 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSERT-RoLL: Robust Multi-Modal Perception for Diverse Driving Conditions with Stereo Event-RGB-Thermal Cameras, 4D Radar, and Dual-LiDAR
Apr 04, 2026In this paper, we present DSERT-RoLL, a driving dataset that incorporates stereo event, RGB, and thermal cameras together with 4D radar and dual LiDAR, collected across diverse weather and illumination conditions. The dataset provides precise 2D and 3D bounding boxes with track IDs and ego vehicle odometry, enabling fair comparisons within and across sensor combinations. It is designed to alleviate data scarcity for novel sensors such as event cameras and 4D radar and to support systematic studies of their behavior. We establish unified 3D and 2D benchmarks that enable direct comparison of characteristics and strengths across sensor families and within each family. We report baselines for representative single modality and multimodal methods and provide protocols that encourage research on different fusion strategies and sensor combinations. In addition, we propose a fusion framework that integrates sensor specific cues into a unified feature space and improves 3D detection robustness under varied weather and lighting.
Event6D: Event-based Novel Object 6D Pose Tracking
Mar 30, 2026Event cameras provide microsecond latency, making them suitable for 6D object pose tracking in fast, dynamic scenes where conventional RGB and depth pipelines suffer from motion blur and large pixel displacements. We introduce EventTrack6D, an event-depth tracking framework that generalizes to novel objects without object-specific training by reconstructing both intensity and depth at arbitrary timestamps between depth frames. Conditioned on the most recent depth measurement, our dual reconstruction recovers dense photometric and geometric cues from sparse event streams. Our EventTrack6D operates at over 120 FPS and maintains temporal consistency under rapid motion. To support training and evaluation, we introduce a comprehensive benchmark suite: a large-scale synthetic dataset for training and two complementary evaluation sets, including real and simulated event datasets. Trained exclusively on synthetic data, EventTrack6D generalizes effectively to real-world scenarios without fine-tuning, maintaining accurate tracking across diverse objects and motion patterns. Our method and datasets validate the effectiveness of event cameras for event-based 6D pose tracking of novel objects. Code and datasets are publicly available at https://chohoonhee.github.io/Event6D.
From Sharp to Blur: Unsupervised Domain Adaptation for 2D Human Pose Estimation Under Extreme Motion Blur Using Event Cameras
Jul 30, 2025Human pose estimation is critical for applications such as rehabilitation, sports analytics, and AR/VR systems. However, rapid motion and low-light conditions often introduce motion blur, significantly degrading pose estimation due to the domain gap between sharp and blurred images. Most datasets assume stable conditions, making models trained on sharp images struggle in blurred environments. To address this, we introduce a novel domain adaptation approach that leverages event cameras, which capture high temporal resolution motion data and are inherently robust to motion blur. Using event-based augmentation, we generate motion-aware blurred images, effectively bridging the domain gap between sharp and blurred domains without requiring paired annotations. Additionally, we develop a student-teacher framework that iteratively refines pseudo-labels, leveraging mutual uncertainty masking to eliminate incorrect labels and enable more effective learning. Experimental results demonstrate that our approach outperforms conventional domain-adaptive human pose estimation methods, achieving robust pose estimation under motion blur without requiring annotations in the target domain. Our findings highlight the potential of event cameras as a scalable and effective solution for domain adaptation in real-world motion blur environments. Our project codes are available at https://github.com/kmax2001/EvSharp2Blur.
Ev-3DOD: Pushing the Temporal Boundaries of 3D Object Detection with Event Cameras
Feb 26, 2025Detecting 3D objects in point clouds plays a crucial role in autonomous driving systems. Recently, advanced multi-modal methods incorporating camera information have achieved notable performance. For a safe and effective autonomous driving system, algorithms that excel not only in accuracy but also in speed and low latency are essential. However, existing algorithms fail to meet these requirements due to the latency and bandwidth limitations of fixed frame rate sensors, e.g., LiDAR and camera. To address this limitation, we introduce asynchronous event cameras into 3D object detection for the first time. We leverage their high temporal resolution and low bandwidth to enable high-speed 3D object detection. Our method enables detection even during inter-frame intervals when synchronized data is unavailable, by retrieving previous 3D information through the event camera. Furthermore, we introduce the first event-based 3D object detection dataset, DSEC-3DOD, which includes ground-truth 3D bounding boxes at 100 FPS, establishing the first benchmark for event-based 3D detectors. The code and dataset are available at https://github.com/mickeykang16/Ev3DOD.
Property Estimation in Geotechnical Databases Using Labeled Random Finite Sets
Oct 30, 2024



