 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlimited Vocabulary Grapheme to Phoneme Conversion for Korean TTS
Jun 10, 1998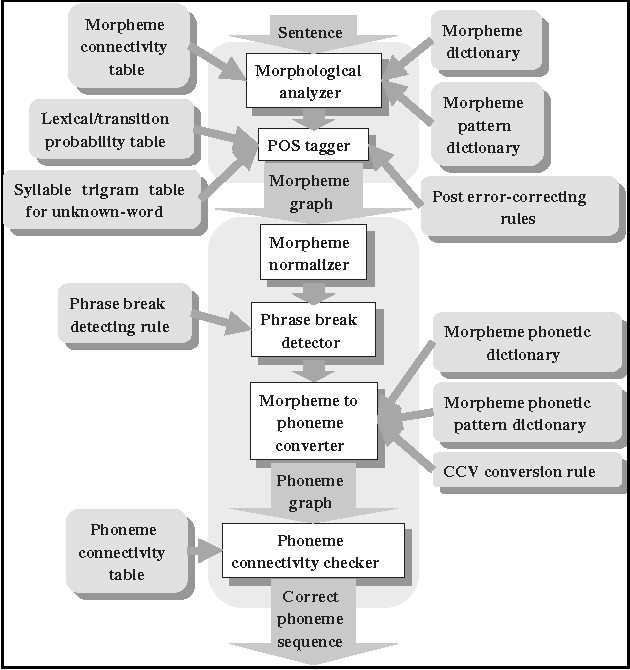

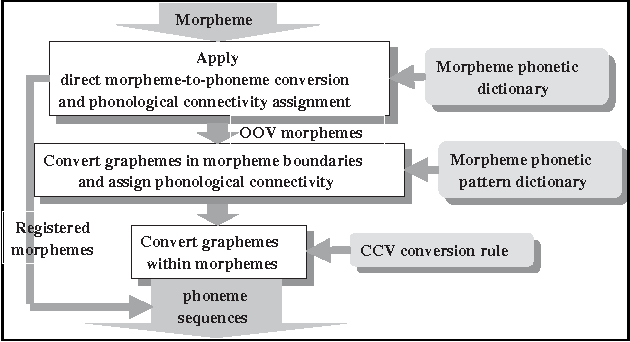

This paper describes a grapheme-to-phoneme conversion method using phoneme connectivity and CCV conversion rules. The method consists of mainly four modules including morpheme normalization, phrase-break detection, morpheme to phoneme conversion and phoneme connectivity check. The morpheme normalization is to replace non-Korean symbols into standard Korean graphemes. The phrase-break detector assigns phrase breaks using part-of-speech (POS) information. In the morpheme-to-phoneme conversion module, each morpheme in the phrase is converted into phonetic patterns by looking up the morpheme phonetic pattern dictionary which contains candidate phonological changes in boundaries of the morphemes. Graphemes within a morpheme are grouped into CCV patterns and converted into phonemes by the CCV conversion rules. The phoneme connectivity table supports grammaticality checking of the adjacent two phonetic morphemes. In the experiments with a corpus of 4,973 sentences, we achieved 99.9% of the grapheme-to-phoneme conversion performance and 97.5% of the sentence conversion performance. The full Korean TTS system is now being implemented using this conversion method.
Integrating HMM-Based Speech Recognition With Direct Manipulation In A Multimodal Korean Natural Language Interface
Nov 18, 1996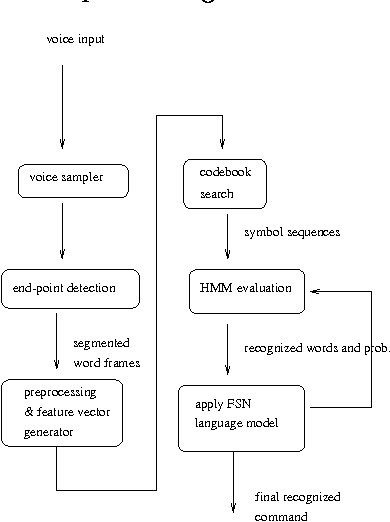
This paper presents a HMM-based speech recognition engine and its integration into direct manipulation interfaces for Korean document editor. Speech recognition can reduce typical tedious and repetitive actions which are inevitable in standard GUIs (graphic user interfaces). Our system consists of general speech recognition engine called ABrain {Auditory Brain} and speech commandable document editor called SHE {Simple Hearing Editor}. ABrain is a phoneme-based speech recognition engine which shows up to 97% of discrete command recognition rate. SHE is a EuroBridge widget-based document editor that supports speech commands as well as direct manipulation interfaces.
