Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Unreasonable Effectiveness of Encoder-Decoder Networks for Retinal Vessel Segmentation
Nov 25, 2020
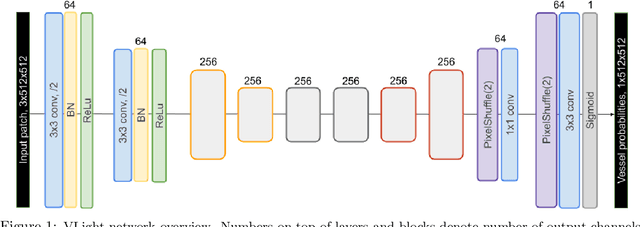
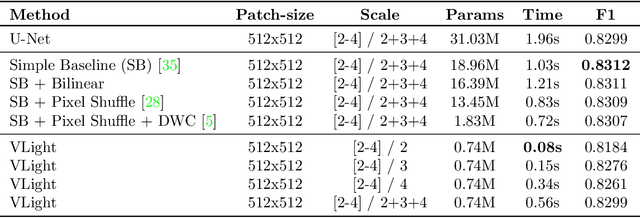
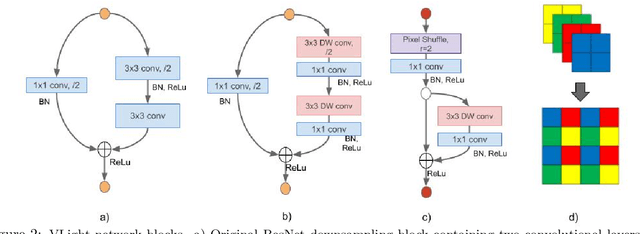
We propose an encoder-decoder framework for the segmentation of blood vessels in retinal images that relies on the extraction of large-scale patches at multiple image-scales during training. Experiments on three fundus image datasets demonstrate that this approach achieves state-of-the-art results and can be implemented using a simple and efficient fully-convolutional network with a parameter count of less than 0.8M. Furthermore, we show that this framework - called VLight - avoids overfitting to specific training images and generalizes well across different datasets, which makes it highly suitable for real-world applications where robustness, accuracy as well as low inference time on high-resolution fundus images is required.
* In: Fu H., Garvin M.K., MacGillivray T., Xu Y., Zheng Y. (eds)
Ophthalmic Medical Image Analysis. OMIA 2020. Lecture Notes in Computer
Science, vol 12069. Springer, Cham
Via