 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel quality in AffectNet: results of crowd-based re-annotation
Oct 09, 2021
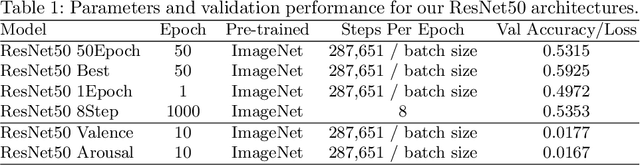
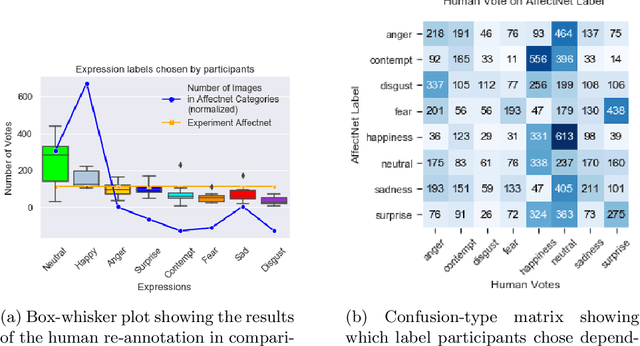
AffectNet is one of the most popular resources for facial expression recognition (FER) on relatively unconstrained in-the-wild images. Given that images were annotated by only one annotator with limited consistency checks on the data, however, label quality and consistency may be limited. Here, we take a similar approach to a study that re-labeled another, smaller dataset (FER2013) with crowd-based annotations, and report results from a re-labeling and re-annotation of a subset of difficult AffectNet faces with 13 people on both expression label, and valence and arousal ratings. Our results show that human labels overall have medium to good consistency, whereas human ratings especially for valence are in excellent agreement. Importantly, however, crowd-based labels are significantly shifting towards neutral and happy categories and crowd-based affective ratings form a consistent pattern different from the original ratings. ResNets fully trained on the original AffectNet dataset do not predict human voting patterns, but when weakly-trained do so much better, particularly for valence. Our results have important ramifications for label quality in affective computing.