 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePensieve Grader: An AI-Powered, Ready-to-Use Platform for Effortless Handwritten STEM Grading
Jul 02, 2025Grading handwritten, open-ended responses remains a major bottleneck in large university STEM courses. We introduce Pensieve (https://www.pensieve.co), an AI-assisted grading platform that leverages large language models (LLMs) to transcribe and evaluate student work, providing instructors with rubric-aligned scores, transcriptions, and confidence ratings. Unlike prior tools that focus narrowly on specific tasks like transcription or rubric generation, Pensieve supports the entire grading pipeline-from scanned student submissions to final feedback-within a human-in-the-loop interface. Pensieve has been deployed in real-world courses at over 20 institutions and has graded more than 300,000 student responses. We present system details and empirical results across four core STEM disciplines: Computer Science, Mathematics, Physics, and Chemistry. Our findings show that Pensieve reduces grading time by an average of 65%, while maintaining a 95.4% agreement rate with instructor-assigned grades for high-confidence predictions.
N-DriverMotion: Driver motion learning and prediction using an event-based camera and directly trained spiking neural networks
Aug 23, 2024



Driver motion recognition is a principal factor in ensuring the safety of driving systems. This paper presents a novel system for learning and predicting driver motions and an event-based high-resolution (1280x720) dataset, N-DriverMotion, newly collected to train on a neuromorphic vision system. The system comprises an event-based camera that generates the first high-resolution driver motion dataset representing spike inputs and efficient spiking neural networks (SNNs) that are effective in training and predicting the driver's gestures. The event dataset consists of 13 driver motion categories classified by direction (front, side), illumination (bright, moderate, dark), and participant. A novel simplified four-layer convolutional spiking neural network (CSNN) that we proposed was directly trained using the high-resolution dataset without any time-consuming preprocessing. This enables efficient adaptation to on-device SNNs for real-time inference on high-resolution event-based streams. Compared with recent gesture recognition systems adopting neural networks for vision processing, the proposed neuromorphic vision system achieves comparable accuracy, 94.04\%, in recognizing driver motions with the CSNN architecture. Our proposed CSNN and the dataset can be used to develop safer and more efficient driver monitoring systems for autonomous vehicles or edge devices requiring an efficient neural network architecture.
Pensieve Discuss: Scalable Small-Group CS Tutoring System with AI
Jul 24, 2024



Small-group tutoring in Computer Science (CS) is effective, but presents the challenge of providing a dedicated tutor for each group and encouraging collaboration among group members at scale. We present Pensieve Discuss, a software platform that integrates synchronous editing for scaffolded programming problems with online human and AI tutors, designed to improve student collaboration and experience during group tutoring sessions. Our semester-long deployment to 800 students in a CS1 course demonstrated consistently high collaboration rates, positive feedback about the AI tutor's helpfulness and correctness, increased satisfaction with the group tutoring experience, and a substantial increase in question volume. The use of our system was preferred over an interface lacking AI tutors and synchronous editing capabilities. Our experiences suggest that small-group tutoring sessions are an important avenue for future research in educational AI.
Evaluating the Knowledge Dependency of Questions
Nov 21, 2022The automatic generation of Multiple Choice Questions (MCQ) has the potential to reduce the time educators spend on student assessment significantly. However, existing evaluation metrics for MCQ generation, such as BLEU, ROUGE, and METEOR, focus on the n-gram based similarity of the generated MCQ to the gold sample in the dataset and disregard their educational value. They fail to evaluate the MCQ's ability to assess the student's knowledge of the corresponding target fact. To tackle this issue, we propose a novel automatic evaluation metric, coined Knowledge Dependent Answerability (KDA), which measures the MCQ's answerability given knowledge of the target fact. Specifically, we first show how to measure KDA based on student responses from a human survey. Then, we propose two automatic evaluation metrics, KDA_disc and KDA_cont, that approximate KDA by leveraging pre-trained language models to imitate students' problem-solving behavior. Through our human studies, we show that KDA_disc and KDA_soft have strong correlations with both (1) KDA and (2) usability in an actual classroom setting, labeled by experts. Furthermore, when combined with n-gram based similarity metrics, KDA_disc and KDA_cont are shown to have a strong predictive power for various expert-labeled MCQ quality measures.
GRAM: Fast Fine-tuning of Pre-trained Language Models for Content-based Collaborative Filtering
Apr 08, 2022
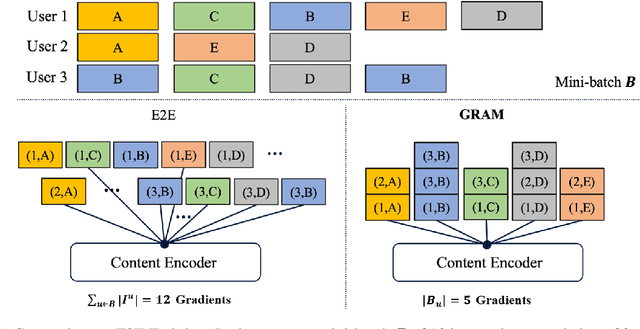
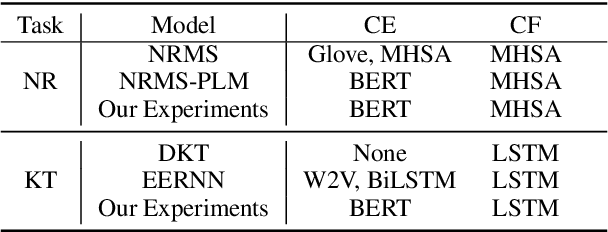
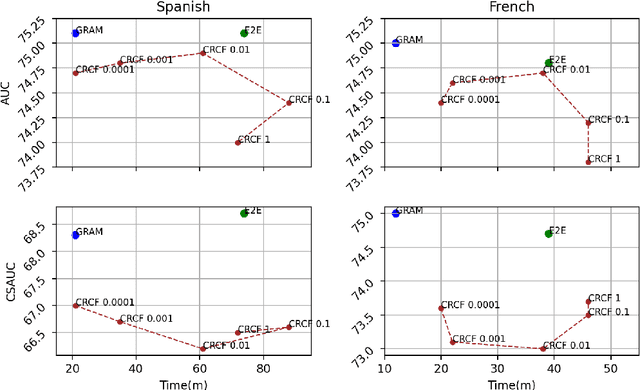
Content-based collaborative filtering (CCF) provides personalized item recommendations based on both users' interaction history and items' content information. Recently, pre-trained language models (PLM) have been used to extract high-quality item encodings for CCF. However, it is resource-intensive to finetune PLM in an end-to-end (E2E) manner in CCF due to its multi-modal nature: optimization involves redundant content encoding for interactions from users. For this, we propose GRAM (GRadient Accumulation for Multi-modality): (1) Single-step GRAM which aggregates gradients for each item while maintaining theoretical equivalence with E2E, and (2) Multi-step GRAM which further accumulates gradients across multiple training steps, with less than 40\% GPU memory footprint of E2E. We empirically confirm that GRAM achieves a remarkable boost in training efficiency based on five datasets from two task domains of Knowledge Tracing and News Recommendation, where single-step and multi-step GRAM achieve 4x and 45x training speedup on average, respectively.