 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Visual Code Mobile World Models
Feb 02, 2026Mobile Graphical User Interface (GUI) World Models (WMs) offer a promising path for improving mobile GUI agent performance at train- and inference-time. However, current approaches face a critical trade-off: text-based WMs sacrifice visual fidelity, while the inability of visual WMs in precise text rendering led to their reliance on slow, complex pipelines dependent on numerous external models. We propose a novel paradigm: visual world modeling via renderable code generation, where a single Vision-Language Model (VLM) predicts the next GUI state as executable web code that renders to pixels, rather than generating pixels directly. This combines the strengths of both approaches: VLMs retain their linguistic priors for precise text rendering while their pre-training on structured web code enables high-fidelity visual generation. We introduce gWorld (8B, 32B), the first open-weight visual mobile GUI WMs built on this paradigm, along with a data generation framework (gWorld) that automatically synthesizes code-based training data. In extensive evaluation across 4 in- and 2 out-of-distribution benchmarks, gWorld sets a new pareto frontier in accuracy versus model size, outperforming 8 frontier open-weight models over 50.25x larger. Further analyses show that (1) scaling training data via gWorld yields meaningful gains, (2) each component of our pipeline improves data quality, and (3) stronger world modeling improves downstream mobile GUI policy performance.
Trillion 7B Technical Report
Apr 21, 2025We introduce Trillion-7B, the most token-efficient Korean-centric multilingual LLM available. Our novel Cross-lingual Document Attention (XLDA) mechanism enables highly efficient and effective knowledge transfer from English to target languages like Korean and Japanese. Combined with optimized data mixtures, language-specific filtering, and tailored tokenizer construction, Trillion-7B achieves competitive performance while dedicating only 10\% of its 2T training tokens to multilingual data and requiring just 59.4K H100 GPU hours (\$148K) for full training. Comprehensive evaluations across 27 benchmarks in four languages demonstrate Trillion-7B's robust multilingual performance and exceptional cross-lingual consistency.
The BiGGen Bench: A Principled Benchmark for Fine-grained Evaluation of Language Models with Language Models
Jun 09, 2024



As language models (LMs) become capable of handling a wide range of tasks, their evaluation is becoming as challenging as their development. Most generation benchmarks currently assess LMs using abstract evaluation criteria like helpfulness and harmlessness, which often lack the flexibility and granularity of human assessment. Additionally, these benchmarks tend to focus disproportionately on specific capabilities such as instruction following, leading to coverage bias. To overcome these limitations, we introduce the BiGGen Bench, a principled generation benchmark designed to thoroughly evaluate nine distinct capabilities of LMs across 77 diverse tasks. A key feature of the BiGGen Bench is its use of instance-specific evaluation criteria, closely mirroring the nuanced discernment of human evaluation. We apply this benchmark to assess 103 frontier LMs using five evaluator LMs. Our code, data, and evaluation results are all publicly available at https://github.com/prometheus-eval/prometheus-eval/tree/main/BiGGen-Bench.
Prometheus 2: An Open Source Language Model Specialized in Evaluating Other Language Models
May 02, 2024
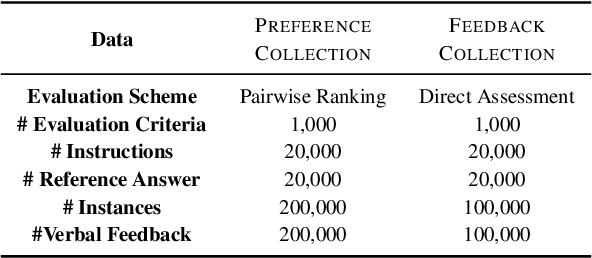


Proprietary LMs such as GPT-4 are often employed to assess the quality of responses from various LMs. However, concerns including transparency, controllability, and affordability strongly motivate the development of open-source LMs specialized in evaluations. On the other hand, existing open evaluator LMs exhibit critical shortcomings: 1) they issue scores that significantly diverge from those assigned by humans, and 2) they lack the flexibility to perform both direct assessment and pairwise ranking, the two most prevalent forms of assessment. Additionally, they do not possess the ability to evaluate based on custom evaluation criteria, focusing instead on general attributes like helpfulness and harmlessness. To address these issues, we introduce Prometheus 2, a more powerful evaluator LM than its predecessor that closely mirrors human and GPT-4 judgements. Moreover, it is capable of processing both direct assessment and pair-wise ranking formats grouped with a user-defined evaluation criteria. On four direct assessment benchmarks and four pairwise ranking benchmarks, Prometheus 2 scores the highest correlation and agreement with humans and proprietary LM judges among all tested open evaluator LMs. Our models, code, and data are all publicly available at https://github.com/prometheus-eval/prometheus-eval.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Prometheus: Inducing Fine-grained Evaluation Capability in Language Models
Oct 12, 2023Recently, using a powerful proprietary Large Language Model (LLM) (e.g., GPT-4) as an evaluator for long-form responses has become the de facto standard. However, for practitioners with large-scale evaluation tasks and custom criteria in consideration (e.g., child-readability), using proprietary LLMs as an evaluator is unreliable due to the closed-source nature, uncontrolled versioning, and prohibitive costs. In this work, we propose Prometheus, a fully open-source LLM that is on par with GPT-4's evaluation capabilities when the appropriate reference materials (reference answer, score rubric) are accompanied. We first construct the Feedback Collection, a new dataset that consists of 1K fine-grained score rubrics, 20K instructions, and 100K responses and language feedback generated by GPT-4. Using the Feedback Collection, we train Prometheus, a 13B evaluator LLM that can assess any given long-form text based on customized score rubric provided by the user. Experimental results show that Prometheus scores a Pearson correlation of 0.897 with human evaluators when evaluating with 45 customized score rubrics, which is on par with GPT-4 (0.882), and greatly outperforms ChatGPT (0.392). Furthermore, measuring correlation with GPT-4 with 1222 customized score rubrics across four benchmarks (MT Bench, Vicuna Bench, Feedback Bench, Flask Eval) shows similar trends, bolstering Prometheus's capability as an evaluator LLM. Lastly, Prometheus achieves the highest accuracy on two human preference benchmarks (HHH Alignment & MT Bench Human Judgment) compared to open-sourced reward models explicitly trained on human preference datasets, highlighting its potential as an universal reward model. We open-source our code, dataset, and model at https://github.com/kaistAI/Prometheus.
