 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross Encoding as Augmentation: Towards Effective Educational Text Classification
May 31, 2023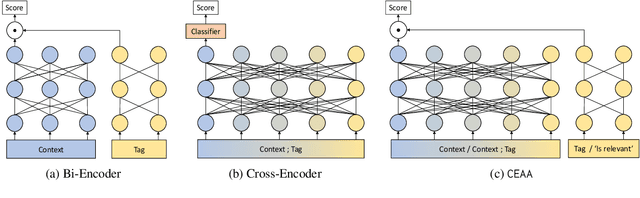
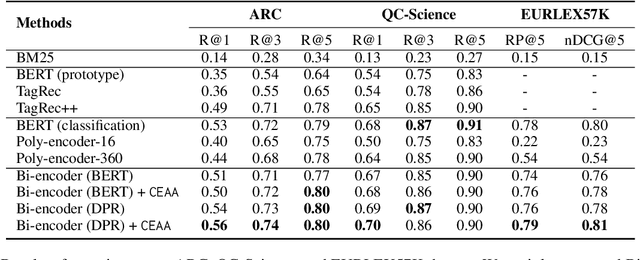
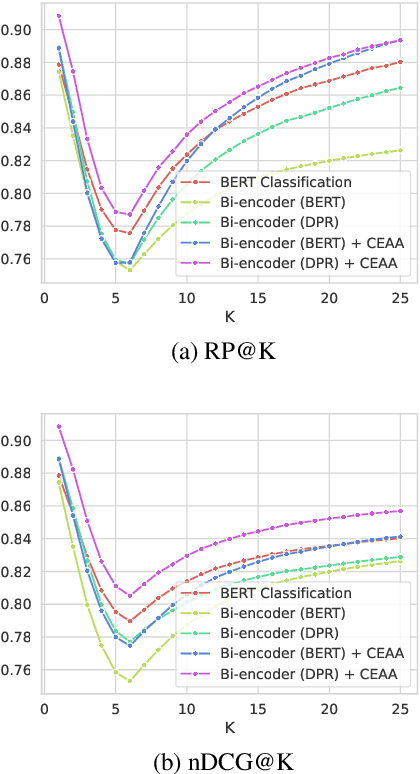
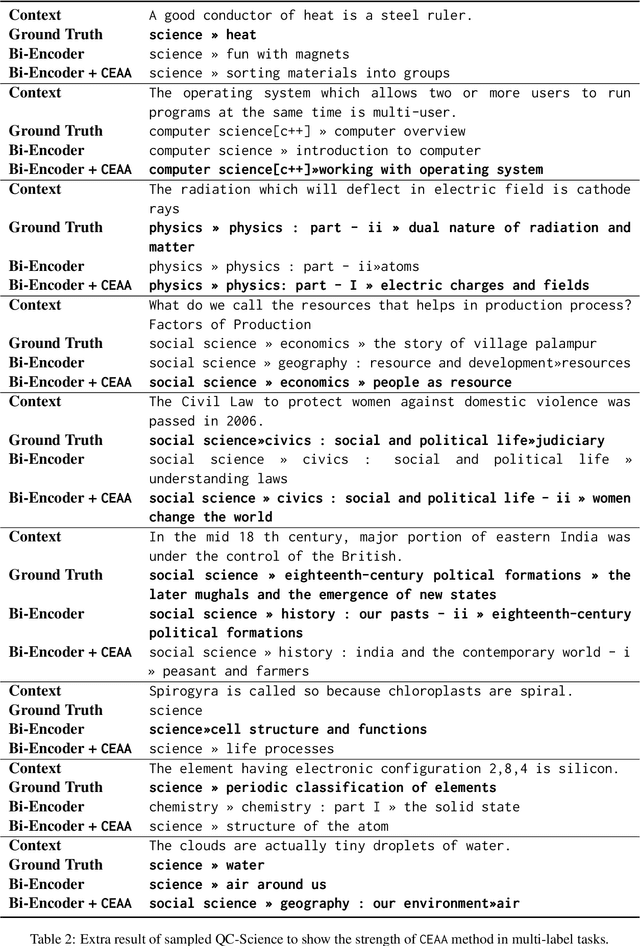
Text classification in education, usually called auto-tagging, is the automated process of assigning relevant tags to educational content, such as questions and textbooks. However, auto-tagging suffers from a data scarcity problem, which stems from two major challenges: 1) it possesses a large tag space and 2) it is multi-label. Though a retrieval approach is reportedly good at low-resource scenarios, there have been fewer efforts to directly address the data scarcity problem. To mitigate these issues, here we propose a novel retrieval approach CEAA that provides effective learning in educational text classification. Our main contributions are as follows: 1) we leverage transfer learning from question-answering datasets, and 2) we propose a simple but effective data augmentation method introducing cross-encoder style texts to a bi-encoder architecture for more efficient inference. An extensive set of experiments shows that our proposed method is effective in multi-label scenarios and low-resource tags compared to state-of-the-art models.
