 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeN-DriverMotion: Driver motion learning and prediction using an event-based camera and directly trained spiking neural networks
Aug 23, 2024



Driver motion recognition is a principal factor in ensuring the safety of driving systems. This paper presents a novel system for learning and predicting driver motions and an event-based high-resolution (1280x720) dataset, N-DriverMotion, newly collected to train on a neuromorphic vision system. The system comprises an event-based camera that generates the first high-resolution driver motion dataset representing spike inputs and efficient spiking neural networks (SNNs) that are effective in training and predicting the driver's gestures. The event dataset consists of 13 driver motion categories classified by direction (front, side), illumination (bright, moderate, dark), and participant. A novel simplified four-layer convolutional spiking neural network (CSNN) that we proposed was directly trained using the high-resolution dataset without any time-consuming preprocessing. This enables efficient adaptation to on-device SNNs for real-time inference on high-resolution event-based streams. Compared with recent gesture recognition systems adopting neural networks for vision processing, the proposed neuromorphic vision system achieves comparable accuracy, 94.04\%, in recognizing driver motions with the CSNN architecture. Our proposed CSNN and the dataset can be used to develop safer and more efficient driver monitoring systems for autonomous vehicles or edge devices requiring an efficient neural network architecture.
On Initializing Transformers with Pre-trained Embeddings
Jul 17, 2024
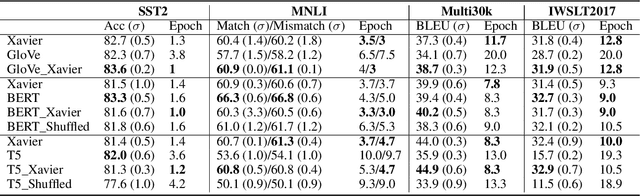
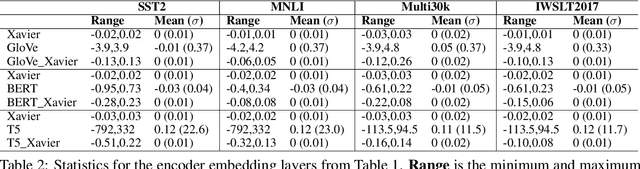
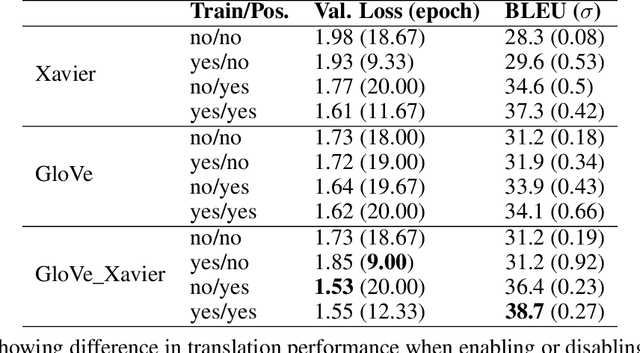
It has become common practice now to use random initialization schemes, rather than the pre-trained embeddings, when training transformer based models from scratch. Indeed, we find that pre-trained word embeddings from GloVe, and some sub-word embeddings extracted from language models such as T5 and mT5 fare much worse compared to random initialization. This is counter-intuitive given the well-known representational and transfer-learning advantages of pre-training. Interestingly, we also find that BERT and mBERT embeddings fare better than random initialization, showing the advantages of pre-trained representations. In this work, we posit two potential factors that contribute to these mixed results: the model sensitivity to parameter distribution and the embedding interactions with position encodings. We observe that pre-trained GloVe, T5, and mT5 embeddings have a wider distribution of values. As argued in the initialization studies, such large value initializations can lead to poor training because of saturated outputs. Further, the larger embedding values can, in effect, absorb the smaller position encoding values when added together, thus losing position information. Standardizing the pre-trained embeddings to a narrow range (e.g. as prescribed by Xavier) leads to substantial gains for Glove, T5, and mT5 embeddings. On the other hand, BERT pre-trained embeddings, while larger, are still relatively closer to Xavier initialization range which may allow it to effectively transfer the pre-trained knowledge.
In Defense of Pure 16-bit Floating-Point Neural Networks
May 18, 2023Reducing the number of bits needed to encode the weights and activations of neural networks is highly desirable as it speeds up their training and inference time while reducing memory consumption. For these reasons, research in this area has attracted significant attention toward developing neural networks that leverage lower-precision computing, such as mixed-precision training. Interestingly, none of the existing approaches has investigated pure 16-bit floating-point settings. In this paper, we shed light on the overlooked efficiency of pure 16-bit floating-point neural networks. As such, we provide a comprehensive theoretical analysis to investigate the factors contributing to the differences observed between 16-bit and 32-bit models. We formalize the concepts of floating-point error and tolerance, enabling us to quantitatively explain the conditions under which a 16-bit model can closely approximate the results of its 32-bit counterpart. This theoretical exploration offers perspective that is distinct from the literature which attributes the success of low-precision neural networks to its regularization effect. This in-depth analysis is supported by an extensive series of experiments. Our findings demonstrate that pure 16-bit floating-point neural networks can achieve similar or even better performance than their mixed-precision and 32-bit counterparts. We believe the results presented in this paper will have significant implications for machine learning practitioners, offering an opportunity to reconsider using pure 16-bit networks in various applications.
The Hidden Power of Pure 16-bit Floating-Point Neural Networks
Jan 30, 2023Lowering the precision of neural networks from the prevalent 32-bit precision has long been considered harmful to performance, despite the gain in space and time. Many works propose various techniques to implement half-precision neural networks, but none study pure 16-bit settings. This paper investigates the unexpected performance gain of pure 16-bit neural networks over the 32-bit networks in classification tasks. We present extensive experimental results that favorably compare various 16-bit neural networks' performance to those of the 32-bit models. In addition, a theoretical analysis of the efficiency of 16-bit models is provided, which is coupled with empirical evidence to back it up. Finally, we discuss situations in which low-precision training is indeed detrimental.
MINSU (Mobile Inventory And Scanning Unit):Computer Vision and AI
Apr 14, 2022
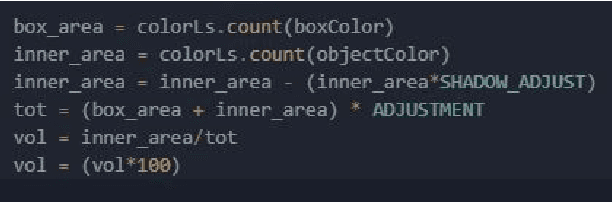


