 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerspective-taking and Pragmatics for Generating Empathetic Responses Focused on Emotion Causes
Sep 21, 2021
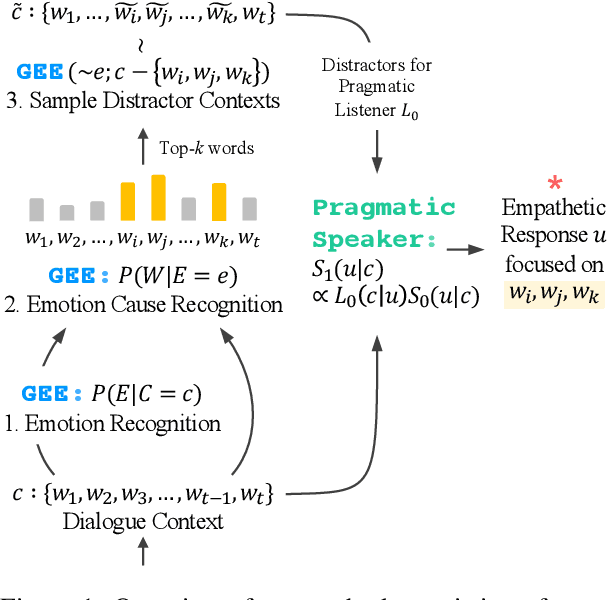

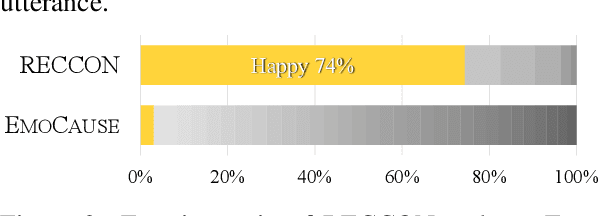
Empathy is a complex cognitive ability based on the reasoning of others' affective states. In order to better understand others and express stronger empathy in dialogues, we argue that two issues must be tackled at the same time: (i) identifying which word is the cause for the other's emotion from his or her utterance and (ii) reflecting those specific words in the response generation. However, previous approaches for recognizing emotion cause words in text require sub-utterance level annotations, which can be demanding. Taking inspiration from social cognition, we leverage a generative estimator to infer emotion cause words from utterances with no word-level label. Also, we introduce a novel method based on pragmatics to make dialogue models focus on targeted words in the input during generation. Our method is applicable to any dialogue models with no additional training on the fly. We show our approach improves multiple best-performing dialogue agents on generating more focused empathetic responses in terms of both automatic and human evaluation.
Public Self-consciousness for Endowing Dialogue Agents with Consistent Persona
Apr 13, 2020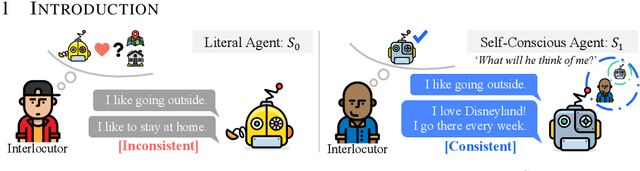
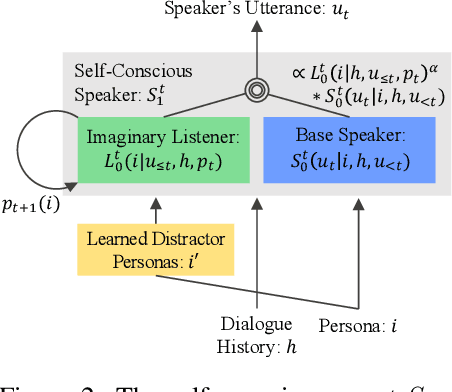
Although consistency has been a long-standing issue in dialogue agents, we show best-performing persona-conditioned generative models still suffer from high insensitivity to contradiction. Current approaches for improving consistency rely on supervised external models and labels which are demanding. Inspired by social cognition and pragmatics, we model public self-consciousness in dialogue agents through an imaginary listener to improve consistency. Our approach, based on the Rational Speech Acts framework (Frank & Goodman, 2012), attempts to maintain consistency in an unsupervised manner requiring neither additional annotations nor pretrained external models. We further extend the framework by learning the distractor supply for the first time. Experimental results show that our approach effectively reduces contradiction and improves consistency on Dialogue NLI (Welleck et al., 2019) and PersonaChat (Zhang et al., 2018).
Sequential Latent Knowledge Selection for Knowledge-Grounded Dialogue
Feb 18, 2020
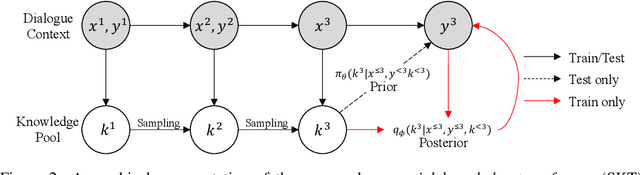
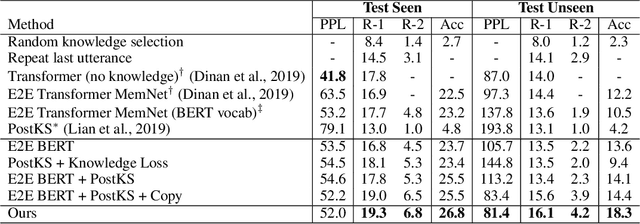
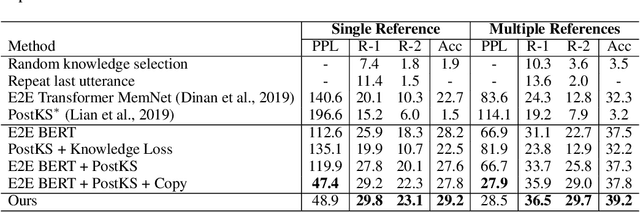
Knowledge-grounded dialogue is a task of generating an informative response based on both discourse context and external knowledge. As we focus on better modeling the knowledge selection in the multi-turn knowledge-grounded dialogue, we propose a sequential latent variable model as the first approach to this matter. The model named sequential knowledge transformer (SKT) can keep track of the prior and posterior distribution over knowledge; as a result, it can not only reduce the ambiguity caused from the diversity in knowledge selection of conversation but also better leverage the response information for proper choice of knowledge. Our experimental results show that the proposed model improves the knowledge selection accuracy and subsequently the performance of utterance generation. We achieve the new state-of-the-art performance on Wizard of Wikipedia (Dinan et al., 2019) as one of the most large-scale and challenging benchmarks. We further validate the effectiveness of our model over existing conversation methods in another knowledge-based dialogue Holl-E dataset (Moghe et al., 2018).
Abstractive Summarization of Reddit Posts with Multi-level Memory Networks
Nov 02, 2018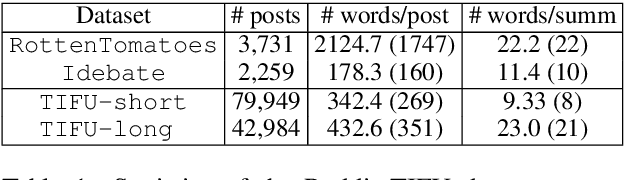