EvalLM: Interactive Evaluation of Large Language Model Prompts on User-Defined Criteria
Sep 24, 2023By simply composing prompts, developers can prototype novel generative applications with Large Language Models (LLMs). To refine prototypes into products, however, developers must iteratively revise prompts by evaluating outputs to diagnose weaknesses. Formative interviews (N=8) revealed that developers invest significant effort in manually evaluating outputs as they assess context-specific and subjective criteria. We present EvalLM, an interactive system for iteratively refining prompts by evaluating multiple outputs on user-defined criteria. By describing criteria in natural language, users can employ the system's LLM-based evaluator to get an overview of where prompts excel or fail, and improve these based on the evaluator's feedback. A comparative study (N=12) showed that EvalLM, when compared to manual evaluation, helped participants compose more diverse criteria, examine twice as many outputs, and reach satisfactory prompts with 59% fewer revisions. Beyond prompts, our work can be extended to augment model evaluation and alignment in specific application contexts.
Who Wrote this Code? Watermarking for Code Generation
May 24, 2023Large language models for code have recently shown remarkable performance in generating executable code. However, this rapid advancement has been accompanied by many legal and ethical concerns, such as code licensing issues, code plagiarism, and malware generation, making watermarking machine-generated code a very timely problem. Despite such imminent needs, we discover that existing watermarking and machine-generated text detection methods for LLMs fail to function with code generation tasks properly. Hence, in this work, we propose a new watermarking method, SWEET, that significantly improves upon previous approaches when watermarking machine-generated code. Our proposed method selectively applies watermarking to the tokens with high enough entropy, surpassing a defined threshold. The experiments on code generation benchmarks show that our watermarked code has superior quality compared to code produced by the previous state-of-the-art LLM watermarking method. Furthermore, our watermark method also outperforms DetectGPT for the task of machine-generated code detection.
Revealing User Familiarity Bias in Task-Oriented Dialogue via Interactive Evaluation
May 23, 2023Most task-oriented dialogue (TOD) benchmarks assume users that know exactly how to use the system by constraining the user behaviors within the system's capabilities via strict user goals, namely "user familiarity" bias. This data bias deepens when it combines with data-driven TOD systems, as it is impossible to fathom the effect of it with existing static evaluations. Hence, we conduct an interactive user study to unveil how vulnerable TOD systems are against realistic scenarios. In particular, we compare users with 1) detailed goal instructions that conform to the system boundaries (closed-goal) and 2) vague goal instructions that are often unsupported but realistic (open-goal). Our study reveals that conversations in open-goal settings lead to catastrophic failures of the system, in which 92% of the dialogues had significant issues. Moreover, we conduct a thorough analysis to identify distinctive features between the two settings through error annotation. From this, we discover a novel "pretending" behavior, in which the system pretends to handle the user requests even though they are beyond the system's capabilities. We discuss its characteristics and toxicity while emphasizing transparency and a fallback strategy for robust TOD systems.
Aligning Large Language Models through Synthetic Feedback
May 23, 2023Aligning large language models (LLMs) to human values has become increasingly important as it enables sophisticated steering of LLMs, e.g., making them follow given instructions while keeping them less toxic. However, it requires a significant amount of human demonstrations and feedback. Recently, open-sourced models have attempted to replicate the alignment learning process by distilling data from already aligned LLMs like InstructGPT or ChatGPT. While this process reduces human efforts, constructing these datasets has a heavy dependency on the teacher models. In this work, we propose a novel framework for alignment learning with almost no human labor and no dependency on pre-aligned LLMs. First, we perform reward modeling (RM) with synthetic feedback by contrasting responses from vanilla LLMs with various sizes and prompts. Then, we use the RM for simulating high-quality demonstrations to train a supervised policy and for further optimizing the model with reinforcement learning. Our resulting model, Aligned Language Model with Synthetic Training dataset (ALMoST), outperforms open-sourced models, including Alpaca, Dolly, and OpenAssistant, which are trained on the outputs of InstructGPT or human-annotated instructions. Our 7B-sized model outperforms the 12-13B models in the A/B tests using GPT-4 as the judge with about 75% winning rate on average.