The MINSU(Mobile Inventory and Scanning Unit) algorithm uses the computational vision analysis method to record the residual quantity/fullness of the cabinet. To do so, it goes through a five-step method: object detection, foreground subtraction, K-means clustering, percentage estimation, and counting. The input image goes through the object detection method to analyze the specific position of the cabinets in terms of coordinates. After doing so, it goes through the foreground subtraction method to make the image more focus-able to the cabinet itself by removing the background (some manual work may have to be done such as selecting the parts that were not grab cut by the algorithm). In the K-means clustering method, the multi-colored image turns into a 3 colored monotonous image for quicker and more accurate analysis. At last, the image goes through percentage estimation and counting. In these two methods, the proportion that the material inside the cabinet is found in percentage which then is used to approximate the number of materials inside. Had this project been successful, the residual quantity management could solve the problem addressed earlier in the introduction.
Photo-realistic Image Super-resolution with Fast and Lightweight Cascading Residual Network
Mar 06, 2019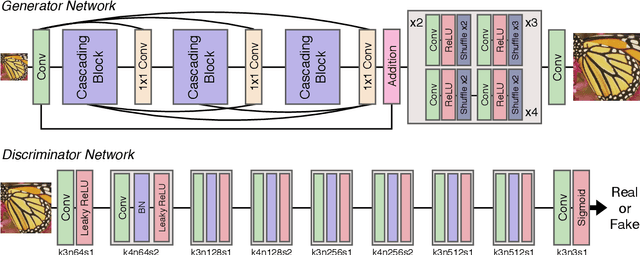
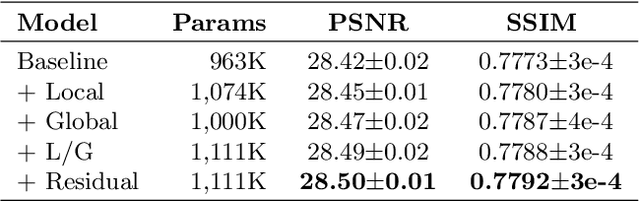
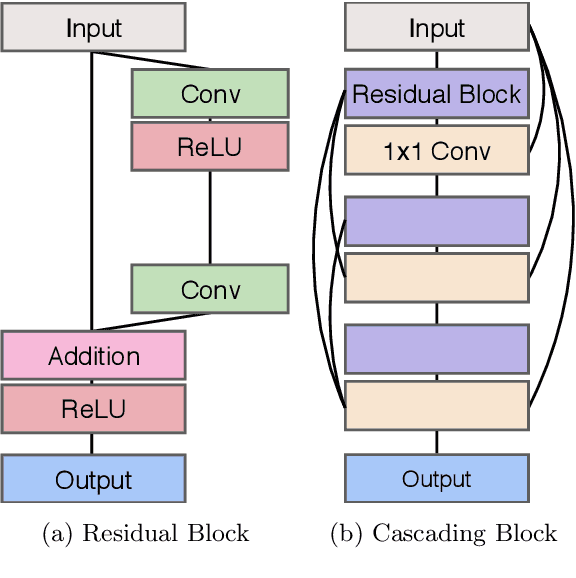