The sufficiency of accurate data is a core element in data-centric geotechnics. However, geotechnical datasets are essentially uncertain, whereupon engineers have difficulty with obtaining precise information for making decisions. This challenge is more apparent when the performance of data-driven technologies solely relies on imperfect databases or even when it is sometimes difficult to investigate sites physically. This paper introduces geotechnical property estimation from noisy and incomplete data within the labeled random finite set (LRFS) framework. We leverage the ability of the generalized labeled multi-Bernoulli (GLMB) filter, a fundamental solution for multi-object estimation, to deal with measurement uncertainties from a Bayesian perspective. In particular, this work focuses on the similarity between LRFSs and big indirect data (BID) in geotechnics as those characteristics resemble each other, which enables GLMB filtering to be exploited potentially for data-centric geotechnical engineering. Experiments for numerical study are conducted to evaluate the proposed method using a public clay database.
Label Space Partition Selection for Multi-Object Tracking Using Two-Layer Partitioning
Oct 23, 2023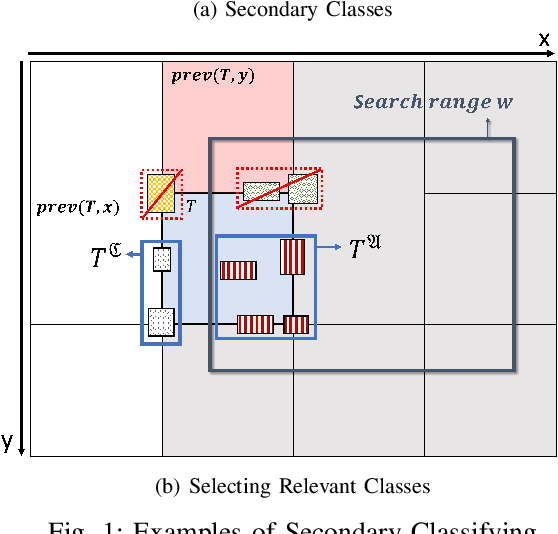
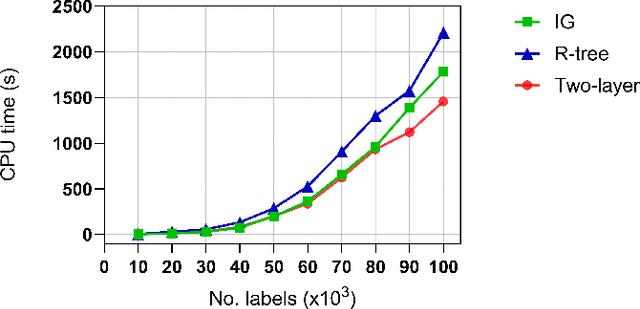
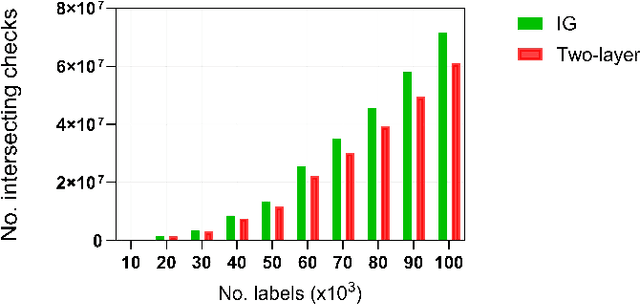
Estimating the trajectories of multi-objects poses a significant challenge due to data association ambiguity, which leads to a substantial increase in computational requirements. To address such problems, a divide-and-conquer manner has been employed with parallel computation. In this strategy, distinguished objects that have unique labels are grouped based on their statistical dependencies, the intersection of predicted measurements. Several geometry approaches have been used for label grouping since finding all intersected label pairs is clearly infeasible for large-scale tracking problems. This paper proposes an efficient implementation of label grouping for label-partitioned generalized labeled multi-Bernoulli filter framework using a secondary partitioning technique. This allows for parallel computation in the label graph indexing step, avoiding generating and eliminating duplicate comparisons. Additionally, we compare the performance of the proposed technique with several efficient spatial searching algorithms. The results demonstrate the superior performance of the proposed approach on large-scale data sets, enabling scalable trajectory estimation.
MINSU (Mobile Inventory And Scanning Unit):Computer Vision and AI
Apr 14, 2022
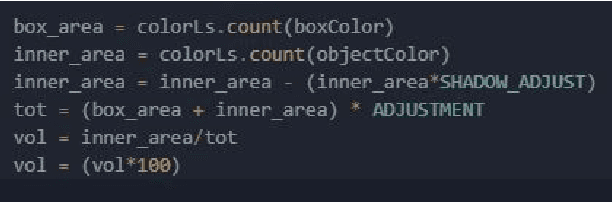


The MINSU(Mobile Inventory and Scanning Unit) algorithm uses the computational vision analysis method to record the residual quantity/fullness of the cabinet. To do so, it goes through a five-step method: object detection, foreground subtraction, K-means clustering, percentage estimation, and counting. The input image goes through the object detection method to analyze the specific position of the cabinets in terms of coordinates. After doing so, it goes through the foreground subtraction method to make the image more focus-able to the cabinet itself by removing the background (some manual work may have to be done such as selecting the parts that were not grab cut by the algorithm). In the K-means clustering method, the multi-colored image turns into a 3 colored monotonous image for quicker and more accurate analysis. At last, the image goes through percentage estimation and counting. In these two methods, the proportion that the material inside the cabinet is found in percentage which then is used to approximate the number of materials inside. Had this project been successful, the residual quantity management could solve the problem addressed earlier in the introduction.
Residual Quantity in Percentage of Factory Machines Using ComputerVision and Mathematical Methods
Nov 09, 2021
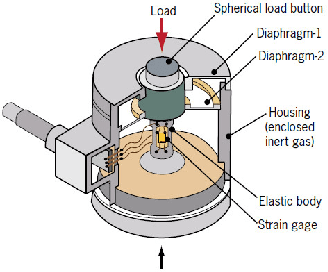
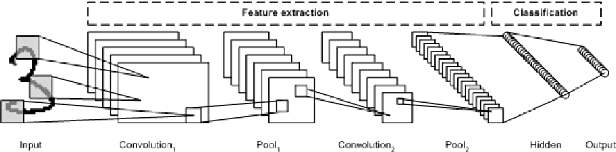

Computer vision has been thriving since AI development was gaining thrust. Using deep learning techniques has been the most popular way which computer scientists thought the solution of. However, deep learning techniques tend to show lower performance than manual processing. Using deep learning is not always the answer to a problem related to computer vision.