 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Visual Code Mobile World Models
Feb 02, 2026Mobile Graphical User Interface (GUI) World Models (WMs) offer a promising path for improving mobile GUI agent performance at train- and inference-time. However, current approaches face a critical trade-off: text-based WMs sacrifice visual fidelity, while the inability of visual WMs in precise text rendering led to their reliance on slow, complex pipelines dependent on numerous external models. We propose a novel paradigm: visual world modeling via renderable code generation, where a single Vision-Language Model (VLM) predicts the next GUI state as executable web code that renders to pixels, rather than generating pixels directly. This combines the strengths of both approaches: VLMs retain their linguistic priors for precise text rendering while their pre-training on structured web code enables high-fidelity visual generation. We introduce gWorld (8B, 32B), the first open-weight visual mobile GUI WMs built on this paradigm, along with a data generation framework (gWorld) that automatically synthesizes code-based training data. In extensive evaluation across 4 in- and 2 out-of-distribution benchmarks, gWorld sets a new pareto frontier in accuracy versus model size, outperforming 8 frontier open-weight models over 50.25x larger. Further analyses show that (1) scaling training data via gWorld yields meaningful gains, (2) each component of our pipeline improves data quality, and (3) stronger world modeling improves downstream mobile GUI policy performance.
Trillion 7B Technical Report
Apr 21, 2025We introduce Trillion-7B, the most token-efficient Korean-centric multilingual LLM available. Our novel Cross-lingual Document Attention (XLDA) mechanism enables highly efficient and effective knowledge transfer from English to target languages like Korean and Japanese. Combined with optimized data mixtures, language-specific filtering, and tailored tokenizer construction, Trillion-7B achieves competitive performance while dedicating only 10\% of its 2T training tokens to multilingual data and requiring just 59.4K H100 GPU hours (\$148K) for full training. Comprehensive evaluations across 27 benchmarks in four languages demonstrate Trillion-7B's robust multilingual performance and exceptional cross-lingual consistency.
Generalized Gaussian Temporal Difference Error For Uncertainty-aware Reinforcement Learning
Aug 05, 2024



Conventional uncertainty-aware temporal difference (TD) learning methods often rely on simplistic assumptions, typically including a zero-mean Gaussian distribution for TD errors. Such oversimplification can lead to inaccurate error representations and compromised uncertainty estimation. In this paper, we introduce a novel framework for generalized Gaussian error modeling in deep reinforcement learning, applicable to both discrete and continuous control settings. Our framework enhances the flexibility of error distribution modeling by incorporating higher-order moments, particularly kurtosis, thereby improving the estimation and mitigation of data-dependent noise, i.e., aleatoric uncertainty. We examine the influence of the shape parameter of the generalized Gaussian distribution (GGD) on aleatoric uncertainty and provide a closed-form expression that demonstrates an inverse relationship between uncertainty and the shape parameter. Additionally, we propose a theoretically grounded weighting scheme to fully leverage the GGD. To address epistemic uncertainty, we enhance the batch inverse variance weighting by incorporating bias reduction and kurtosis considerations, resulting in improved robustness. Extensive experimental evaluations using policy gradient algorithms demonstrate the consistent efficacy of our method, showcasing significant performance improvements.
Towards Understanding the Relationship between In-context Learning and Compositional Generalization
Mar 18, 2024
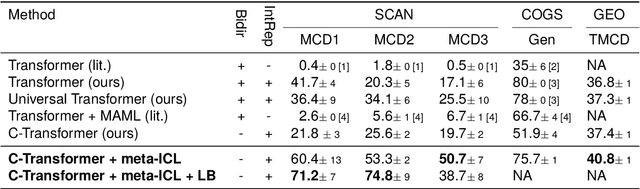
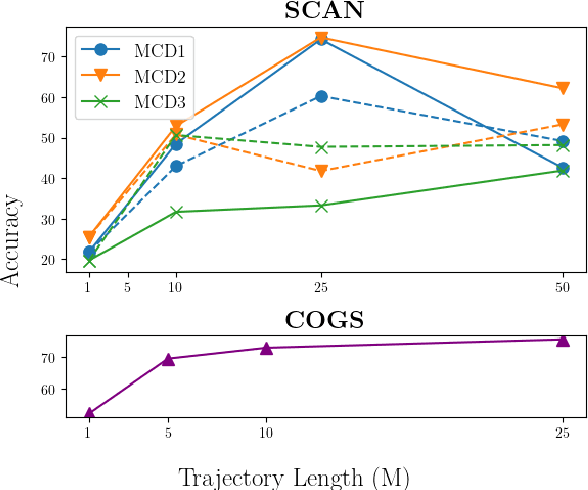
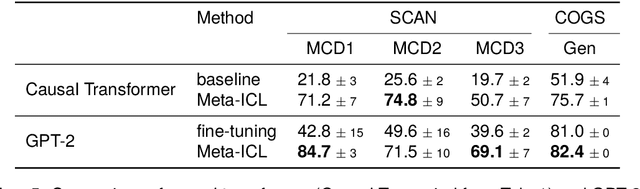
According to the principle of compositional generalization, the meaning of a complex expression can be understood as a function of the meaning of its parts and of how they are combined. This principle is crucial for human language processing and also, arguably, for NLP models in the face of out-of-distribution data. However, many neural network models, including Transformers, have been shown to struggle with compositional generalization. In this paper, we hypothesize that forcing models to in-context learn can provide an inductive bias to promote compositional generalization. To test this hypothesis, we train a causal Transformer in a setting that renders ordinary learning very difficult: we present it with different orderings of the training instance and shuffle instance labels. This corresponds to training the model on all possible few-shot learning problems attainable from the dataset. The model can solve the task, however, by utilizing earlier examples to generalize to later ones (i.e. in-context learning). In evaluations on the datasets, SCAN, COGS, and GeoQuery, models trained in this manner indeed show improved compositional generalization. This indicates the usefulness of in-context learning problems as an inductive bias for generalization.