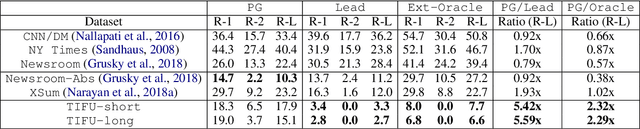
We address the problem of abstractive summarization in two directions: proposing a novel dataset and a new model. First, we collect Reddit TIFU dataset, consisting of 120K posts from the online discussion forum Reddit. We use such informal crowd-generated posts as text source, because we empirically observe that existing datasets mostly use formal documents as source text such as news articles; thus, they could suffer from some biases that key sentences usually located at the beginning of the text and favorable summary candidates are already inside the text in nearly exact forms. Such biases can not only be structural clues of which extractive methods better take advantage, but also be obstacles that hinder abstractive methods from learning their text abstraction capability. Second, we propose a novel abstractive summarization model named multi-level memory networks (MMN), equipped with multi-level memory to store the information of text from different levels of abstraction. With quantitative evaluation and user studies via Amazon Mechanical Turk, we show the Reddit TIFU dataset is highly abstractive and the MMN outperforms the state-of-the-art summarization models.
Attend to You: Personalized Image Captioning with Context Sequence Memory Networks
Apr 25, 2017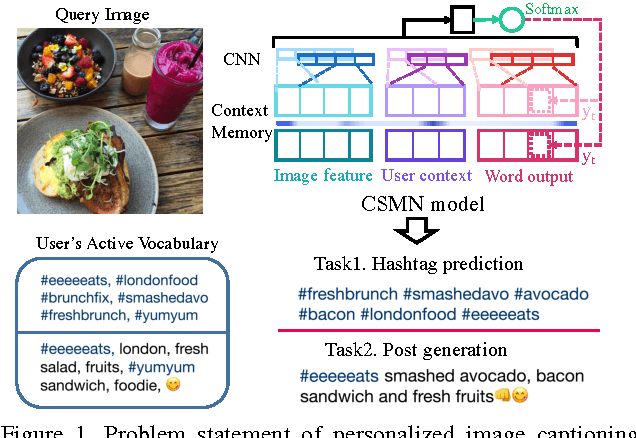

