 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs Deceive CLIP? Benchmarking Adversarial Compositionality of Pre-trained Multimodal Representation via Text Updates
May 28, 2025While pre-trained multimodal representations (e.g., CLIP) have shown impressive capabilities, they exhibit significant compositional vulnerabilities leading to counterintuitive judgments. We introduce Multimodal Adversarial Compositionality (MAC), a benchmark that leverages large language models (LLMs) to generate deceptive text samples to exploit these vulnerabilities across different modalities and evaluates them through both sample-wise attack success rate and group-wise entropy-based diversity. To improve zero-shot methods, we propose a self-training approach that leverages rejection-sampling fine-tuning with diversity-promoting filtering, which enhances both attack success rate and sample diversity. Using smaller language models like Llama-3.1-8B, our approach demonstrates superior performance in revealing compositional vulnerabilities across various multimodal representations, including images, videos, and audios.
Is a Peeled Apple Still Red? Evaluating LLMs' Ability for Conceptual Combination with Property Type
Feb 10, 2025Conceptual combination is a cognitive process that merges basic concepts, enabling the creation of complex expressions. During this process, the properties of combination (e.g., the whiteness of a peeled apple) can be inherited from basic concepts, newly emerge, or be canceled. However, previous studies have evaluated a limited set of properties and have not examined the generative process. To address this gap, we introduce the Conceptual Combination with Property Type dataset (CCPT), which consists of 12.3K annotated triplets of noun phrases, properties, and property types. Using CCPT, we establish three types of tasks to evaluate LLMs for conceptual combination thoroughly. Our key findings are threefold: (1) Our automatic metric grading property emergence and cancellation closely corresponds with human judgments. (2) LLMs, including OpenAI's o1, struggle to generate noun phrases which possess given emergent properties. (3) Our proposed method, inspired by cognitive psychology model that explains how relationships between concepts are formed, improves performances in all generative tasks. The dataset and experimental code are available at https://github.com/seokwon99/CCPT.git.
TimeChara: Evaluating Point-in-Time Character Hallucination of Role-Playing Large Language Models
May 28, 2024While Large Language Models (LLMs) can serve as agents to simulate human behaviors (i.e., role-playing agents), we emphasize the importance of point-in-time role-playing. This situates characters at specific moments in the narrative progression for three main reasons: (i) enhancing users' narrative immersion, (ii) avoiding spoilers, and (iii) fostering engagement in fandom role-playing. To accurately represent characters at specific time points, agents must avoid character hallucination, where they display knowledge that contradicts their characters' identities and historical timelines. We introduce TimeChara, a new benchmark designed to evaluate point-in-time character hallucination in role-playing LLMs. Comprising 10,895 instances generated through an automated pipeline, this benchmark reveals significant hallucination issues in current state-of-the-art LLMs (e.g., GPT-4o). To counter this challenge, we propose Narrative-Experts, a method that decomposes the reasoning steps and utilizes narrative experts to reduce point-in-time character hallucinations effectively. Still, our findings with TimeChara highlight the ongoing challenges of point-in-time character hallucination, calling for further study.
MPCHAT: Towards Multimodal Persona-Grounded Conversation
May 27, 2023In order to build self-consistent personalized dialogue agents, previous research has mostly focused on textual persona that delivers personal facts or personalities. However, to fully describe the multi-faceted nature of persona, image modality can help better reveal the speaker's personal characteristics and experiences in episodic memory (Rubin et al., 2003; Conway, 2009). In this work, we extend persona-based dialogue to the multimodal domain and make two main contributions. First, we present the first multimodal persona-based dialogue dataset named MPCHAT, which extends persona with both text and images to contain episodic memories. Second, we empirically show that incorporating multimodal persona, as measured by three proposed multimodal persona-grounded dialogue tasks (i.e., next response prediction, grounding persona prediction, and speaker identification), leads to statistically significant performance improvements across all tasks. Thus, our work highlights that multimodal persona is crucial for improving multimodal dialogue comprehension, and our MPCHAT serves as a high-quality resource for this research.
Who Wrote this Code? Watermarking for Code Generation
May 24, 2023Large language models for code have recently shown remarkable performance in generating executable code. However, this rapid advancement has been accompanied by many legal and ethical concerns, such as code licensing issues, code plagiarism, and malware generation, making watermarking machine-generated code a very timely problem. Despite such imminent needs, we discover that existing watermarking and machine-generated text detection methods for LLMs fail to function with code generation tasks properly. Hence, in this work, we propose a new watermarking method, SWEET, that significantly improves upon previous approaches when watermarking machine-generated code. Our proposed method selectively applies watermarking to the tokens with high enough entropy, surpassing a defined threshold. The experiments on code generation benchmarks show that our watermarked code has superior quality compared to code produced by the previous state-of-the-art LLM watermarking method. Furthermore, our watermark method also outperforms DetectGPT for the task of machine-generated code detection.
Sequential Latent Knowledge Selection for Knowledge-Grounded Dialogue
Feb 18, 2020
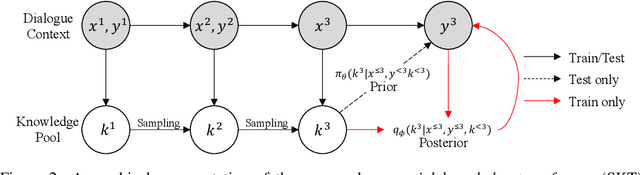
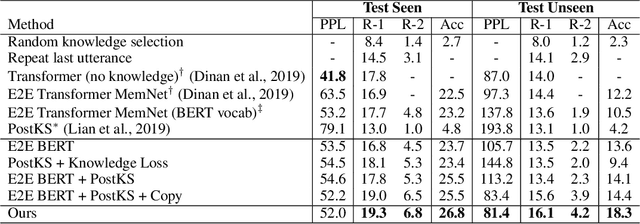
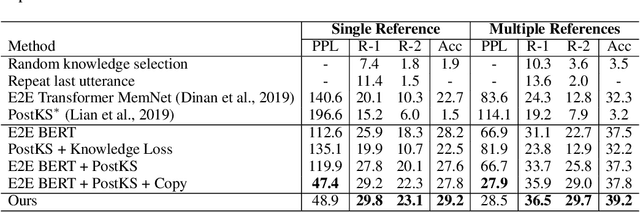
Knowledge-grounded dialogue is a task of generating an informative response based on both discourse context and external knowledge. As we focus on better modeling the knowledge selection in the multi-turn knowledge-grounded dialogue, we propose a sequential latent variable model as the first approach to this matter. The model named sequential knowledge transformer (SKT) can keep track of the prior and posterior distribution over knowledge; as a result, it can not only reduce the ambiguity caused from the diversity in knowledge selection of conversation but also better leverage the response information for proper choice of knowledge. Our experimental results show that the proposed model improves the knowledge selection accuracy and subsequently the performance of utterance generation. We achieve the new state-of-the-art performance on Wizard of Wikipedia (Dinan et al., 2019) as one of the most large-scale and challenging benchmarks. We further validate the effectiveness of our model over existing conversation methods in another knowledge-based dialogue Holl-E dataset (Moghe et al., 2018).