 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaperswithtopic: Topic Identification from Paper Title Only
Paper and Code

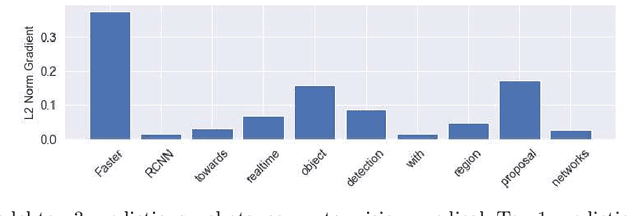

The deep learning field is growing rapidly as witnessed by the exponential growth of papers submitted to journals, conferences, and pre-print servers. To cope with the sheer number of papers, several text mining tools from natural language processing (NLP) have been proposed that enable researchers to keep track of recent findings. In this context, our paper makes two main contributions: first, we collected and annotated a dataset of papers paired by title and sub-field from the field of artificial intelligence (AI), and, second, we present results on how to predict a paper's AI sub-field from a given paper title only. Importantly, for the latter, short-text classification task we compare several algorithms from conventional machine learning all the way up to recent, larger transformer architectures. Finally, for the transformer models, we also present gradient-based, attention visualizations to further explain the model's classification process. All code can be found at \url{https://github.com/1pha/paperswithtopic}