Recent progress in the deep learning-based models has improved single-image super-resolution significantly. However, despite their powerful performance, many models are difficult to apply to the real-world applications because of the heavy computational requirements. To facilitate the use of a deep learning model in such demands, we focus on keeping the model fast and lightweight while maintaining its accuracy. In detail, we design an architecture that implements a cascading mechanism on a residual network to boost the performance with limited resources via multi-level feature fusion. Moreover, we adopt group convolution and weight-tying for our proposed model in order to achieve extreme efficiency. In addition to the traditional super-resolution task, we apply our methods to the photo-realistic super-resolution field using the adversarial learning paradigm and a multi-scale discriminator approach. By doing so, we show that the performances of the proposed models surpass those of the recent methods, which have a complexity similar to ours, for both traditional pixel-based and perception-based tasks.
Fast, Accurate, and Lightweight Super-Resolution with Cascading Residual Network
Oct 04, 2018
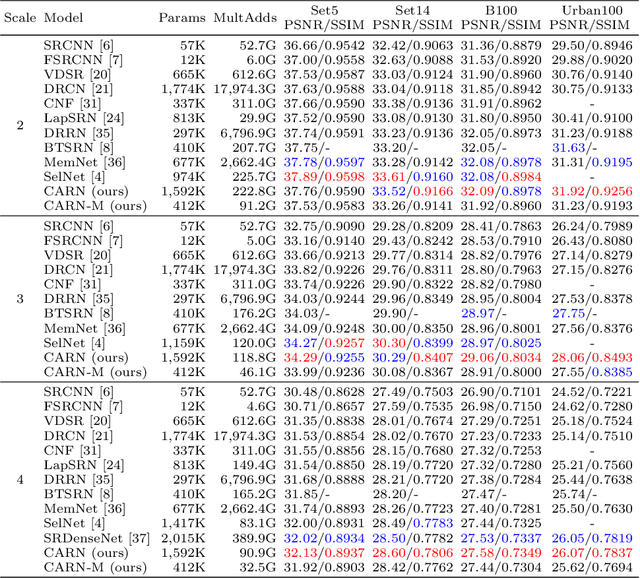
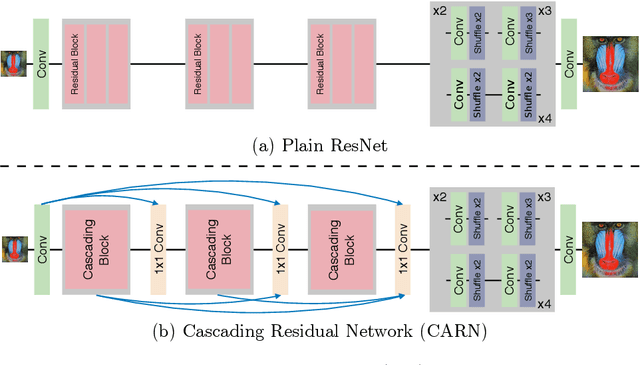

In recent years, deep learning methods have been successfully applied to single-image super-resolution tasks. Despite their great performances, deep learning methods cannot be easily applied to real-world applications due to the requirement of heavy computation. In this paper, we address this issue by proposing an accurate and lightweight deep network for image super-resolution. In detail, we design an architecture that implements a cascading mechanism upon a residual network. We also present variant models of the proposed cascading residual network to further improve efficiency. Our extensive experiments show that even with much fewer parameters and operations, our models achieve performance comparable to that of state-of-the-art methods.
Image Distortion Detection using Convolutional Neural Network
May 28, 2018
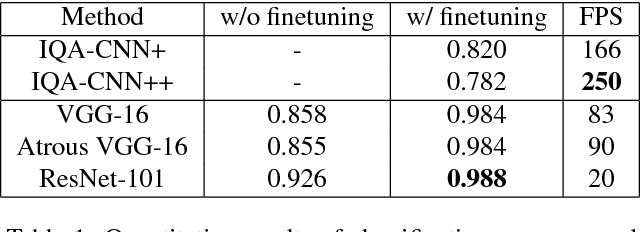

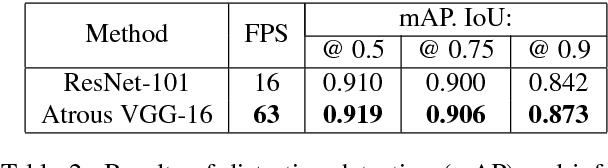
Image distortion classification and detection is an important task in many applications. For example when compressing images, if we know the exact location of the distortion, then it is possible to re-compress images by adjusting the local compression level dynamically. In this paper, we address the problem of detecting the distortion region and classifying the distortion type of a given image. We show that our model significantly outperforms the state-of-the-art distortion classifier, and report accurate detection results for the first time. We expect that such results prove the usefulness of our approach in many potential applications such as image compression or distortion restoration.