problems. The previous FSOSR method follows the pseudo-unseen class sample-based methods, which collect pseudo-unseen samples from the other dataset or synthesize samples to model unseen class representations. However, this approach is heavily dependent on the composition of the pseudo samples. In this paper, we propose a novel unknown class sample detector, named SnaTCHer, that does not require pseudo-unseen samples. Based on the transformation consistency, our method measures the difference between the transformed prototypes and a modified prototype set. The modified set is composed by replacing a query feature and its predicted class prototype. SnaTCHer rejects samples with large differences to the transformed prototypes. Our method alters the unseen class distribution estimation problem to a relative feature transformation problem, independent of pseudo-unseen class samples. We investigate our SnaTCHer with various prototype transformation methods and observe that our method consistently improves unseen class sample detection performance without closed-set classification reduction.
Meta Batch-Instance Normalization for Generalizable Person Re-Identification
Nov 30, 2020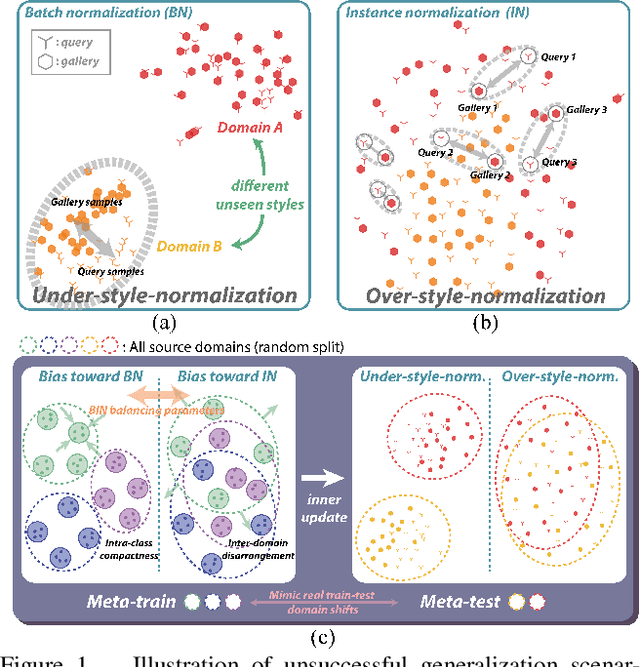
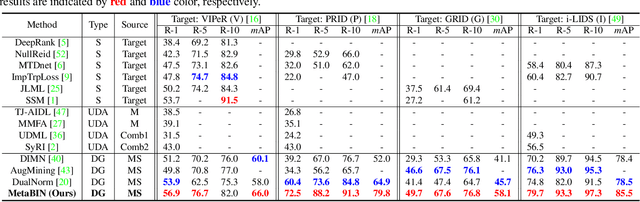
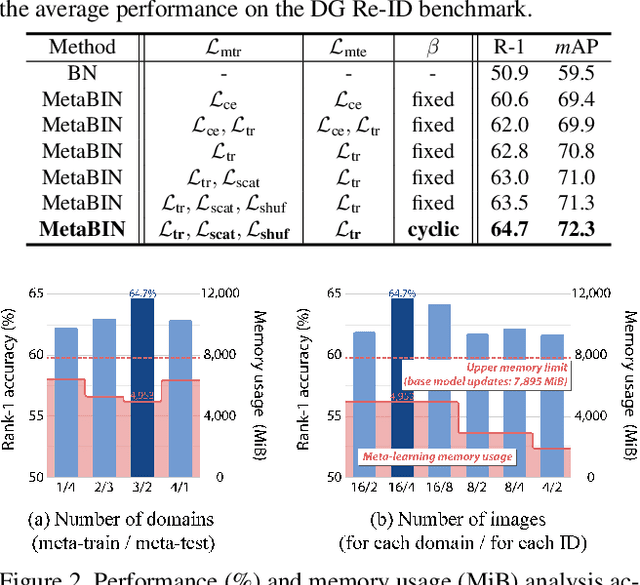
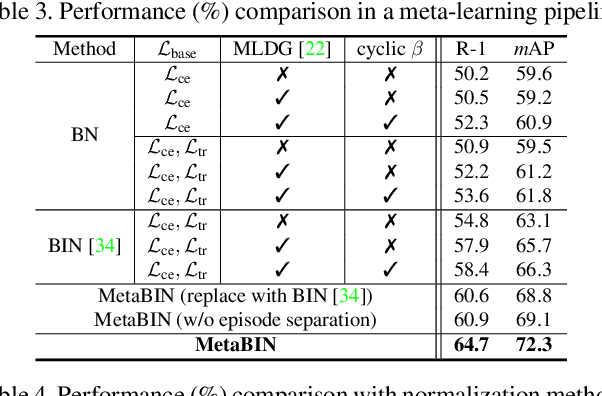
Although supervised person re-identification (Re-ID) methods have shown impressive performance, they suffer from a poor generalization capability on unseen domains. Therefore, generalizable Re-ID has recently attracted growing attention. Many existing methods have employed an instance normalization technique to reduce style variations, but the loss of discriminative information could not be avoided. In this paper, we propose a novel generalizable Re-ID framework, named Meta Batch-Instance Normalization (MetaBIN). Our main idea is to generalize normalization layers by simulating unsuccessful generalization scenarios beforehand in the meta-learning pipeline. To this end, we combine learnable batch-instance normalization layers with meta-learning and investigate the challenging cases caused by both batch and instance normalization layers. Moreover, we diversify the virtual simulations via our meta-train loss accompanied by a cyclic inner-updating manner to boost generalization capability. After all, the MetaBIN framework prevents our model from overfitting to the given source styles and improves the generalization capability to unseen domains without additional data augmentation or complicated network design. Extensive experimental results show that our model outperforms the state-of-the-art methods on the large-scale domain generalization Re-ID benchmark.