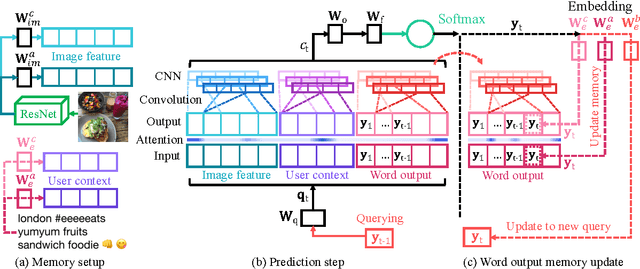

We address personalization issues of image captioning, which have not been discussed yet in previous research. For a query image, we aim to generate a descriptive sentence, accounting for prior knowledge such as the user's active vocabularies in previous documents. As applications of personalized image captioning, we tackle two post automation tasks: hashtag prediction and post generation, on our newly collected Instagram dataset, consisting of 1.1M posts from 6.3K users. We propose a novel captioning model named Context Sequence Memory Network (CSMN). Its unique updates over previous memory network models include (i) exploiting memory as a repository for multiple types of context information, (ii) appending previously generated words into memory to capture long-term information without suffering from the vanishing gradient problem, and (iii) adopting CNN memory structure to jointly represent nearby ordered memory slots for better context understanding. With quantitative evaluation and user studies via Amazon Mechanical Turk, we show the effectiveness of the three novel features of CSMN and its performance enhancement for personalized image captioning over state-of-the-art captioning models.
Unlimited Vocabulary Grapheme to Phoneme Conversion for Korean TTS
Jun 10, 1998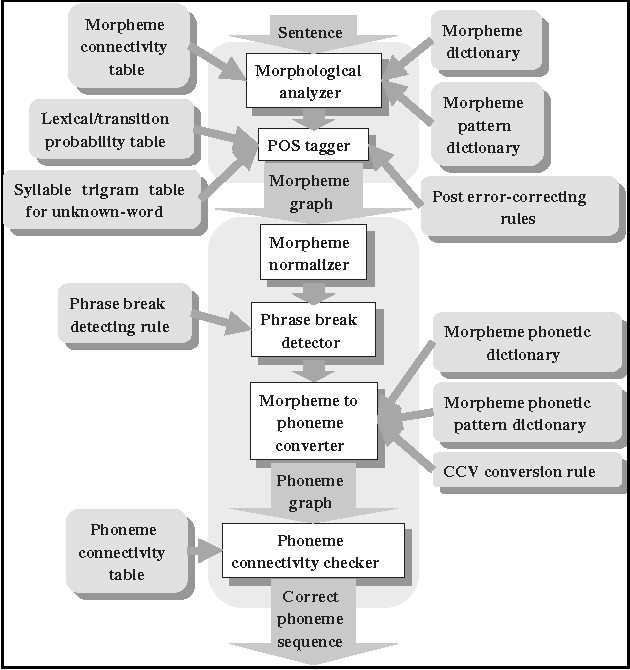

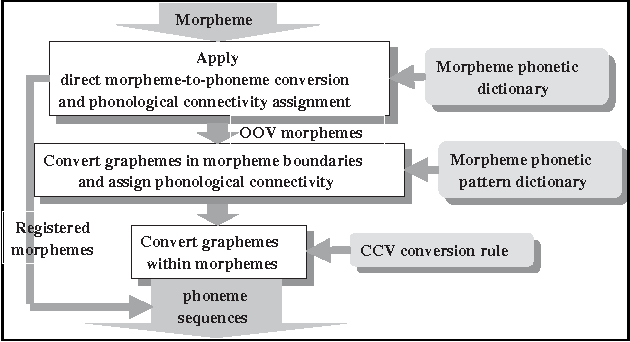

This paper describes a grapheme-to-phoneme conversion method using phoneme connectivity and CCV conversion rules. The method consists of mainly four modules including morpheme normalization, phrase-break detection, morpheme to phoneme conversion and phoneme connectivity check. The morpheme normalization is to replace non-Korean symbols into standard Korean graphemes. The phrase-break detector assigns phrase breaks using part-of-speech (POS) information. In the morpheme-to-phoneme conversion module, each morpheme in the phrase is converted into phonetic patterns by looking up the morpheme phonetic pattern dictionary which contains candidate phonological changes in boundaries of the morphemes. Graphemes within a morpheme are grouped into CCV patterns and converted into phonemes by the CCV conversion rules. The phoneme connectivity table supports grammaticality checking of the adjacent two phonetic morphemes. In the experiments with a corpus of 4,973 sentences, we achieved 99.9% of the grapheme-to-phoneme conversion performance and 97.5% of the sentence conversion performance. The full Korean TTS system is now being implemented using this conversion method.