 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-training quantization of vision encoders needs prefixing registers
Oct 06, 2025Transformer-based vision encoders -- such as CLIP -- are central to multimodal intelligence, powering applications from autonomous web agents to robotic control. Since these applications often demand real-time processing of massive visual data, reducing the inference cost of vision encoders is critical. Post-training quantization offers a practical path, but remains challenging even at 8-bit precision due to massive-scale activations (i.e., outliers). In this work, we propose $\textit{RegCache}$, a training-free algorithm to mitigate outliers in vision encoders, enabling quantization with significantly smaller accuracy drops. The proposed RegCache introduces outlier-prone yet semantically meaningless prefix tokens to the target vision encoder, which prevents other tokens from having outliers. Notably, we observe that outliers in vision encoders behave differently from those in language models, motivating two technical innovations: middle-layer prefixing and token deletion. Experiments show that our method consistently improves the accuracy of quantized models across both text-supervised and self-supervised vision encoders.
MINSU (Mobile Inventory And Scanning Unit):Computer Vision and AI
Apr 14, 2022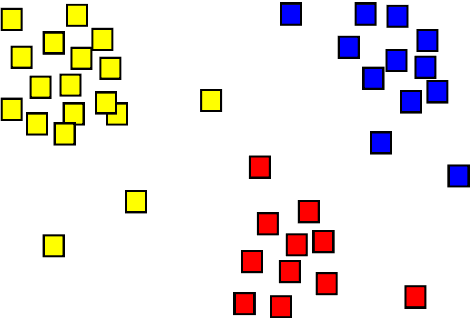
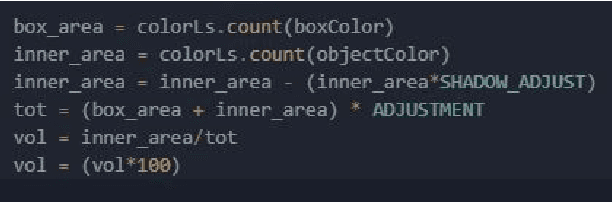


The MINSU(Mobile Inventory and Scanning Unit) algorithm uses the computational vision analysis method to record the residual quantity/fullness of the cabinet. To do so, it goes through a five-step method: object detection, foreground subtraction, K-means clustering, percentage estimation, and counting. The input image goes through the object detection method to analyze the specific position of the cabinets in terms of coordinates. After doing so, it goes through the foreground subtraction method to make the image more focus-able to the cabinet itself by removing the background (some manual work may have to be done such as selecting the parts that were not grab cut by the algorithm). In the K-means clustering method, the multi-colored image turns into a 3 colored monotonous image for quicker and more accurate analysis. At last, the image goes through percentage estimation and counting. In these two methods, the proportion that the material inside the cabinet is found in percentage which then is used to approximate the number of materials inside. Had this project been successful, the residual quantity management could solve the problem addressed earlier in the introduction.
Residual Quantity in Percentage of Factory Machines Using ComputerVision and Mathematical Methods
Nov 09, 2021
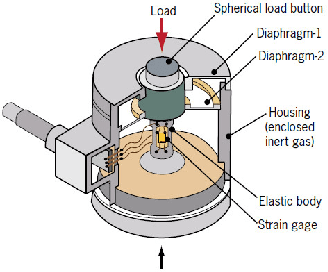

Computer vision has been thriving since AI development was gaining thrust. Using deep learning techniques has been the most popular way which computer scientists thought the solution of. However, deep learning techniques tend to show lower performance than manual processing. Using deep learning is not always the answer to a problem related to computer vision.
CNN-based Semantic Segmentation using Level Set Loss
Oct 02, 2019

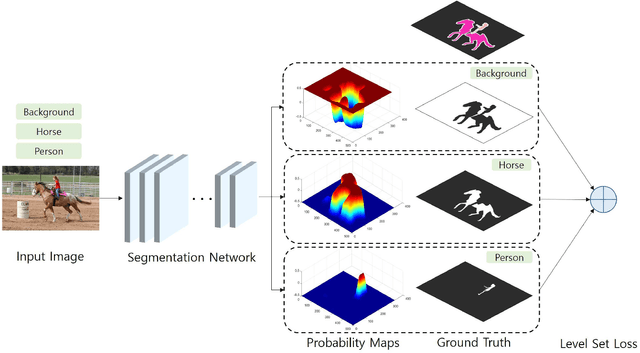
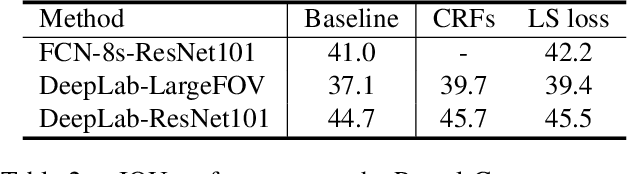
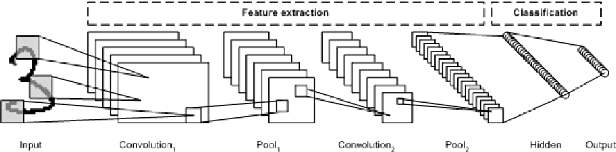
Thesedays, Convolutional Neural Networks are widely used in semantic segmentation. However, since CNN-based segmentation networks produce low-resolution outputs with rich semantic information, it is inevitable that spatial details (e.g., small bjects and fine boundary information) of segmentation results will be lost. To address this problem, motivated by a variational approach to image segmentation (i.e., level set theory), we propose a novel loss function called the level set loss which is designed to refine spatial details of segmentation results. To deal with multiple classes in an image, we first decompose the ground truth into binary images. Note that each binary image consists of background and regions belonging to a class. Then we convert level set functions into class probability maps and calculate the energy for each class. The network is trained to minimize the weighted sum of the level set loss and the cross-entropy loss. The proposed level set loss improves the spatial details of segmentation results in a time and memory efficient way. Furthermore, our experimental results show that the proposed loss function achieves better performance than previous approaches.
Self-Training and Adversarial Background Regularization for Unsupervised Domain Adaptive One-Stage Object Detection
Sep 02, 2019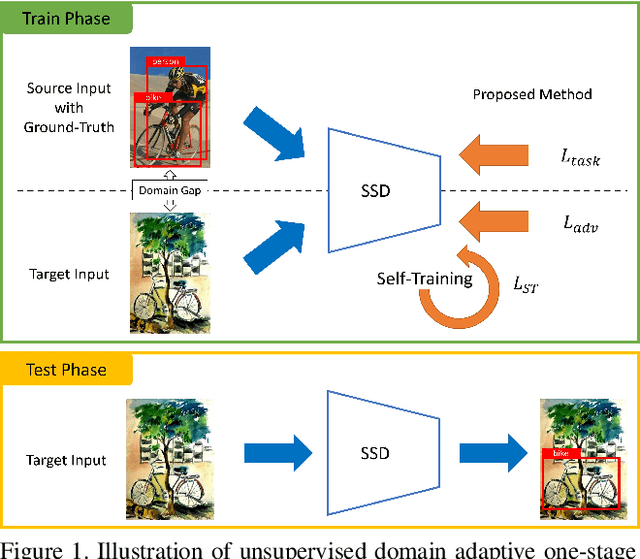