Pseudo-Labeling Curriculum for Unsupervised Domain Adaptation
Aug 01, 2019
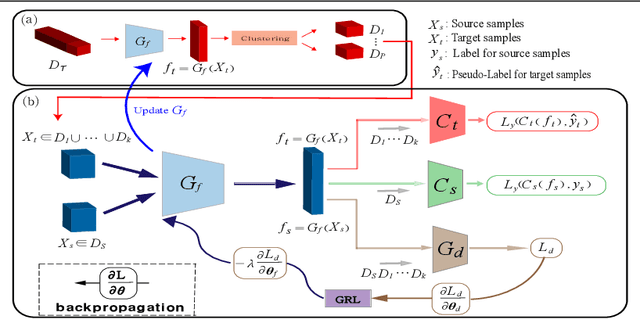

To learn target discriminative representations, using pseudo-labels is a simple yet effective approach for unsupervised domain adaptation. However, the existence of false pseudo-labels, which may have a detrimental influence on learning target representations, remains a major challenge. To overcome this issue, we propose a pseudo-labeling curriculum based on a density-based clustering algorithm. Since samples with high density values are more likely to have correct pseudo-labels, we leverage these subsets to train our target network at the early stage, and utilize data subsets with low density values at the later stage. We can progressively improve the capability of our network to generate pseudo-labels, and thus these target samples with pseudo-labels are effective for training our model. Moreover, we present a clustering constraint to enhance the discriminative power of the learned target features. Our approach achieves state-of-the-art performance on three benchmarks: Office-31, imageCLEF-DA, and Office-Home.
Diversify and Match: A Domain Adaptive Representation Learning Paradigm for Object Detection
May 14, 2019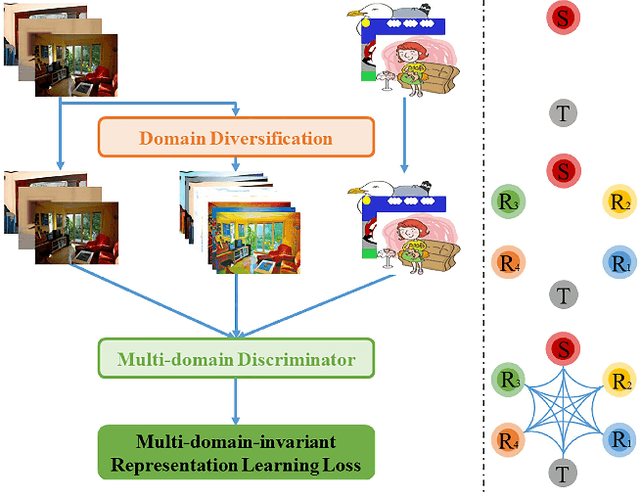



We introduce a novel unsupervised domain adaptation approach for object detection. We aim to alleviate the imperfect translation problem of pixel-level adaptations, and the source-biased discriminativity problem of feature-level adaptations simultaneously. Our approach is composed of two stages, i.e., Domain Diversification (DD) and Multi-domain-invariant Representation Learning (MRL). At the DD stage, we diversify the distribution of the labeled data by generating various distinctive shifted domains from the source domain. At the MRL stage, we apply adversarial learning with a multi-domain discriminator to encourage feature to be indistinguishable among the domains. DD addresses the source-biased discriminativity, while MRL mitigates the imperfect image translation. We construct a structured domain adaptation framework for our learning paradigm and introduce a practical way of DD for implementation. Our method outperforms the state-of-the-art methods by a large margin of 3%~11% in terms of mean average precision (mAP) on various datasets.
Large-Scale 3D Shape Reconstruction and Segmentation from ShapeNet Core55
Oct 27, 2017
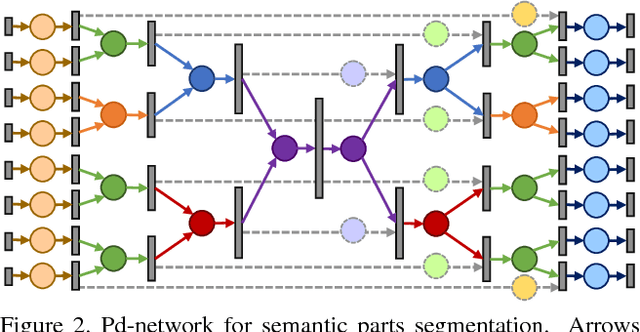
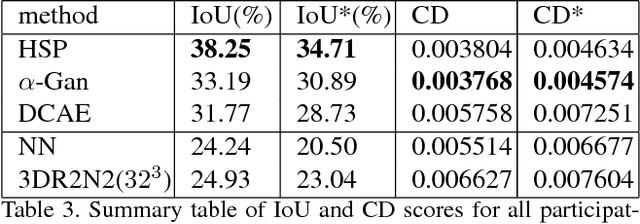
We introduce a large-scale 3D shape understanding benchmark using data and annotation from ShapeNet 3D object database. The benchmark consists of two tasks: part-level segmentation of 3D shapes and 3D reconstruction from single view images. Ten teams have participated in the challenge and the best performing teams have outperformed state-of-the-art approaches on both tasks. A few novel deep learning architectures have been proposed on various 3D representations on both tasks. We report the techniques used by each team and the corresponding performances. In addition, we summarize the major discoveries from the reported results and possible trends for the future work in the field.