 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMINR: Implicit Neural Representations with Masked Image Modelling
Jul 30, 2025Self-supervised learning methods like masked autoencoders (MAE) have shown significant promise in learning robust feature representations, particularly in image reconstruction-based pretraining task. However, their performance is often strongly dependent on the masking strategies used during training and can degrade when applied to out-of-distribution data. To address these limitations, we introduce the masked implicit neural representations (MINR) framework that synergizes implicit neural representations with masked image modeling. MINR learns a continuous function to represent images, enabling more robust and generalizable reconstructions irrespective of masking strategies. Our experiments demonstrate that MINR not only outperforms MAE in in-domain scenarios but also in out-of-distribution settings, while reducing model complexity. The versatility of MINR extends to various self-supervised learning applications, confirming its utility as a robust and efficient alternative to existing frameworks.
Generalized Gaussian Temporal Difference Error For Uncertainty-aware Reinforcement Learning
Aug 05, 2024



Conventional uncertainty-aware temporal difference (TD) learning methods often rely on simplistic assumptions, typically including a zero-mean Gaussian distribution for TD errors. Such oversimplification can lead to inaccurate error representations and compromised uncertainty estimation. In this paper, we introduce a novel framework for generalized Gaussian error modeling in deep reinforcement learning, applicable to both discrete and continuous control settings. Our framework enhances the flexibility of error distribution modeling by incorporating higher-order moments, particularly kurtosis, thereby improving the estimation and mitigation of data-dependent noise, i.e., aleatoric uncertainty. We examine the influence of the shape parameter of the generalized Gaussian distribution (GGD) on aleatoric uncertainty and provide a closed-form expression that demonstrates an inverse relationship between uncertainty and the shape parameter. Additionally, we propose a theoretically grounded weighting scheme to fully leverage the GGD. To address epistemic uncertainty, we enhance the batch inverse variance weighting by incorporating bias reduction and kurtosis considerations, resulting in improved robustness. Extensive experimental evaluations using policy gradient algorithms demonstrate the consistent efficacy of our method, showcasing significant performance improvements.
Feature-aligned N-BEATS with Sinkhorn divergence
May 24, 2023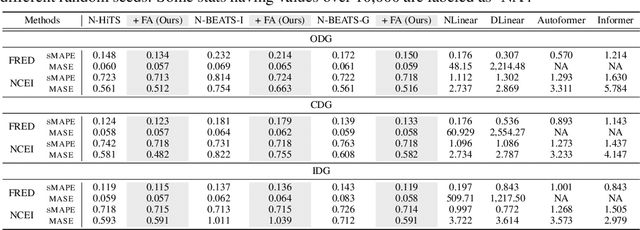
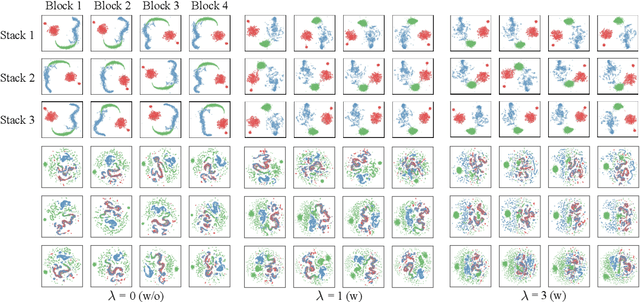
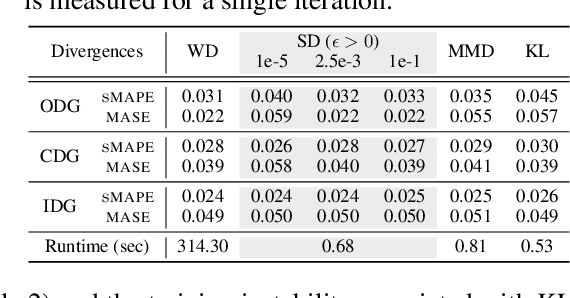
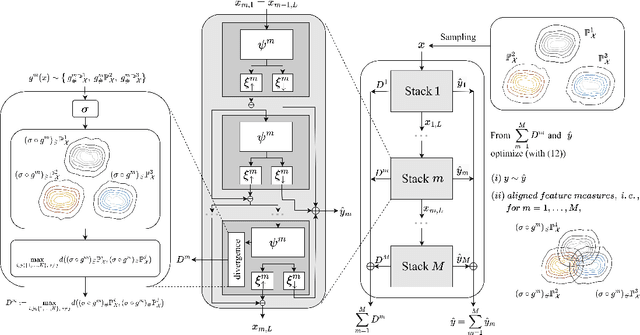
In this study, we propose Feature-aligned N-BEATS as a domain generalization model for univariate time series forecasting problems. The proposed model is an extension of the doubly residual stacking architecture of N-BEATS (Oreshkin et al. [34]) into a representation learning framework. The model is a new structure that involves marginal feature probability measures (i.e., pushforward measures of multiple source domains) induced by the intricate composition of residual operators of N-BEATS in each stack and aligns them stack-wise via an entropic regularized Wasserstein distance referred to as the Sinkhorn divergence (Genevay et al. [14]). The loss function consists of a typical forecasting loss for multiple source domains and an alignment loss calculated with the Sinkhorn divergence, which allows the model to learn invariant features stack-wise across multiple source data sequences while retaining N-BEATS's interpretable design. We conduct a comprehensive experimental evaluation of the proposed approach and the results demonstrate the model's forecasting and generalization capabilities in comparison with methods based on the original N-BEATS.