Visualizing the embedding space to explain the effect of knowledge distillation
Oct 09, 2021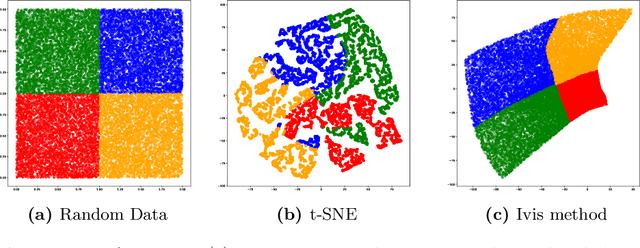
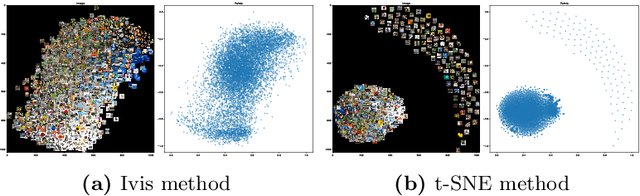
Recent research has found that knowledge distillation can be effective in reducing the size of a network and in increasing generalization. A pre-trained, large teacher network, for example, was shown to be able to bootstrap a student model that eventually outperforms the teacher in a limited label environment. Despite these advances, it still is relatively unclear \emph{why} this method works, that is, what the resulting student model does 'better'. To address this issue, here, we utilize two non-linear, low-dimensional embedding methods (t-SNE and IVIS) to visualize representation spaces of different layers in a network. We perform a set of extensive experiments with different architecture parameters and distillation methods. The resulting visualizations and metrics clearly show that distillation guides the network to find a more compact representation space for higher accuracy already in earlier layers compared to its non-distilled version.
Comparing Facial Expression Recognition in Humans and Machines: Using CAM, GradCAM, and Extremal Perturbation
Oct 09, 2021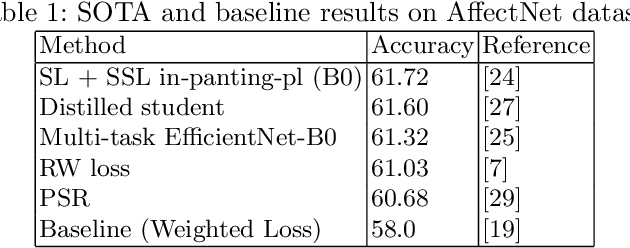

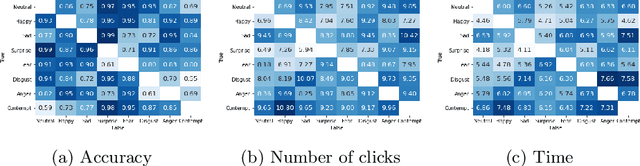
Facial expression recognition (FER) is a topic attracting significant research in both psychology and machine learning with a wide range of applications. Despite a wealth of research on human FER and considerable progress in computational FER made possible by deep neural networks (DNNs), comparatively less work has been done on comparing the degree to which DNNs may be comparable to human performance. In this work, we compared the recognition performance and attention patterns of humans and machines during a two-alternative forced-choice FER task. Human attention was here gathered through click data that progressively uncovered a face, whereas model attention was obtained using three different popular techniques from explainable AI: CAM, GradCAM and Extremal Perturbation. In both cases, performance was gathered as percent correct. For this task, we found that humans outperformed machines quite significantly. In terms of attention patterns, we found that Extremal Perturbation had the best overall fit with the human attention map during the task.
