 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverthinking Loops in Agents: A Structural Risk via MCP Tools
Feb 16, 2026Tool-using LLM agents increasingly coordinate real workloads by selecting and chaining third-party tools based on text-visible metadata such as tool names, descriptions, and return messages. We show that this convenience creates a supply-chain attack surface: a malicious MCP tool server can be co-registered alongside normal tools and induce overthinking loops, where individually trivial or plausible tool calls compose into cyclic trajectories that inflate end-to-end tokens and latency without any single step looking abnormal. We formalize this as a structural overthinking attack, distinguishable from token-level verbosity, and implement 14 malicious tools across three servers that trigger repetition, forced refinement, and distraction. Across heterogeneous registries and multiple tool-capable models, the attack causes severe resource amplification (up to $142.4\times$ tokens) and can degrade task outcomes. Finally, we find that decoding-time concision controls do not reliably prevent loop induction, suggesting defenses should reason about tool-call structure rather than tokens alone.
TextME: Bridging Unseen Modalities Through Text Descriptions
Feb 03, 2026Expanding multimodal representations to novel modalities is constrained by reliance on large-scale paired datasets (e.g., text-image, text-audio, text-3D, text-molecule), which are costly and often infeasible in domains requiring expert annotation such as medical imaging and molecular analysis. We introduce TextME, the first text-only modality expansion framework, to the best of our knowledge, projecting diverse modalities into LLM embedding space as a unified anchor. Our approach exploits the geometric structure of pretrained contrastive encoders to enable zero-shot cross-modal transfer using only text descriptions, without paired supervision. We empirically validate that such consistent modality gaps exist across image, video, audio, 3D, X-ray, and molecular domains, demonstrating that text-only training can preserve substantial performance of pretrained encoders. We further show that our framework enables emergent cross-modal retrieval between modality pairs not explicitly aligned during training (e.g., audio-to-image, 3D-to-image). These results establish text-only training as a practical alternative to paired supervision for modality expansion.
Trillion 7B Technical Report
Apr 21, 2025We introduce Trillion-7B, the most token-efficient Korean-centric multilingual LLM available. Our novel Cross-lingual Document Attention (XLDA) mechanism enables highly efficient and effective knowledge transfer from English to target languages like Korean and Japanese. Combined with optimized data mixtures, language-specific filtering, and tailored tokenizer construction, Trillion-7B achieves competitive performance while dedicating only 10\% of its 2T training tokens to multilingual data and requiring just 59.4K H100 GPU hours (\$148K) for full training. Comprehensive evaluations across 27 benchmarks in four languages demonstrate Trillion-7B's robust multilingual performance and exceptional cross-lingual consistency.
Towards Fully-Automated Materials Discovery via Large-Scale Synthesis Dataset and Expert-Level LLM-as-a-Judge
Feb 23, 2025Materials synthesis is vital for innovations such as energy storage, catalysis, electronics, and biomedical devices. Yet, the process relies heavily on empirical, trial-and-error methods guided by expert intuition. Our work aims to support the materials science community by providing a practical, data-driven resource. We have curated a comprehensive dataset of 17K expert-verified synthesis recipes from open-access literature, which forms the basis of our newly developed benchmark, AlchemyBench. AlchemyBench offers an end-to-end framework that supports research in large language models applied to synthesis prediction. It encompasses key tasks, including raw materials and equipment prediction, synthesis procedure generation, and characterization outcome forecasting. We propose an LLM-as-a-Judge framework that leverages large language models for automated evaluation, demonstrating strong statistical agreement with expert assessments. Overall, our contributions offer a supportive foundation for exploring the capabilities of LLMs in predicting and guiding materials synthesis, ultimately paving the way for more efficient experimental design and accelerated innovation in materials science.
Interventional Speech Noise Injection for ASR Generalizable Spoken Language Understanding
Oct 21, 2024Recently, pre-trained language models (PLMs) have been increasingly adopted in spoken language understanding (SLU). However, automatic speech recognition (ASR) systems frequently produce inaccurate transcriptions, leading to noisy inputs for SLU models, which can significantly degrade their performance. To address this, our objective is to train SLU models to withstand ASR errors by exposing them to noises commonly observed in ASR systems, referred to as ASR-plausible noises. Speech noise injection (SNI) methods have pursued this objective by introducing ASR-plausible noises, but we argue that these methods are inherently biased towards specific ASR systems, or ASR-specific noises. In this work, we propose a novel and less biased augmentation method of introducing the noises that are plausible to any ASR system, by cutting off the non-causal effect of noises. Experimental results and analyses demonstrate the effectiveness of our proposed methods in enhancing the robustness and generalizability of SLU models against unseen ASR systems by introducing more diverse and plausible ASR noises in advance.