Phonological modeling for continuous speech recognition in Korean
Jul 18, 1996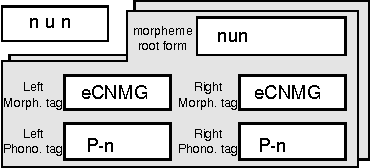

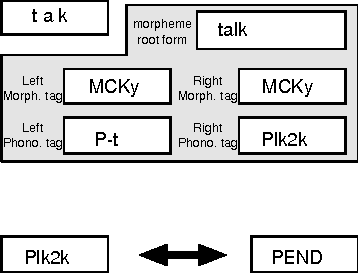
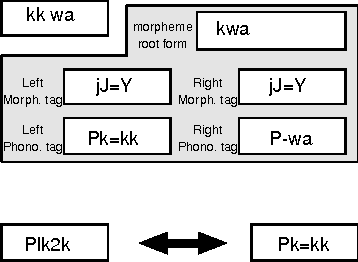
A new scheme to represent phonological changes during continuous speech recognition is suggested. A phonological tag coupled with its morphological tag is designed to represent the conditions of Korean phonological changes. A pairwise language model of these morphological and phonological tags is implemented in Korean speech recognition system. Performance of the model is verified through the TDNN-based speech recognition experiments.
Multi-level post-processing for Korean character recognition using morphological analysis and linguistic evaluation
Apr 24, 1996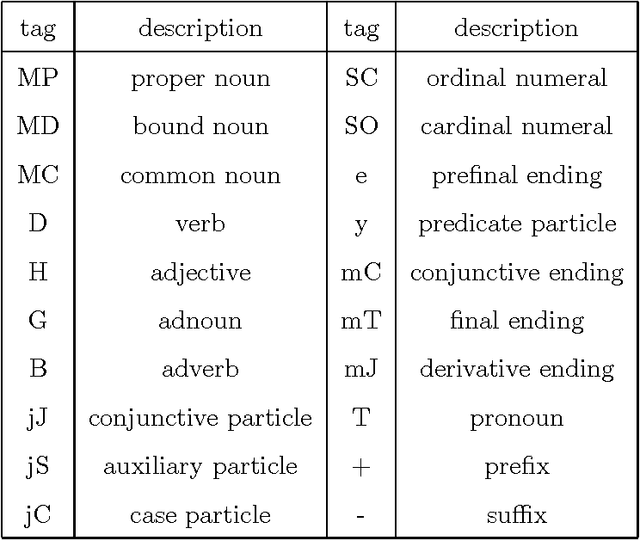
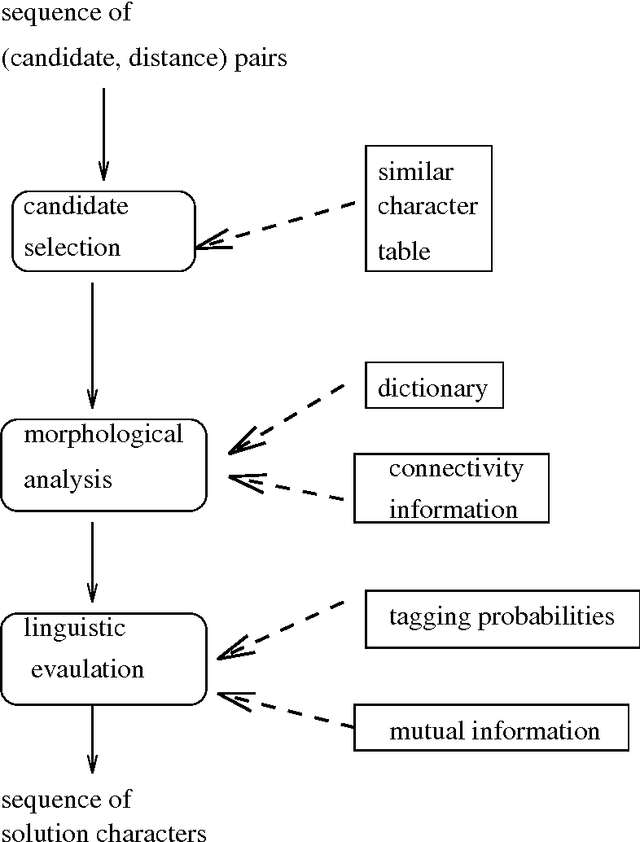
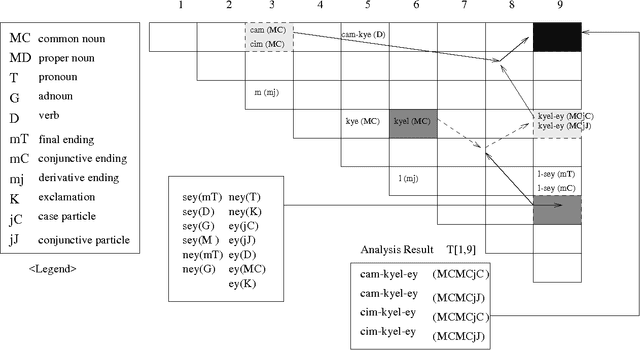
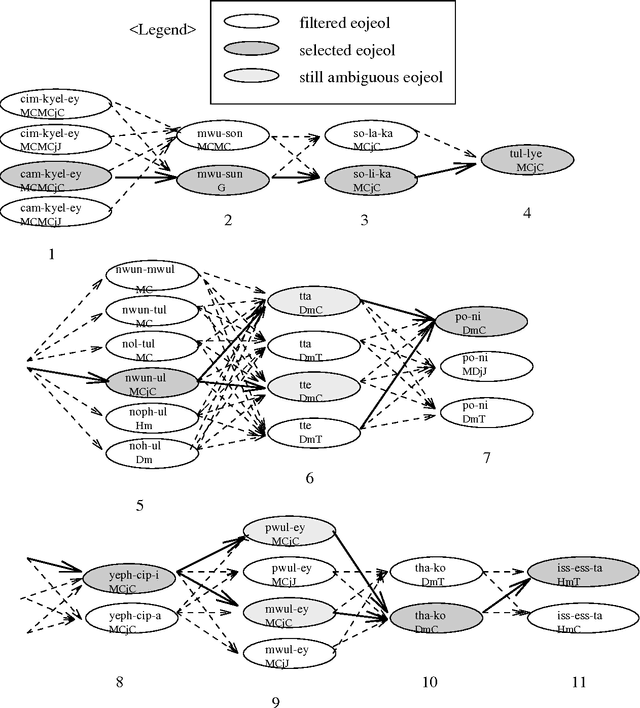
Most of the post-processing methods for character recognition rely on contextual information of character and word-fragment levels. However, due to linguistic characteristics of Korean, such low-level information alone is not sufficient for high-quality character-recognition applications, and we need much higher-level contextual information to improve the recognition results. This paper presents a domain independent post-processing technique that utilizes multi-level morphological, syntactic, and semantic information as well as character-level information. The proposed post-processing system performs three-level processing: candidate character-set selection, candidate eojeol (Korean word) generation through morphological analysis, and final single eojeol-sequence selection by linguistic evaluation. All the required linguistic information and probabilities are automatically acquired from a statistical corpus analysis. Experimental results demonstrate the effectiveness of our method, yielding error correction rate of 80.46%, and improved recognition rate of 95.53% from before-post-processing rate 71.2% for single best-solution selection.
