 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3FabRec: Fast Few-shot Face alignment by Reconstruction
Paper and Code
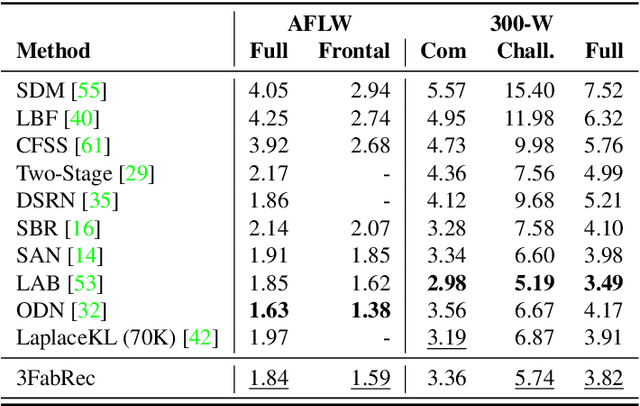

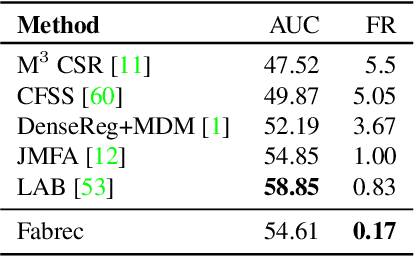

Current supervised frameworks for facial landmark detection require a large amount of training data and due to the massive number of parameters may suffer from overfitting to the specific datasets. We introduce a semi-supervised method in which the crucial idea is to first generate implicit knowledge about the face appearance & shape from the large amounts of unlabeled images of faces available today. In a first, unsupervised stage, we train an adversarial autoencoder to reconstruct faces via a low-dimensional, latent face-representation vector. In a second, supervised stage, we augment the generator-decoder pipeline with interleaved transfer layers in order to both reconstruct the face and a probabilistic landmark heatmap. We show that this framework (3FabRec) achieves state-of-the-art performance on popular benchmarks, such as 300-W, AFLW, and WLFW. Importantly, due to the power of the implicit face representation, our framework achieves impressive landmark localization accuracy from only a few percent of training data to as low as even 10 images. As the interleaved layers only add a small number of parameters to the encoder, inference runs at several hundred FPS on a GPU.