Efficient and Effective Vocabulary Expansion Towards Multilingual Large Language Models
Feb 22, 2024
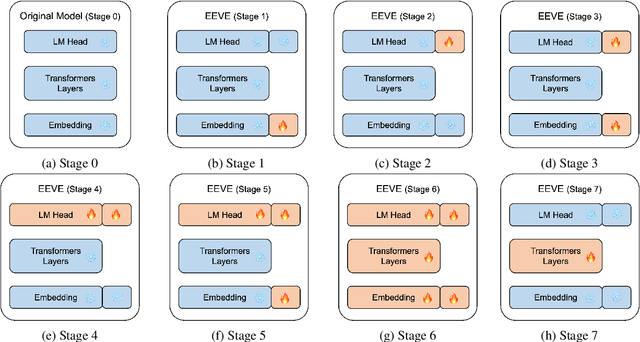
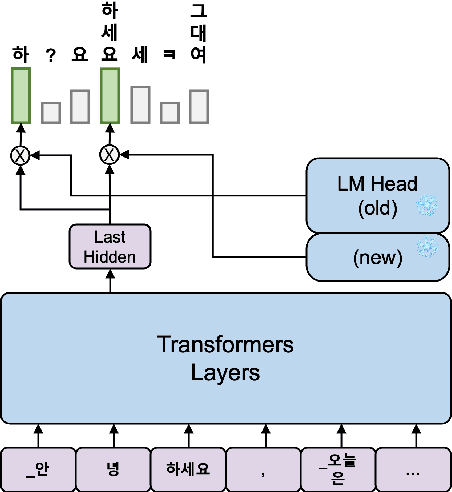
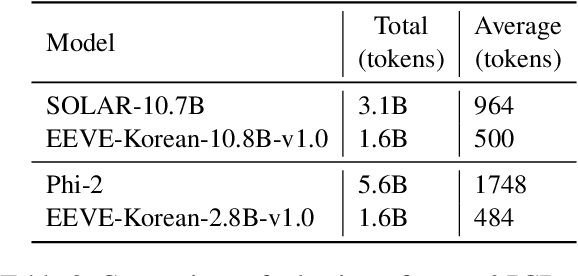
This report introduces \texttt{EEVE-Korean-v1.0}, a Korean adaptation of large language models that exhibit remarkable capabilities across English and Korean text understanding. Building on recent highly capable but English-centric LLMs, such as SOLAR-10.7B and Phi-2, where non-English texts are inefficiently processed with English-centric tokenizers, we present an efficient and effective vocabulary expansion (EEVE) method, which encompasses parameter freezing and subword initialization. In contrast to previous efforts that believe new embeddings require trillions of training tokens, we show that our method can significantly boost non-English proficiency within just 2 billion tokens. Surpassing most instruction-tuned LLMs on the Open Ko-LLM Leaderboard, as of January 2024, our model \texttt{EEVE-Korean-10.8B-v1.0} ranks as the leading Korean pre-trained model in the open-source community, according to Hugging Face's leaderboard. We open-source our models on Huggingface to empower the open research community in various languages.
Addressing Cold Start Problem for End-to-end Automatic Speech Scoring
Jun 25, 2023



Integrating automatic speech scoring/assessment systems has become a critical aspect of second-language speaking education. With self-supervised learning advancements, end-to-end speech scoring approaches have exhibited promising results. However, this study highlights the significant decrease in the performance of speech scoring systems in new question contexts, thereby identifying this as a cold start problem in terms of items. With the finding of cold-start phenomena, this paper seeks to alleviate the problem by following methods: 1) prompt embeddings, 2) question context embeddings using BERT or CLIP models, and 3) choice of the pretrained acoustic model. Experiments are conducted on TOEIC speaking test datasets collected from English-as-a-second-language (ESL) learners rated by professional TOEIC speaking evaluators. The results demonstrate that the proposed framework not only exhibits robustness in a cold-start environment but also outperforms the baselines for known content.
Multi-Architecture Multi-Expert Diffusion Models
Jun 08, 2023



Diffusion models have achieved impressive results in generating diverse and realistic data by employing multi-step denoising processes. However, the need for accommodating significant variations in input noise at each time-step has led to diffusion models requiring a large number of parameters for their denoisers. We have observed that diffusion models effectively act as filters for different frequency ranges at each time-step noise. While some previous works have introduced multi-expert strategies, assigning denoisers to different noise intervals, they overlook the importance of specialized operations for high and low frequencies. For instance, self-attention operations are effective at handling low-frequency components (low-pass filters), while convolutions excel at capturing high-frequency features (high-pass filters). In other words, existing diffusion models employ denoisers with the same architecture, without considering the optimal operations for each time-step noise. To address this limitation, we propose a novel approach called Multi-architecturE Multi-Expert (MEME), which consists of multiple experts with specialized architectures tailored to the operations required at each time-step interval. Through extensive experiments, we demonstrate that MEME outperforms large competitors in terms of both generation performance and computational efficiency.
