 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEER: A Comprehensive and Reliable Benchmark for Deep-Research Expert Reports
Dec 19, 2025As large language models (LLMs) advance, deep research systems can generate expert-level reports via multi-step reasoning and evidence-based synthesis, but evaluating such reports remains challenging. Existing benchmarks often lack systematic criteria for expert reporting, evaluations that rely heavily on LLM judges can fail to capture issues that require expert judgment, and source verification typically covers only a limited subset of explicitly cited statements rather than report-wide factual reliability. We introduce DEER, a benchmark for evaluating expert-level deep research reports. DEER comprises 50 report-writing tasks spanning 13 domains and an expert-grounded evaluation taxonomy (7 dimensions, 25 sub-dimension) operationalized into 130 fine-grained rubric items. DEER further provides task-specific expert guidance to help LLM judges assess expert-level report quality more consistently. Complementing rubric-based assessment, we propose a document-level fact-checking architecture that extracts and verifies all claims across the entire report, including both cited and uncited ones, and quantifies external-evidence quality. DEER correlates closely with human expert judgments and yields interpretable diagnostics of system strengths and weaknesses.
Towards Fully-Automated Materials Discovery via Large-Scale Synthesis Dataset and Expert-Level LLM-as-a-Judge
Feb 23, 2025Materials synthesis is vital for innovations such as energy storage, catalysis, electronics, and biomedical devices. Yet, the process relies heavily on empirical, trial-and-error methods guided by expert intuition. Our work aims to support the materials science community by providing a practical, data-driven resource. We have curated a comprehensive dataset of 17K expert-verified synthesis recipes from open-access literature, which forms the basis of our newly developed benchmark, AlchemyBench. AlchemyBench offers an end-to-end framework that supports research in large language models applied to synthesis prediction. It encompasses key tasks, including raw materials and equipment prediction, synthesis procedure generation, and characterization outcome forecasting. We propose an LLM-as-a-Judge framework that leverages large language models for automated evaluation, demonstrating strong statistical agreement with expert assessments. Overall, our contributions offer a supportive foundation for exploring the capabilities of LLMs in predicting and guiding materials synthesis, ultimately paving the way for more efficient experimental design and accelerated innovation in materials science.
Break the Breakout: Reinventing LM Defense Against Jailbreak Attacks with Self-Refinement
Feb 27, 2024Caution: This paper includes offensive words that could potentially cause unpleasantness. Language models (LMs) are vulnerable to exploitation for adversarial misuse. Training LMs for safety alignment is extensive and makes it hard to respond to fast-developing attacks immediately, such as jailbreaks. We propose self-refine with formatting that achieves outstanding safety even in non-safety-aligned LMs and evaluate our method alongside several defense baselines, demonstrating that it is the safest training-free method against jailbreak attacks. Additionally, we proposed a formatting method that improves the efficiency of the self-refine process while reducing attack success rates in fewer iterations. We've also observed that non-safety-aligned LMs outperform safety-aligned LMs in safety tasks by giving more helpful and safe responses. In conclusion, our findings can achieve less safety risk with fewer computational costs, allowing non-safety LM to be easily utilized in real-world service.
GTA: Gated Toxicity Avoidance for LM Performance Preservation
Dec 11, 2023
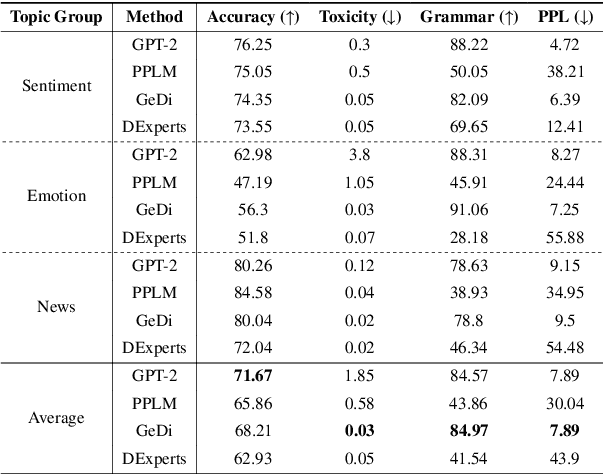
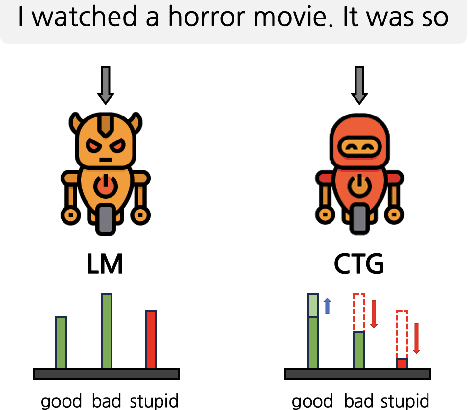
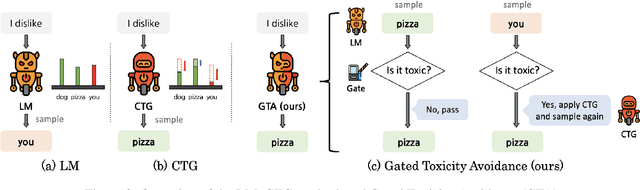
Caution: This paper includes offensive words that could potentially cause unpleasantness. The fast-paced evolution of generative language models such as GPT-4 has demonstrated outstanding results in various NLP generation tasks. However, due to the potential generation of offensive words related to race or gender, various Controllable Text Generation (CTG) methods have been proposed to mitigate the occurrence of harmful words. However, existing CTG methods not only reduce toxicity but also negatively impact several aspects of the language model's generation performance, including topic consistency, grammar, and perplexity. This paper explores the limitations of previous methods and introduces a novel solution in the form of a simple Gated Toxicity Avoidance (GTA) that can be applied to any CTG method. We also evaluate the effectiveness of the proposed GTA by comparing it with state-of-the-art CTG methods across various datasets. Our findings reveal that gated toxicity avoidance efficiently achieves comparable levels of toxicity reduction to the original CTG methods while preserving the generation performance of the language model.