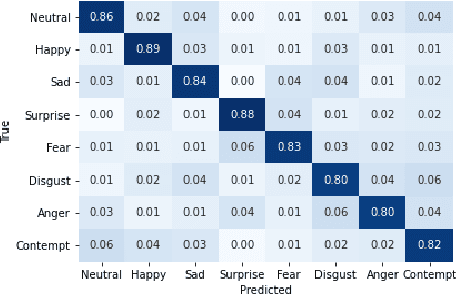
Label quality in AffectNet: results of crowd-based re-annotation
Oct 09, 2021
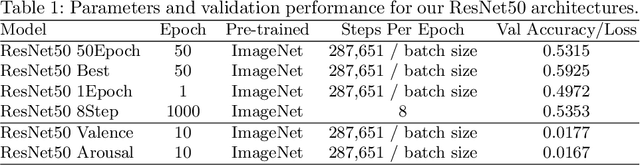
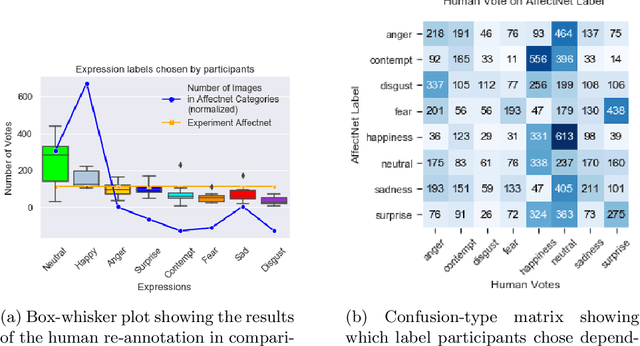
AffectNet is one of the most popular resources for facial expression recognition (FER) on relatively unconstrained in-the-wild images. Given that images were annotated by only one annotator with limited consistency checks on the data, however, label quality and consistency may be limited. Here, we take a similar approach to a study that re-labeled another, smaller dataset (FER2013) with crowd-based annotations, and report results from a re-labeling and re-annotation of a subset of difficult AffectNet faces with 13 people on both expression label, and valence and arousal ratings. Our results show that human labels overall have medium to good consistency, whereas human ratings especially for valence are in excellent agreement. Importantly, however, crowd-based labels are significantly shifting towards neutral and happy categories and crowd-based affective ratings form a consistent pattern different from the original ratings. ResNets fully trained on the original AffectNet dataset do not predict human voting patterns, but when weakly-trained do so much better, particularly for valence. Our results have important ramifications for label quality in affective computing.
Paperswithtopic: Topic Identification from Paper Title Only
Oct 09, 2021

The deep learning field is growing rapidly as witnessed by the exponential growth of papers submitted to journals, conferences, and pre-print servers. To cope with the sheer number of papers, several text mining tools from natural language processing (NLP) have been proposed that enable researchers to keep track of recent findings. In this context, our paper makes two main contributions: first, we collected and annotated a dataset of papers paired by title and sub-field from the field of artificial intelligence (AI), and, second, we present results on how to predict a paper's AI sub-field from a given paper title only. Importantly, for the latter, short-text classification task we compare several algorithms from conventional machine learning all the way up to recent, larger transformer architectures. Finally, for the transformer models, we also present gradient-based, attention visualizations to further explain the model's classification process. All code can be found at \url{https://github.com/1pha/paperswithtopic}
Predicting decision-making in the future: Human versus Machine
Oct 09, 2021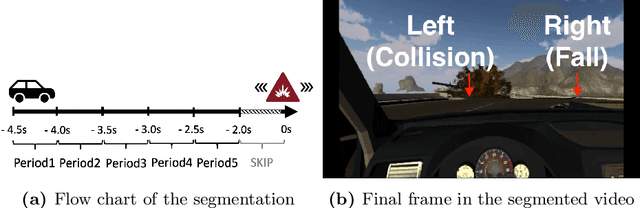
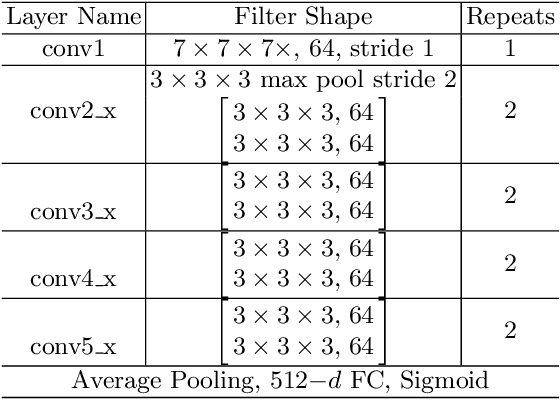
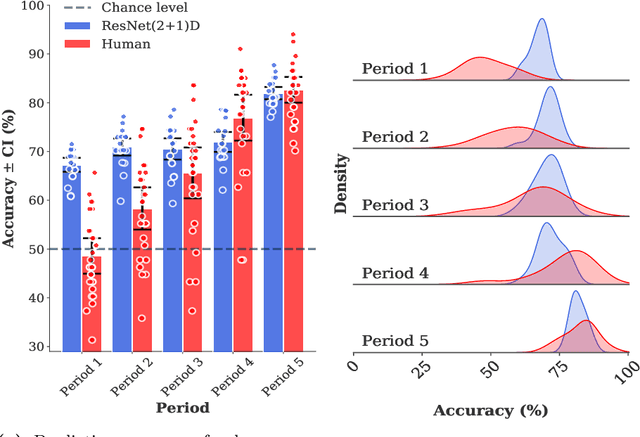

Deep neural networks (DNNs) have become remarkably successful in data prediction, and have even been used to predict future actions based on limited input. This raises the question: do these systems actually "understand" the event similar to humans? Here, we address this issue using videos taken from an accident situation in a driving simulation. In this situation, drivers had to choose between crashing into a suddenly-appeared obstacle or steering their car off a previously indicated cliff. We compared how well humans and a DNN predicted this decision as a function of time before the event. The DNN outperformed humans for early time-points, but had an equal performance for later time-points. Interestingly, spatio-temporal image manipulations and Grad-CAM visualizations uncovered some expected behavior, but also highlighted potential differences in temporal processing for the DNN.