Integrated speech and morphological processing in a connectionist continuous speech understanding for Korean
Mar 18, 1996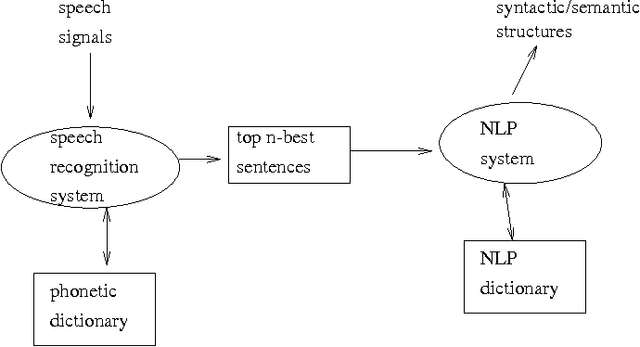
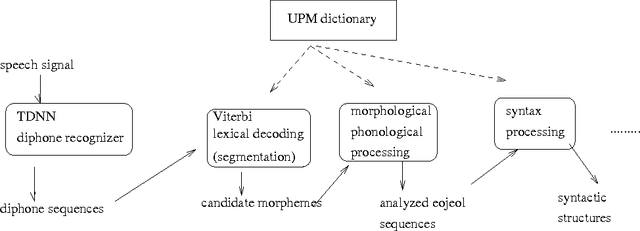


A new tightly coupled speech and natural language integration model is presented for a TDNN-based continuous possibly large vocabulary speech recognition system for Korean. Unlike popular n-best techniques developed for integrating mainly HMM-based speech recognition and natural language processing in a {\em word level}, which is obviously inadequate for morphologically complex agglutinative languages, our model constructs a spoken language system based on a {\em morpheme-level} speech and language integration. With this integration scheme, the spoken Korean processing engine (SKOPE) is designed and implemented using a TDNN-based diphone recognition module integrated with a Viterbi-based lexical decoding and symbolic phonological/morphological co-analysis. Our experiment results show that the speaker-dependent continuous {\em eojeol} (Korean word) recognition and integrated morphological analysis can be achieved with over 80.6% success rate directly from speech inputs for the middle-level vocabularies.
Chart-driven Connectionist Categorial Parsing of Spoken Korean
Nov 29, 1995

While most of the speech and natural language systems which were developed for English and other Indo-European languages neglect the morphological processing and integrate speech and natural language at the word level, for the agglutinative languages such as Korean and Japanese, the morphological processing plays a major role in the language processing since these languages have very complex morphological phenomena and relatively simple syntactic functionality. Obviously degenerated morphological processing limits the usable vocabulary size for the system and word-level dictionary results in exponential explosion in the number of dictionary entries. For the agglutinative languages, we need sub-word level integration which leaves rooms for general morphological processing. In this paper, we developed a phoneme-level integration model of speech and linguistic processings through general morphological analysis for agglutinative languages and a efficient parsing scheme for that integration. Korean is modeled lexically based on the categorial grammar formalism with unordered argument and suppressed category extensions, and chart-driven connectionist parsing method is introduced.
TAKTAG: Two-phase learning method for hybrid statistical/rule-based part-of-speech disambiguation
May 28, 1995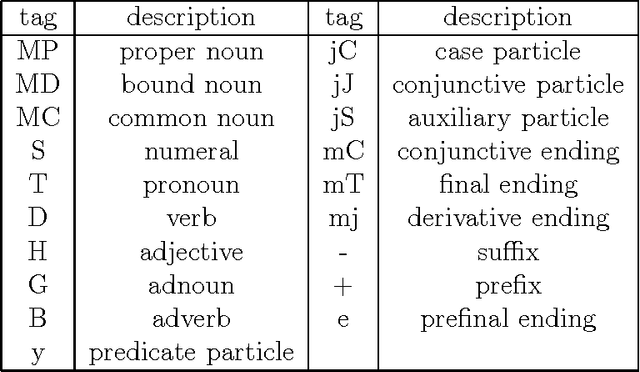



Both statistical and rule-based approaches to part-of-speech (POS) disambiguation have their own advantages and limitations. Especially for Korean, the narrow windows provided by hidden markov model (HMM) cannot cover the necessary lexical and long-distance dependencies for POS disambiguation. On the other hand, the rule-based approaches are not accurate and flexible to new tag-sets and languages. In this regard, the statistical/rule-based hybrid method that can take advantages of both approaches is called for the robust and flexible POS disambiguation. We present one of such method, that is, a two-phase learning architecture for the hybrid statistical/rule-based POS disambiguation, especially for Korean. In this method, the statistical learning of morphological tagging is error-corrected by the rule-based learning of Brill [1992] style tagger. We also design the hierarchical and flexible Korean tag-set to cope with the multiple tagging applications, each of which requires different tag-set. Our experiments show that the two-phase learning method can overcome the undesirable features of solely HMM-based or solely rule-based tagging, especially for morphologically complex Korean.