ScoreCL: Augmentation-Adaptive Contrastive Learning via Score-Matching Function
Jun 07, 2023Self-supervised contrastive learning (CL) has achieved state-of-the-art performance in representation learning by minimizing the distance between positive pairs while maximizing that of negative ones. Recently, it has been verified that the model learns better representation with diversely augmented positive pairs because they enable the model to be more view-invariant. However, only a few studies on CL have considered the difference between augmented views, and have not gone beyond the hand-crafted findings. In this paper, we first observe that the score-matching function can measure how much data has changed from the original through augmentation. With the observed property, every pair in CL can be weighted adaptively by the difference of score values, resulting in boosting the performance of the existing CL method. We show the generality of our method, referred to as ScoreCL, by consistently improving various CL methods, SimCLR, SimSiam, W-MSE, and VICReg, up to 3%p in k-NN evaluation on CIFAR-10, CIFAR-100, and ImageNet-100. Moreover, we have conducted exhaustive experiments and ablations, including results on diverse downstream tasks, comparison with possible baselines, and improvement when used with other proposed augmentation methods. We hope our exploration will inspire more research in exploiting the score matching for CL.
Addressing Negative Transfer in Diffusion Models
Jun 01, 2023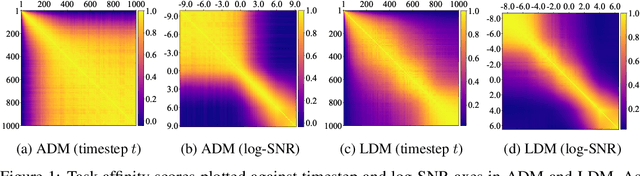
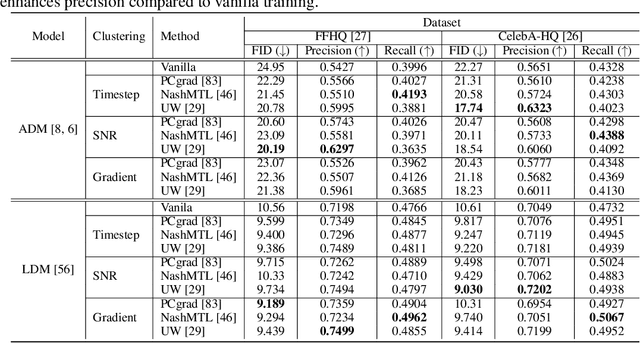
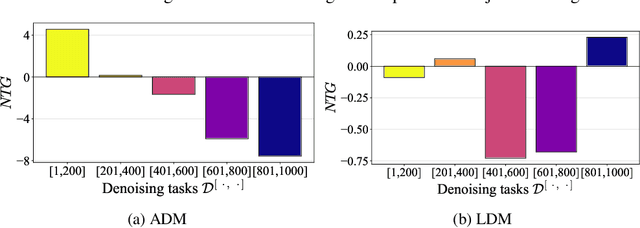

Diffusion-based generative models have achieved remarkable success in various domains. It trains a model on denoising tasks that encompass different noise levels simultaneously, representing a form of multi-task learning (MTL). However, analyzing and improving diffusion models from an MTL perspective remains under-explored. In particular, MTL can sometimes lead to the well-known phenomenon of $\textit{negative transfer}$, which results in the performance degradation of certain tasks due to conflicts between tasks. In this paper, we aim to analyze diffusion training from an MTL standpoint, presenting two key observations: $\textbf{(O1)}$ the task affinity between denoising tasks diminishes as the gap between noise levels widens, and $\textbf{(O2)}$ negative transfer can arise even in the context of diffusion training. Building upon these observations, our objective is to enhance diffusion training by mitigating negative transfer. To achieve this, we propose leveraging existing MTL methods, but the presence of a huge number of denoising tasks makes this computationally expensive to calculate the necessary per-task loss or gradient. To address this challenge, we propose clustering the denoising tasks into small task clusters and applying MTL methods to them. Specifically, based on $\textbf{(O2)}$, we employ interval clustering to enforce temporal proximity among denoising tasks within clusters. We show that interval clustering can be solved with dynamic programming and utilize signal-to-noise ratio, timestep, and task affinity for clustering objectives. Through this, our approach addresses the issue of negative transfer in diffusion models by allowing for efficient computation of MTL methods. We validate the proposed clustering and its integration with MTL methods through various experiments, demonstrating improved sample quality of diffusion models.