The Unreasonable Effectiveness of Encoder-Decoder Networks for Retinal Vessel Segmentation
Nov 25, 2020
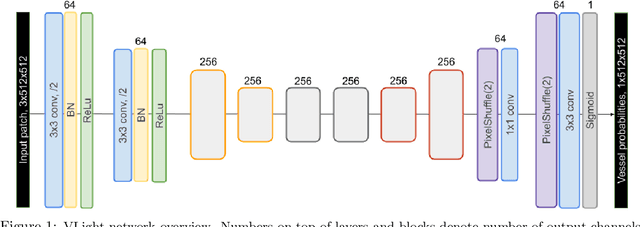
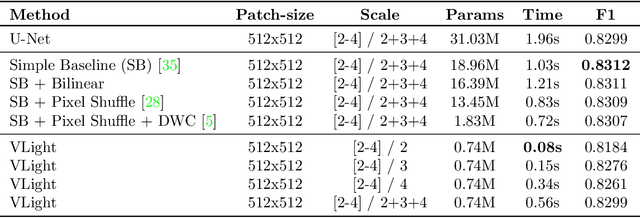
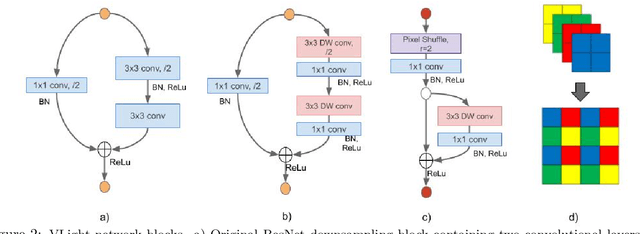
We propose an encoder-decoder framework for the segmentation of blood vessels in retinal images that relies on the extraction of large-scale patches at multiple image-scales during training. Experiments on three fundus image datasets demonstrate that this approach achieves state-of-the-art results and can be implemented using a simple and efficient fully-convolutional network with a parameter count of less than 0.8M. Furthermore, we show that this framework - called VLight - avoids overfitting to specific training images and generalizes well across different datasets, which makes it highly suitable for real-world applications where robustness, accuracy as well as low inference time on high-resolution fundus images is required.
3FabRec: Fast Few-shot Face alignment by Reconstruction
Nov 24, 2019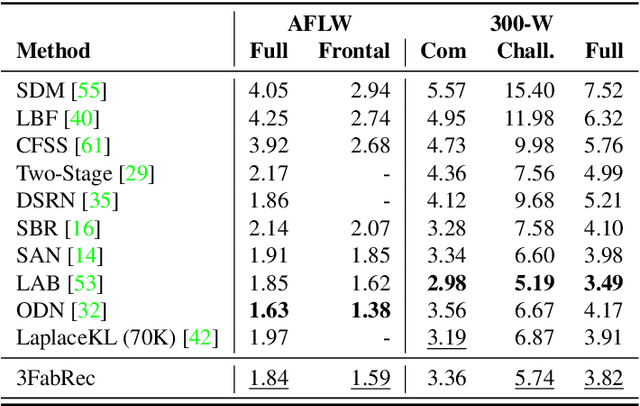

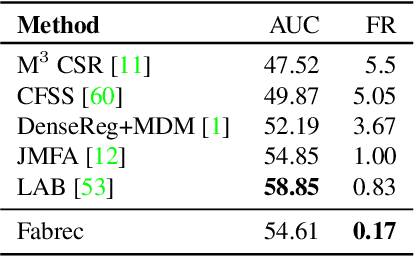

Current supervised frameworks for facial landmark detection require a large amount of training data and due to the massive number of parameters may suffer from overfitting to the specific datasets. We introduce a semi-supervised method in which the crucial idea is to first generate implicit knowledge about the face appearance & shape from the large amounts of unlabeled images of faces available today. In a first, unsupervised stage, we train an adversarial autoencoder to reconstruct faces via a low-dimensional, latent face-representation vector. In a second, supervised stage, we augment the generator-decoder pipeline with interleaved transfer layers in order to both reconstruct the face and a probabilistic landmark heatmap. We show that this framework (3FabRec) achieves state-of-the-art performance on popular benchmarks, such as 300-W, AFLW, and WLFW. Importantly, due to the power of the implicit face representation, our framework achieves impressive landmark localization accuracy from only a few percent of training data to as low as even 10 images. As the interleaved layers only add a small number of parameters to the encoder, inference runs at several hundred FPS on a GPU.