SKOPE: A connectionist/symbolic architecture of spoken Korean processing
Apr 25, 1995

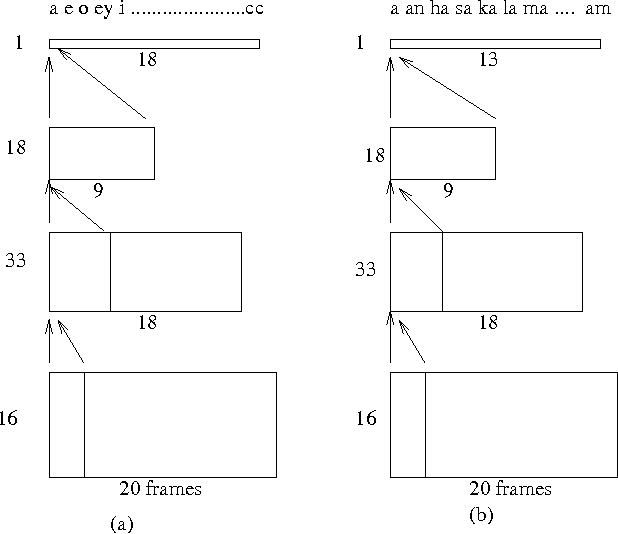
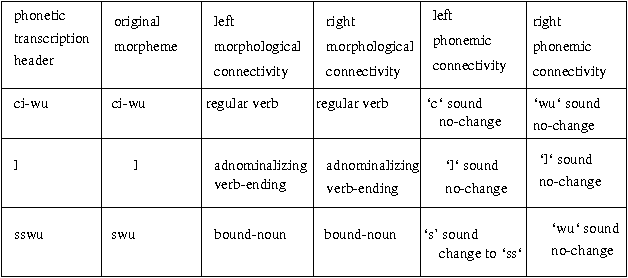
Spoken language processing requires speech and natural language integration. Moreover, spoken Korean calls for unique processing methodology due to its linguistic characteristics. This paper presents SKOPE, a connectionist/symbolic spoken Korean processing engine, which emphasizes that: 1) connectionist and symbolic techniques must be selectively applied according to their relative strength and weakness, and 2) the linguistic characteristics of Korean must be fully considered for phoneme recognition, speech and language integration, and morphological/syntactic processing. The design and implementation of SKOPE demonstrates how connectionist/symbolic hybrid architectures can be constructed for spoken agglutinative language processing. Also SKOPE presents many novel ideas for speech and language processing. The phoneme recognition, morphological analysis, and syntactic analysis experiments show that SKOPE is a viable approach for the spoken Korean processing.
Bi-directional memory-based dialog translation: The KEMDT approach
Feb 23, 1995A bi-directional Korean/English dialog translation system is designed and implemented using the memory-based translation technique. The system KEMDT (Korean/English Memory-based Dialog Translation system) can perform Korean to English, and English to Korean translation using unified memory network and extended marker passing algorithm. We resolve the word order variation and frequent word omission problems in Korean by classifying the concept sequence element in four different types and extending the marker- passing-based-translation algorithm. Unlike the previous memory-based translation systems, the KEMDT system develops the bilingual memory network and the unified bi-directional marker passing translation algorithm. For efficient language specific processing, we separate the morphological processors from the memory-based translator. The KEMDT technology provides a hierarchical memory network and an efficient marker-based control for the recent example-based MT paradigm.