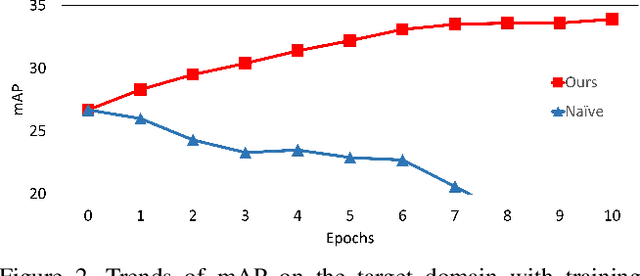
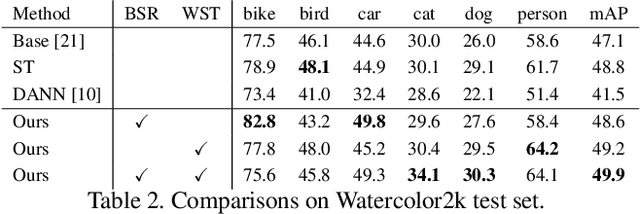
Deep learning-based object detectors have shown remarkable improvements. However, supervised learning-based methods perform poorly when the train data and the test data have different distributions. To address the issue, domain adaptation transfers knowledge from the label-sufficient domain (source domain) to the label-scarce domain (target domain). Self-training is one of the powerful ways to achieve domain adaptation since it helps class-wise domain adaptation. Unfortunately, a naive approach that utilizes pseudo-labels as ground-truth degenerates the performance due to incorrect pseudo-labels. In this paper, we introduce a weak self-training (WST) method and adversarial background score regularization (BSR) for domain adaptive one-stage object detection. WST diminishes the adverse effects of inaccurate pseudo-labels to stabilize the learning procedure. BSR helps the network extract discriminative features for target backgrounds to reduce the domain shift. Two components are complementary to each other as BSR enhances discrimination between foregrounds and backgrounds, whereas WST strengthen class-wise discrimination. Experimental results show that our approach effectively improves the performance of the one-stage object detection in unsupervised domain adaptation setting.
Diversify and Match: A Domain Adaptive Representation Learning Paradigm for Object Detection
May 14, 2019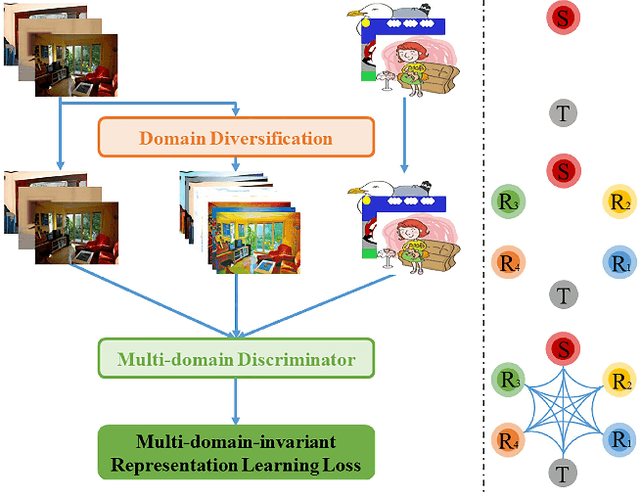



We introduce a novel unsupervised domain adaptation approach for object detection. We aim to alleviate the imperfect translation problem of pixel-level adaptations, and the source-biased discriminativity problem of feature-level adaptations simultaneously. Our approach is composed of two stages, i.e., Domain Diversification (DD) and Multi-domain-invariant Representation Learning (MRL). At the DD stage, we diversify the distribution of the labeled data by generating various distinctive shifted domains from the source domain. At the MRL stage, we apply adversarial learning with a multi-domain discriminator to encourage feature to be indistinguishable among the domains. DD addresses the source-biased discriminativity, while MRL mitigates the imperfect image translation. We construct a structured domain adaptation framework for our learning paradigm and introduce a practical way of DD for implementation. Our method outperforms the state-of-the-art methods by a large margin of 3%~11% in terms of mean average precision (mAP) on various datasets.