 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOHPER: Multi-objective Hyperparameter Optimization Framework for E-commerce Retrieval System
Mar 07, 2025



E-commerce search optimization has evolved to include a wider range of metrics that reflect user engagement and business objectives. Modern search frameworks now incorporate advanced quality features, such as sales counts and document-query relevance, to better align search results with these goals. Traditional methods typically focus on click-through rate (CTR) as a measure of engagement or relevance, but this can miss true purchase intent, creating a gap between user interest and actual conversions. Joint training with the click-through conversion rate (CTCVR) has become essential for understanding buying behavior, although its sparsity poses challenges for reliable optimization. This study presents MOHPER, a Multi-Objective Hyperparameter Optimization framework for E-commerce Retrieval systems. Utilizing Bayesian optimization and sampling, it jointly optimizes both CTR, CTCVR, and relevant objectives, focusing on engagement and conversion of the users. In addition, to improve the selection of the best configuration from multi-objective optimization, we suggest advanced methods for hyperparameter selection, including a meta-configuration voting strategy and a cumulative training approach that leverages prior optimal configurations, to improve speeds of training and efficiency. Currently deployed in a live setting, our proposed framework substantiates its practical efficacy in achieving a balanced optimization that aligns with both user satisfaction and revenue goals.
Addressing Cold Start Problem for End-to-end Automatic Speech Scoring
Jun 25, 2023



Integrating automatic speech scoring/assessment systems has become a critical aspect of second-language speaking education. With self-supervised learning advancements, end-to-end speech scoring approaches have exhibited promising results. However, this study highlights the significant decrease in the performance of speech scoring systems in new question contexts, thereby identifying this as a cold start problem in terms of items. With the finding of cold-start phenomena, this paper seeks to alleviate the problem by following methods: 1) prompt embeddings, 2) question context embeddings using BERT or CLIP models, and 3) choice of the pretrained acoustic model. Experiments are conducted on TOEIC speaking test datasets collected from English-as-a-second-language (ESL) learners rated by professional TOEIC speaking evaluators. The results demonstrate that the proposed framework not only exhibits robustness in a cold-start environment but also outperforms the baselines for known content.
End-to-End Trainable Self-Attentive Shallow Network for Text-Independent Speaker Verification
Aug 14, 2020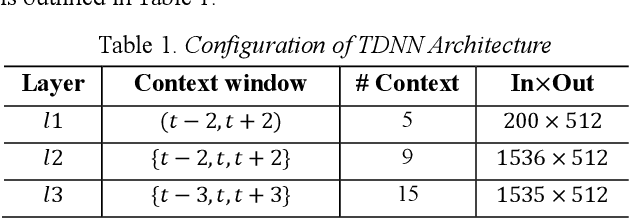
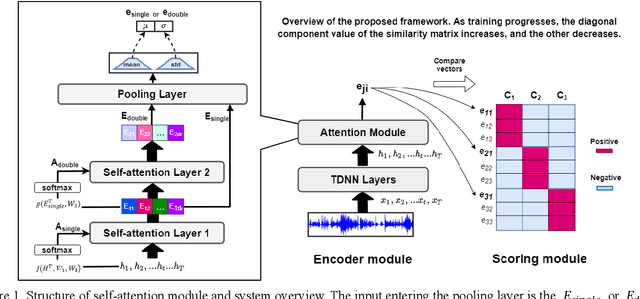

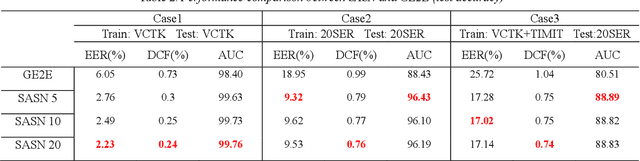
Generalized end-to-end (GE2E) model is widely used in speaker verification (SV) fields due to its expandability and generality regardless of specific languages. However, the long-short term memory (LSTM) based on GE2E has two limitations: First, the embedding of GE2E suffers from vanishing gradient, which leads to performance degradation for very long input sequences. Secondly, utterances are not represented as a properly fixed dimensional vector. In this paper, to overcome issues mentioned above, we propose a novel framework for SV, end-to-end trainable self-attentive shallow network (SASN), incorporating a time-delay neural network (TDNN) and a self-attentive pooling mechanism based on the self-attentive x-vector system during an utterance embedding phase. We demonstrate that the proposed model is highly efficient, and provides more accurate speaker verification than GE2E. For VCTK dataset, with just less than half the size of GE2E, the proposed model showed significant performance improvement over GE2E of about 63%, 67%, and 85% in EER (Equal error rate), DCF (Detection cost function), and AUC (Area under the curve), respectively. Notably, when the input length becomes longer, the DCF score improvement of the proposed model is about 17 times greater than that of GE2E.